サービス開発部Backlog課の@vvatanabeです。今年の4月にSRE課からBacklog課へ異動しました。よりプロダクトにコミットしていく機運の高まりを感じています。
今回は、Backlogが提供するGitホスティングにおいて、可用性・信頼性を保つためにどのように冗長化と負荷分散を実現しているのか、その仕組みについて解説します。
※ 本記事はNuCon mini 2022 Springで発表した内容をブログ化したものです。
目次
取り扱うデータの特性
初めに、Gitホスティングで取り扱うデータの特性について解説します。
リポジトリという単位のオブジェクトデータベース
Gitホスティングではベアリポジトリと呼ばれるリポジトリを取り扱います。ベアリポジトリとはワークツリーを持たないリポジトリです。具体的には、ローカルマシンに git clone して使っているリポジトリ内の、 .git ディレクトリ以下の階層だけを持つリポジトリです。
以下の図のようなツリー構造で、
- リポジトリのconfig
- Hookスクリプト
- タグやブランチの参照を記したファイル
- Gitオブジェクトと呼ばれる、tree、blob、commit、tagのファイル
- Gitオブジェクトや参照を圧縮したファイル
と言ったものが階層的に管理されてます。
このリポジトリ単位で独立したオブジェクトデータベースを、それぞれサーバーのストレージに保持しています。
システム設計上の留意事項
次に、冗長化と負荷分散を行うにあたって、システム設計上留意する必要がある要素について解説します。
ストレージとパフォーマンス
ストレージといっても世の中には様々なストレージがあります。ここでは代表的なものをいくつか引き合いに出して解説します。
NFS、Amazon EFSのようなファイルストレージ
NFSのようなファイルストレージは複数のサーバーからマウントできるので、単純にサーバーを増やしやすいです。AWSが提供するフルマネージドなNFSサーバのAmazon EFSなら、耐障害性も高く非常に使いやすいと思います。
