目次
Backlog課Gitチームの@vvatanabeです。
本記事では、BacklogのGitホスティングに関連する複数のアプリケーションを横断する処理の性能劣化を受けて、ボトルネックを追跡し改善に繋げた話を紹介します。
目次
TL;DR
- 所謂「サービス分割」が進むと、その数に比例して複雑性が増し、どのアプリケーションがボトルネックなのか当たりをつけにくくなる。実際に関連するアプリケーションを1つ1つ確認するのは手間取った。
- 分散トレーシング等の仕組みでシステム全体の応答時間を俯瞰して見れると、当たりもつけやすく調査の効率化を期待できるので導入を検討していきたい。
- ボトルネックのアプリケーションに当たりをつけた後、コードレベルで問題を特定するには、できればスレッドダンプやヒープダンプを取ってアプリケーションの「現在」を深堀りしていくことが効率的と感じた。実際にメトリクスやログだけでは情報が足りない場合がある。
- ボトルネックの原因は内部のアプリケーション間の通信で使用するためにプールしているHTTPコネクションが枯渇していたことだった。
- 各種コネクションプールと呼ばれるものや、プロセス・スレッド数などの設定値は、日々変化するリクエスト数に応じて適切なのか定期的に見直す必要がある。
複数のアプリケーションを横断する処理の性能劣化
Backlogを構成するアプリケーションはMackerelやNagiosで外形監視しており、応答時間が劣化するとPagerDutyと連携してリアルタイムに通知される仕組みになっています。
このアラート通知システムについてはBacklogのSREを担当しているMuziが弊社のブログ「Backlog開発チーム自身によるオンコール対応を支えるアラート通知システム」で詳しく紹介しているので、興味がある方は是非ご覧ください。
GitリポジトリへのHTTPSリクエストの応答時間の劣化
次の画像はアラート通知システムが外形監視の結果をTypetalkに投稿した時のキャプチャです。今回の発端となったアラートは、GitリポジトリへのHTTPSリクエストの応答がタイムアウトしていることを示すものでした。