しかし、Gitの特性としてリポジトリの状態(コミットの量やサイズ)によって、CPUやディスクIOが跳ね上がることが多々あります。そのためブロックストレージと比較すると10倍程度遅くなる場合もあります。Gitホスティングでは安定したパフォーマンスを保ったまま使用するのはなかなか難しいです。
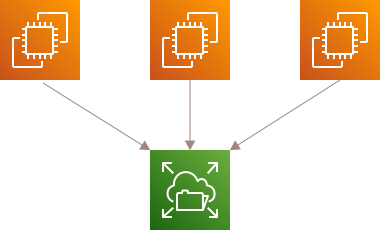
Amazon S3のような外部のオブジェクトストレージ
次に、AWSのS3に代表される外部のオブジェクトストレージです。s3fs等のFUSEを介してS3バケットをファイルシステムとしてマウントさせるツールが必要になります。
Gitオブジェクトや参照は git push や git fetch で大量に送受信されることも多々あります。読み書きするファイルの量と比例して線形に通信コストも増えやすく、ファイルストレージと同じくパフォーマンス面がボトルネックとなります。
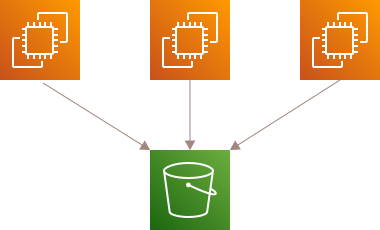
Amazon EBSのようなブロックストレージ
最後に、サーバーに直接マウントするブロックストレージです。AWSだとAmazon EBSが挙げられます。安定したパフォーマンスを考慮するとこれが最適です。
しかし、一般的にブロックストレージは複数のホストから同じ領域へ安全に書き込みできません。そのため、複数のサーバーから取り扱うには物理的に異なるストレージへ複製(レプリケーション)が必要です。
ストレージ間のデータの複製と整合性
GitそのものはMySQLやPostgreSQLといったRDBが持つレプリケーション機能は提供してません。そのため、物理的に異なるストレージ間でリアルタイムにデータを複製する安全な仕組みを作る必要があります。複製時に予期しないエラーが発生した時など、Gitリポジトリとしての整合性を崩さないようにしなければなりません。

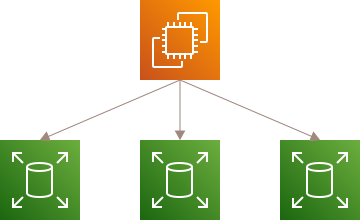
状態に応じた動的なプロキシ
Gitリポジトリを一定の集合で異なるストレージへ分割して負荷分散する、データベースの負荷分散のアプローチとして挙げられるシャーディングのようなイメージです。処理対象のリポジトリを持つホストサーバーを動的に解決して振り分ける仕組みが必要になります。
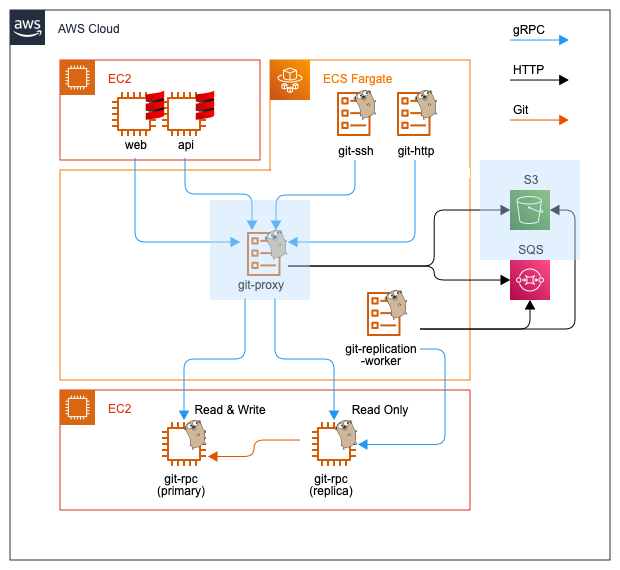
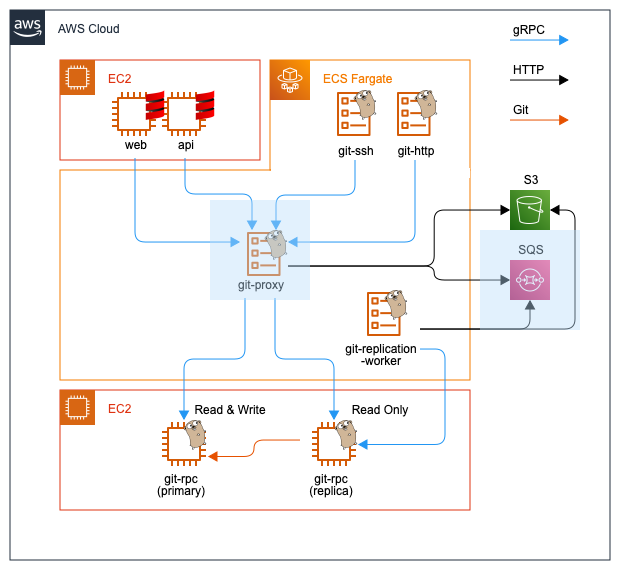
アーキテクチャの外観
以下の図はBacklogのシステム全体からGitホスティング機能を中心に切り出したアーキテクチャの外観です。
※ここでは図を簡素化するために、アベイラビリティゾーン、VPC、サブネット、ロードバランサーなどは省略しています。実際は各コンポーネントを複数のアベイラビリティゾーンに配備しています。
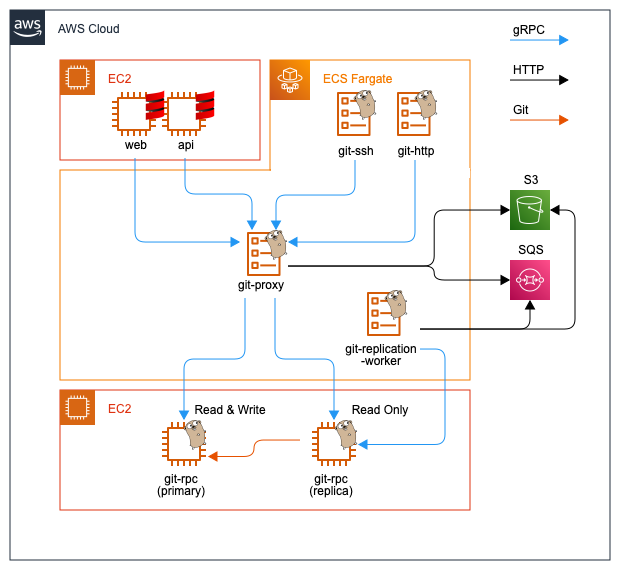
ステートレスなフロントエンド
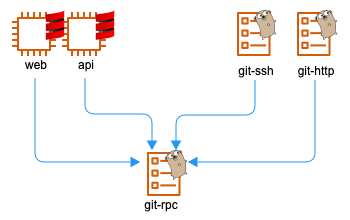
BacklogのGitホスティングのリクエストは大きく4つに分類され、処理を担当するコンポーネントも分かれています。
- Webブラウザからのリクエスト
- Backlog APIからのリクエスト
- GitクライアントからのHTTPSリクエスト
- GitクライアントからのSSHリクエスト
図のシステムの前段に配備される上記のコンポーネントは、ストレージを持ちません(ステートレス)。リクエストの特性に合わせた認証・認可を行い、後段のコンポーネントにRPCで接続してデータの読み書きを行います。
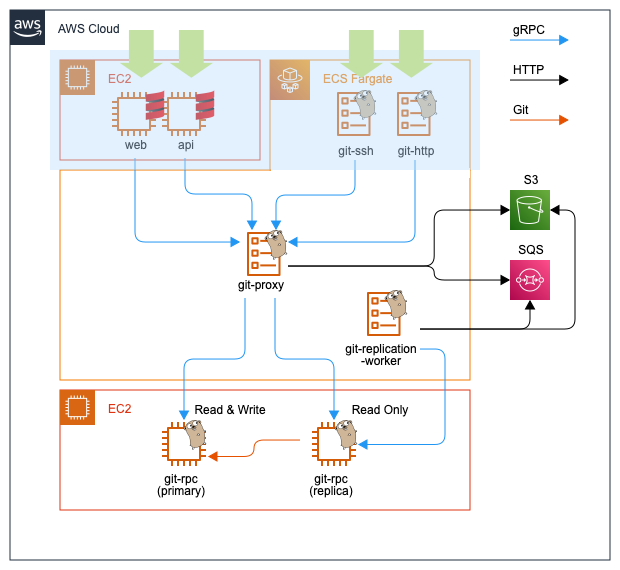
ステートフルなバックエンド
図のシステムの後段に配備されるコンポーネントのgit-rpcのみストレージを持ちます。フロントエンドからのRPCを受け取りGitリポジトリへ読み書きを行います。Gitリポジトリの読み書きに特化したデータベースミドルウェアのようなものです。EC2上で稼働しておりEBSをマウントしています。
Active/ActiveなPrimary/Replica構成となっており、ReplicaはPrimaryを正とした複製です。Write系のRPCは全てPrimaryで、Read系のRPCはPrimaryかReplicaのどちらかで処理します。