応答時間の劣化に関連する複数のアプリケーション
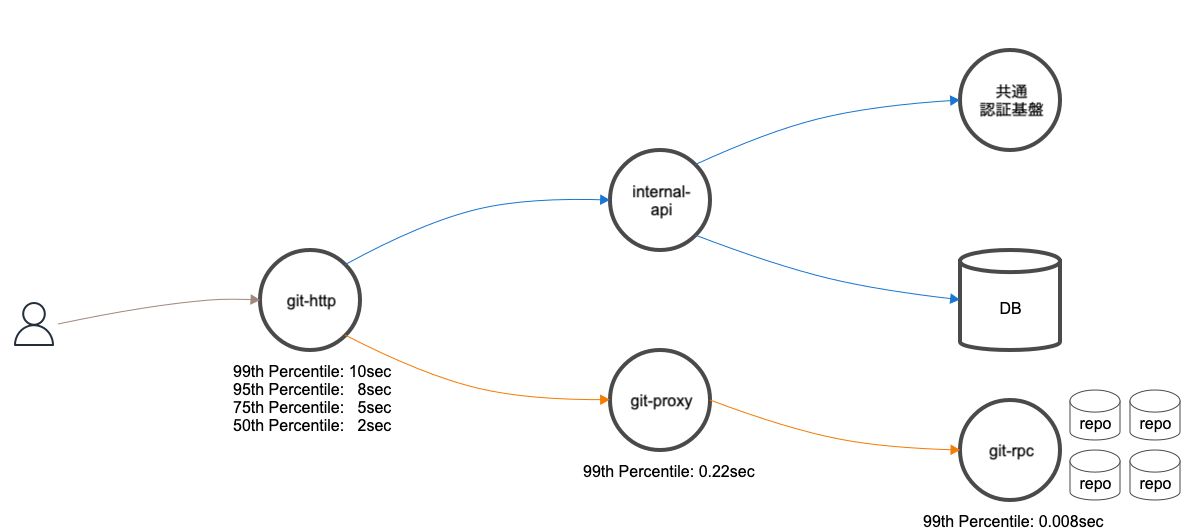
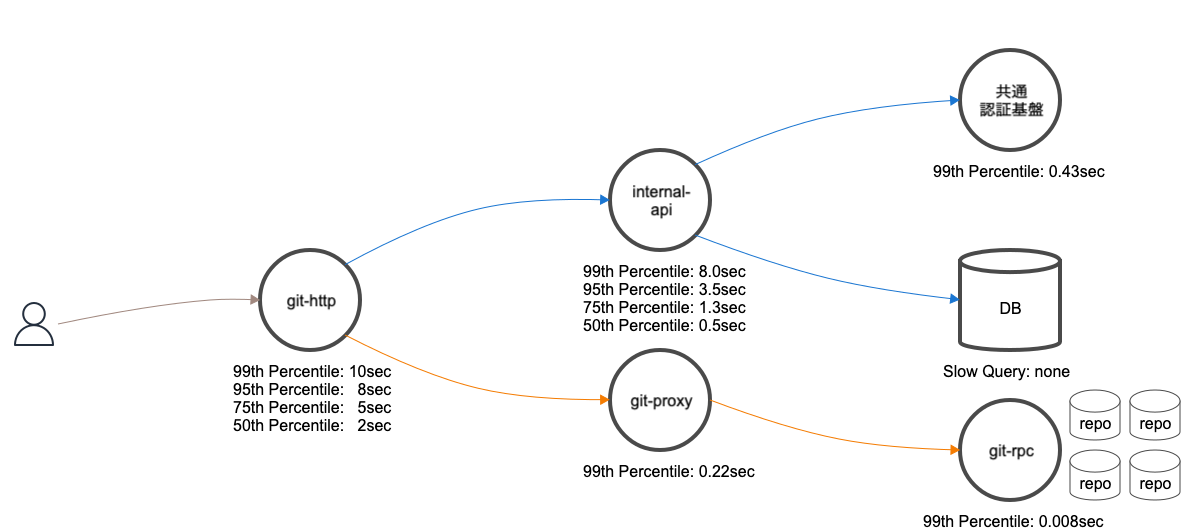
今回にアラートに関連する外形監視に設定しているURLは明確なので、実際に劣化傾向にあるリクエストの絞り込みは容易でした。次の図は、問題のリクエストとなるGitリポジトリへのHTTPSアクセスに関連するシステムの概要図です。ロードバランサーやミドルウェア等は省略しています。図を元に処理の流れを簡単に説明します。
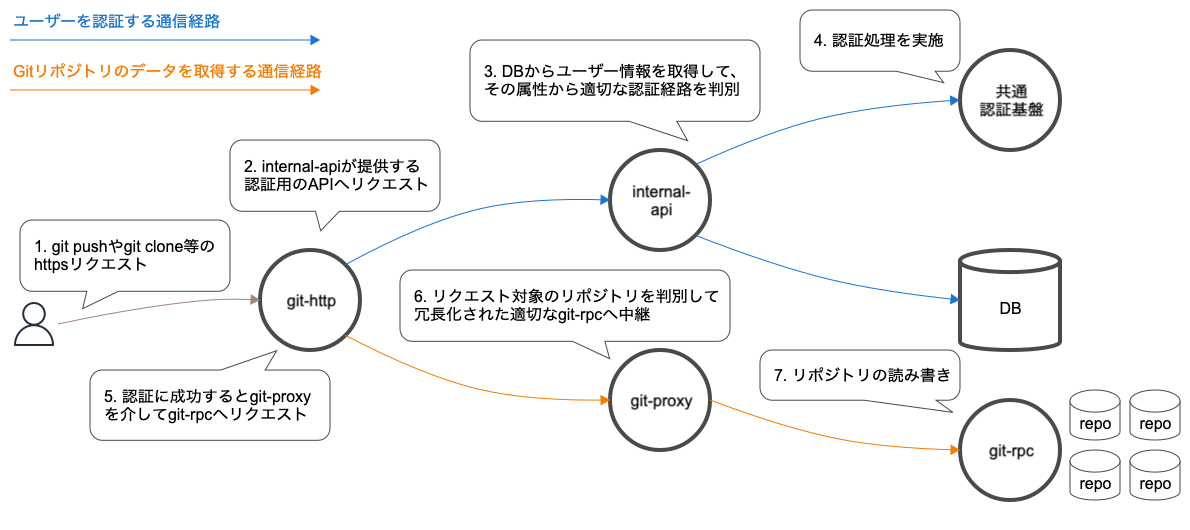
複数のアプリケーションが連携しているため、一見どの部分がボトルネックになっているのか判断しにくいです。
補足ですが、BacklogのGitホスティングについての全容は弊社のブログ「BacklogのGitホスティングにおける冗長化と負荷分散の仕組み」でも紹介しているので、興味がある方は是非ご覧ください。