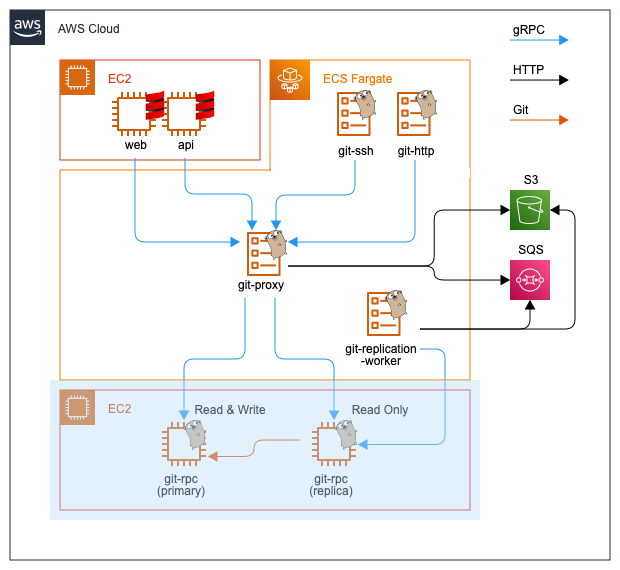
フロントエンドとバックエンドを繋ぐプロキシ
図の中央に配備されているgit-proxyはフロントエンドからの全てのRPCを受け取りバックエンドへ中継します。レプリケーションにおいて中心となるコンポーネントです。詳細は後述します。
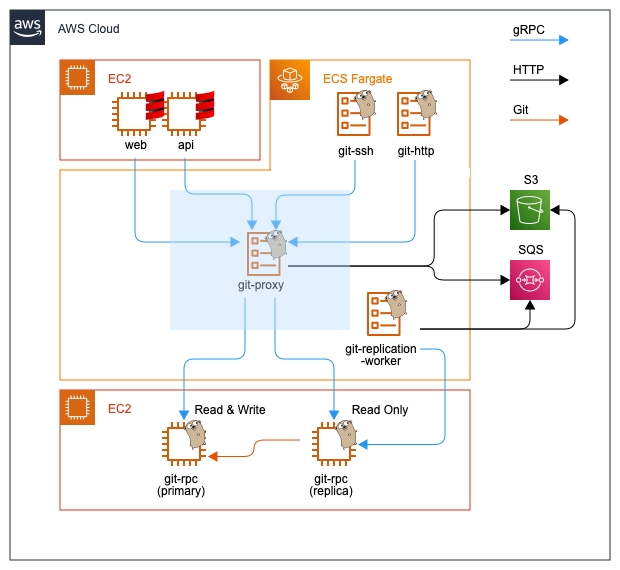
gRPCを用いたサービス間通信
全てのコンポーネントはgRPCで通信しています。gRPCで繋ぐ一番の理由はGit特有の多様な通信の特性にあります。gRPCは4種類の通信方式をサポートしており、それらはGitのワークロードを効率化するのに非常に適しています。以下はその例です。
大容量データの読み込み
git clone、git pull、git fetch、 ファイルのダウンロードが挙げられます。サーバーが一度に送信するデータを抑えるために複数のレスポンスに分割する場合は、 gRPCのServer Streaming RPCが適しています。
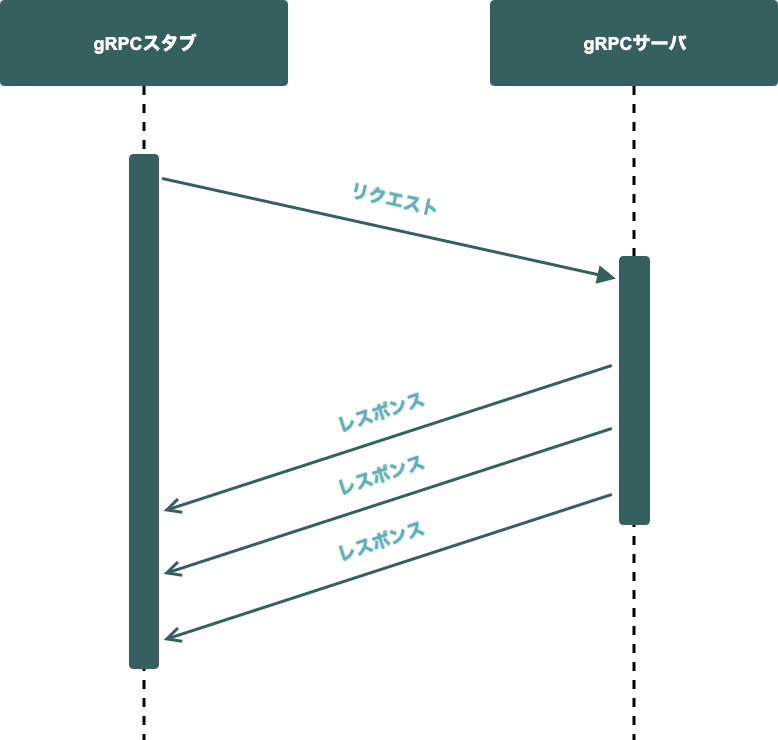
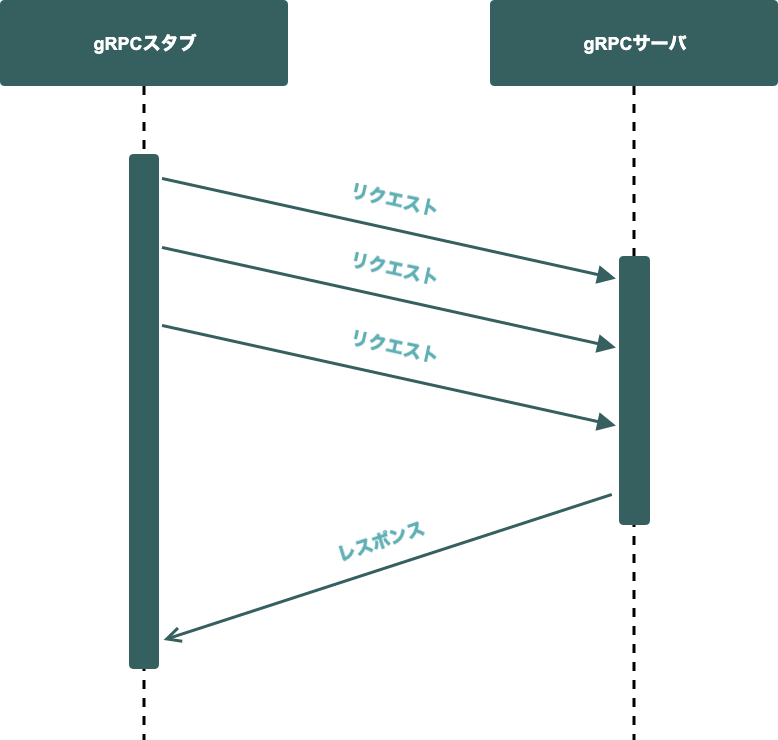
大容量データの書き込み
git push が挙げられます。サーバーが一度に受信するデータを抑えるために複数のリクエストに分割する場合は、gRPCのClient Streaming RPCが適しています。
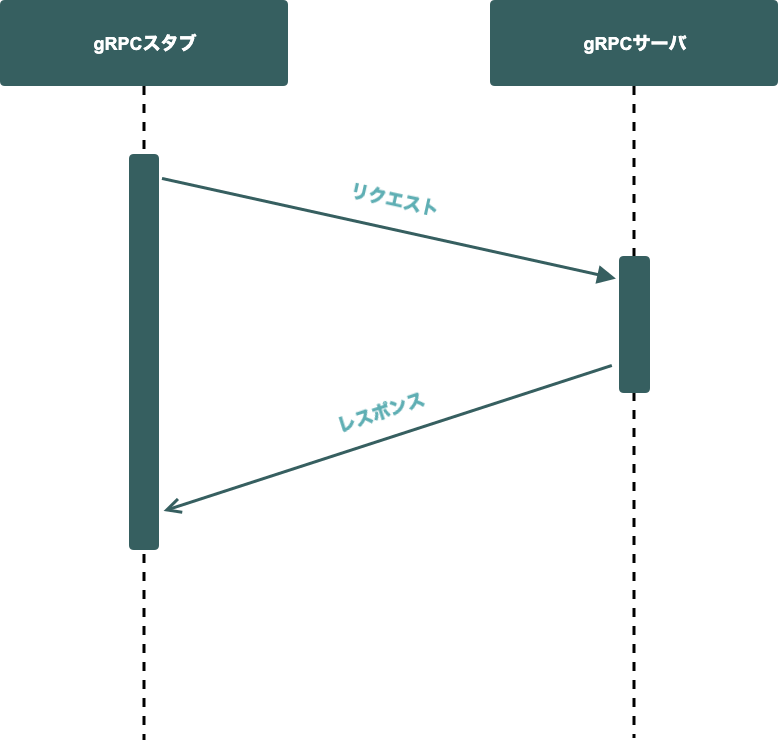
その他小さなデータのやり取り
コミット、ブランチ、タグ等の比較的小さなデータの取得が挙げられます。リクエストやレスポンスを分割する必要がない場合は、gRPCのUnary RPCが適しています。
レプリケーションの仕組み
BacklogのGitホスティングでは、俗に言う非同期レプリケーションと呼ばれる方式でリポジトリを複製しています。ここでは、その非同期レプリケーションの流れを関連するコンポーネントに焦点を当てて解説します。
Amazon S3に保持するレプリケーションログ
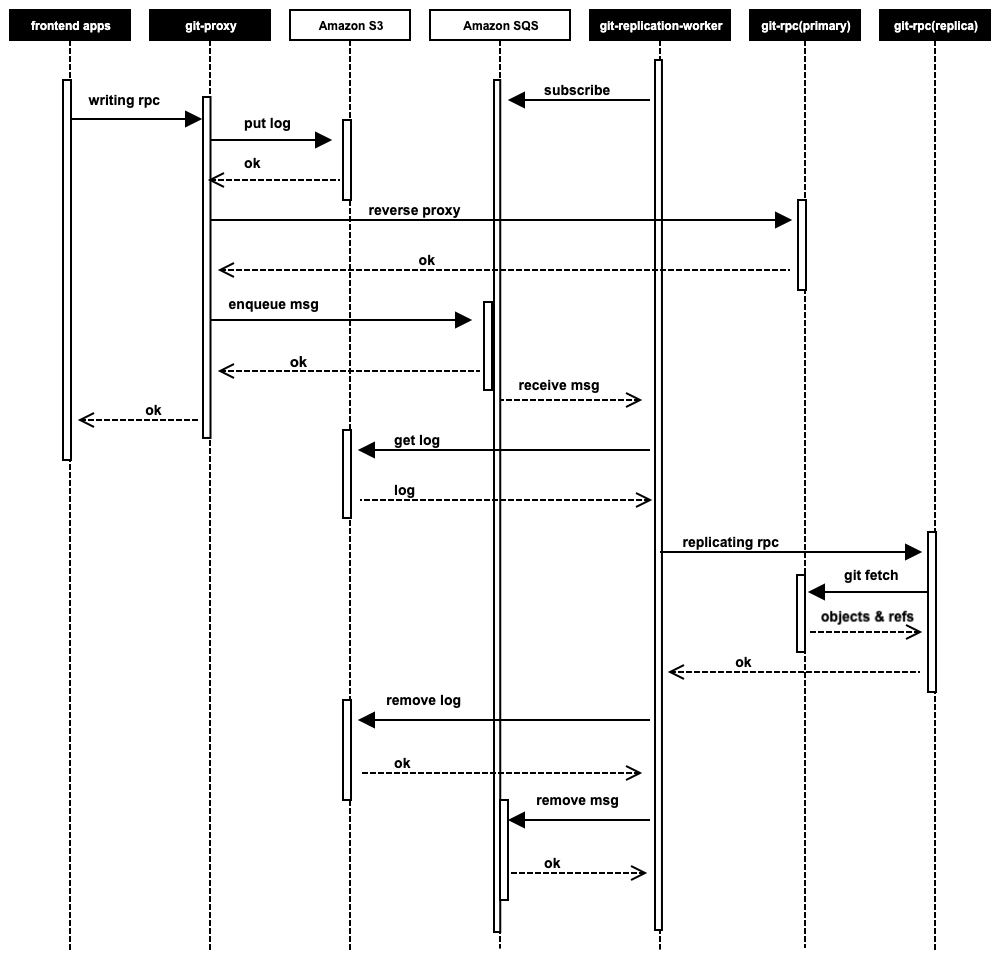
git-proxyは書き込み処理を中継する直前に、リポジトリを複製するために必要な情報を記述したログ(以下、レプリケーションログ)をAmazon S3へ送信します。このレプリケーションログは、冗長化した複数のgit-proxyや、後述するgit-replication-workerからも参照します。そのため、Amazon S3へ保存した直後やデータの変更を行った直後に別のアプリケーションからそのデータにアクセスしても、常に最新の状態を取得できる必要があります。
Amazon S3はStrong Consistency(強い一貫性)をサポートしており、この要件を満たしているので、一連のレプリケーションプロセスを円滑に実施できます。
git-proxyはgit pushなどの書き込み処理を中継した後、処理が成功した場合は対象のレプリケーションログのユニークなキーを含んだメッセージをAmazon SQSに送信します。
もし書き込み処理が失敗した場合は、不要になったAmazon S3上のレプリケーションログを削除します。
Amazon SQSのFIFO・グループ化を用いた配信順序の担保
レプリケーションログはリポジトリ単位で発行されるもので、そのログの種類は書き込みの特性に応じて複数のイベントに分類されます。
その際、注意点として下の例のようにレプリケーションの実行順序を守る必要があります。
例)
- リポジトリの作成
- リポジトリへの書き込み
- リポジトリのリネーム
- リポジトリの削除
これに関しては、Amazon SQSのFIFOキューがもつメッセージのグループ化機能がとても役に立ちました。同じキュー内でも、エンキューするメッセージにグループIDを付与することで、同一グループIDのメッセージの配信順序が保証されます。
コンシューマーによるレプリケーションの制御
git-replication-workerはAmazon SQSをポーリングしているコンシューマー(ワーカー)です。
AWS SDK for Goをベースにして実装しており、Goの強みでもあるgoroutineとchannelを使い同時処理数を制御しています。
git-replication-worker自体もECS Fargateで冗長化されていますが、単独のECSタスクで複数のメッセージを同時に捌けるようになっています。
取得したメッセージに含まれるレプリケーションログのキーを元にAmazon S3上のレプリケーションログの実態を取得します。
レプリケーションログに記載されているGitリポジトリの情報やレプリケーションの種別を元に、gRPCでgit-rpcのレプリカに対してレプリケーション用の適切なRPCを実行します。
レプリケーション用のRPCが成功した場合は、Amazon S3のレプリケーションログとAmazon SQSのメッセージを削除します。失敗した場合はリトライします。
冪等性を担保したレプリケーションRPC
git-rpcが提供するレプリケーション用のRPCは、レプリケーションの種別毎に提供しています。
それらは全てリトライされることを想定しており、何度実行されても問題ないように冪等な作りになっています。
例えば、
- リポジトリのBlob、Commit、TreeなどのGitオブジェクト
- ブランチ、タグ、プルリクエストなどの参照
を複製するRPCは、Gitのサブコマンドの git fetch をReplicaからPrimaryに対して実行しています。
git fetch のトランザクションにより予期しないエラー発生時もデータの一貫性を担保しています。git fetch 自体が冪等なので複数回実行しても差分のみ処理できるということです。
レプリケーションのシーケンス
以下の図はここまでで解説したレプリケーションの流れをまとめたシーケンスです。
複製と分散の中核となるリバースプロキシ
ここまで解説したとおり、Gitホスティングの複製と分散において中心となるのはgit-proxyです。
動的なリバースプロキシの制御
git-proxyはgRPCの公式の実装の一つであるgrpc-goをベースにスクラッチで実装したL7のリバースプロキシです。特有の様々な処理をGoの標準APIや各種公式ライブラリに頼りながら実装しており、Goの豊富なエコシステムの恩恵を享受しています。
具体的な処理の例としては、
- 対象のリポジトリの複製が完了しているかどうか判定するためにAmazon S3のレプリケーションログを検索
- レプリケーションを通知するためにAmazon SQSへメッセージを送信
- リクエストの属性を判定するためにProtocol Buffersのカスタムオプションに記述したRPC毎の属性情報の読み取り
- 特定のリポジトリグループごとに振り分け先のクラスタ(primaryとreplicaの集合)を指定するカスタムルーティング
などが挙げられます。
場面に合わせて着脱可能なコンポーネント
複製と分散の機能が一つのアプリケーションに集約されているため、git-proxyそのものをシステムから着脱しやすい設計になっています。
例えばローカルマシンで開発する場合や、エンタープライズ版でスタンドアロンなサーバーにインストールする場合など、冗長化機能が必ずしも必要ないケースでも、前段のアプリケーションから後段のgit-rpcに直接接続して動作させることも可能です。
まとめ
BacklogのGitホスティングにおける冗長化と負荷分散の仕組みについて、データの特性や留意事項、実際のアーキテクチャを元にご紹介しました。
BacklogのGitホスティングでは、
- リポジトリという名のオブジェクトデータベースをブロックストレージに保持しています
- リクエストの特性に応じて処理するコンポーネントを分割しています
- ストレージを持つコンポーネントはバックエンドに集約、Active/ActiveなPrimary/Replica構成で冗長化しています
- 全てのコンポーネントはgRPCで繋がり、リクエストの特性に応じて通信方式を選択しています
- 中核となる動的なリバースプロキシが複製と分散の舵を取っています
- PrimaryとReplicaをリポジトリ単位で非同期にレプリケーションしています
今後のワークロードの変化によっては、非同期なレプリケーションから同期的なレプリケーションへ手法を変更する可能性もあります。所謂3フェーズコミットと呼ばれる分散アルゴリズムを用いて、複数のノードへ同時に書き込みを行う手法などが挙げられます。
これからも、プロダクトの成長と共に、プロダクトを支える技術も健全に成長させていきたいと考えています。