ボトルネックの追跡
複数のアプリケーションが連携していますが、主な通信経路は次のとおり大きく2つに分かれます。
- ユーザーを認証する通信経路
- Gitリポジトリのデータを取得する通信経路
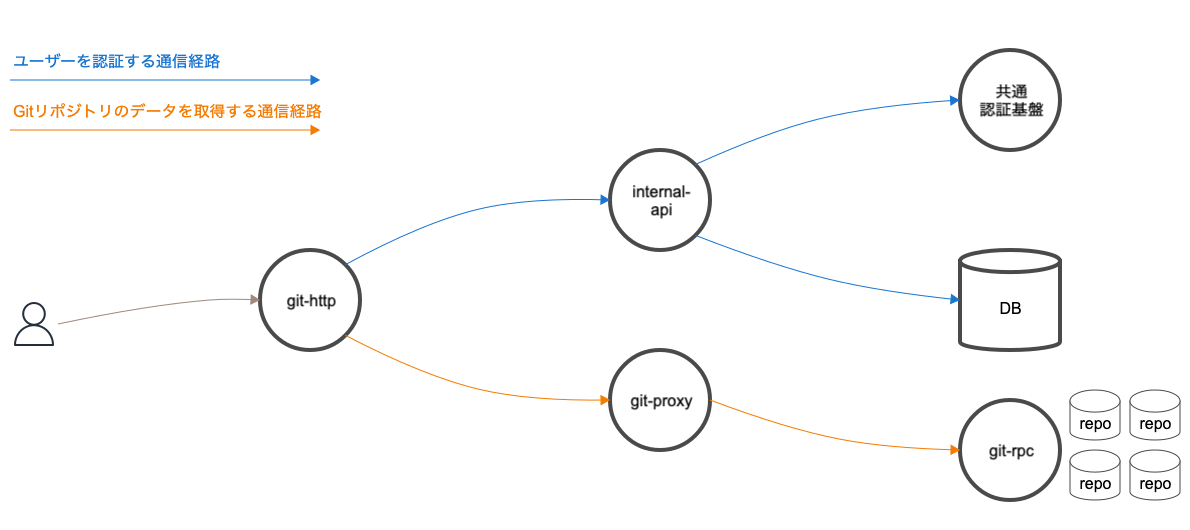
事実を一つ一つ明らかにして問題を切り分けていくために、この通信経路に関連するアプリケーションのメトリクスやログを順に調査していきました。
Gitリポジトリのデータを取得する通信経路の調査
まずは、git-http、git-proxy、git-rpcの処理の流れにボトルネックがないか調査を進めました。
git-httpの応答時間
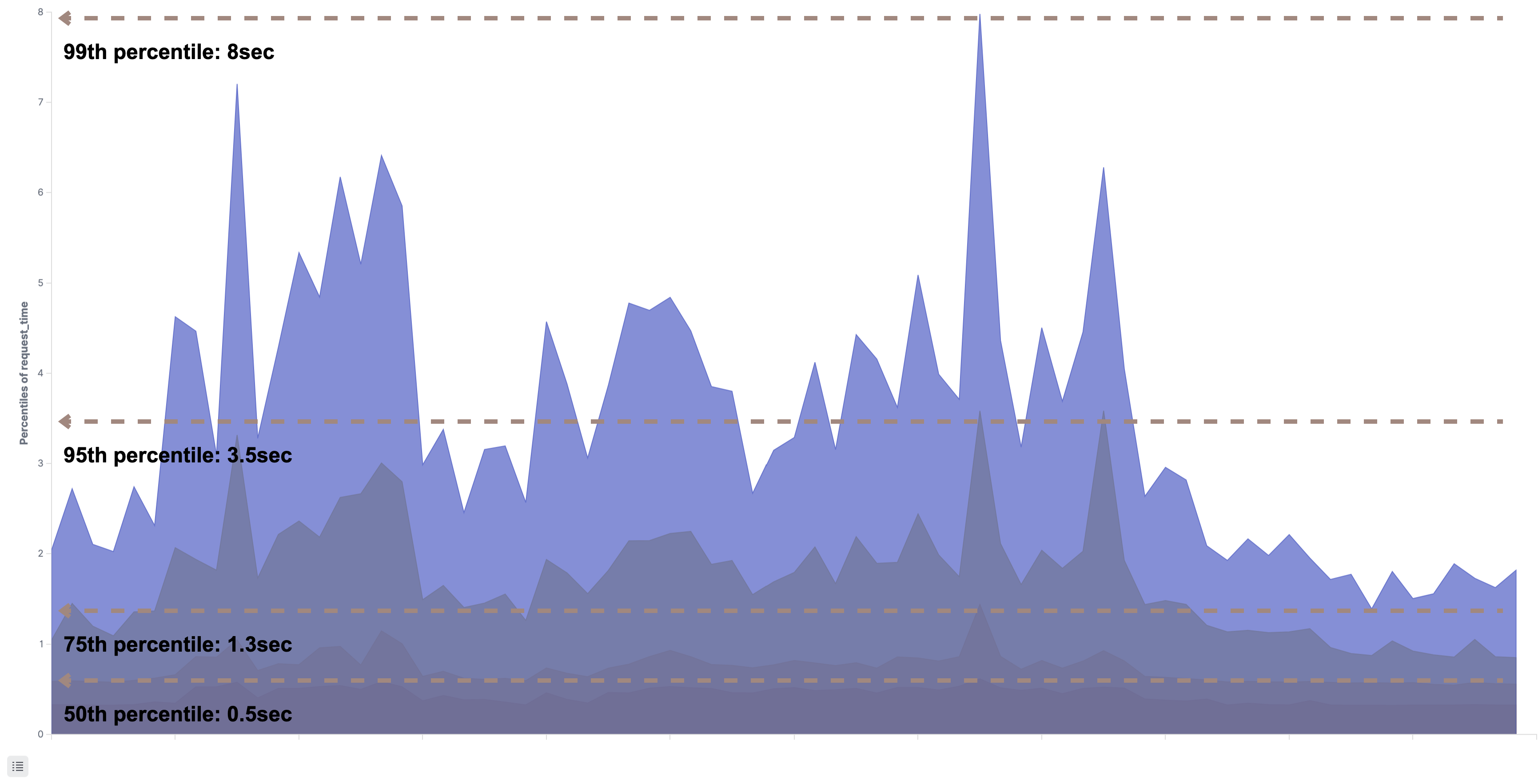
次のグラフは前段でリクエストを最初に受け取るgit-httpの応答時間をパーセンタイルで表したものです。99、95、75、50の全てのパーセンタイルで1sec以上かかっており応答時間が確実に劣化しています。
[git-http]
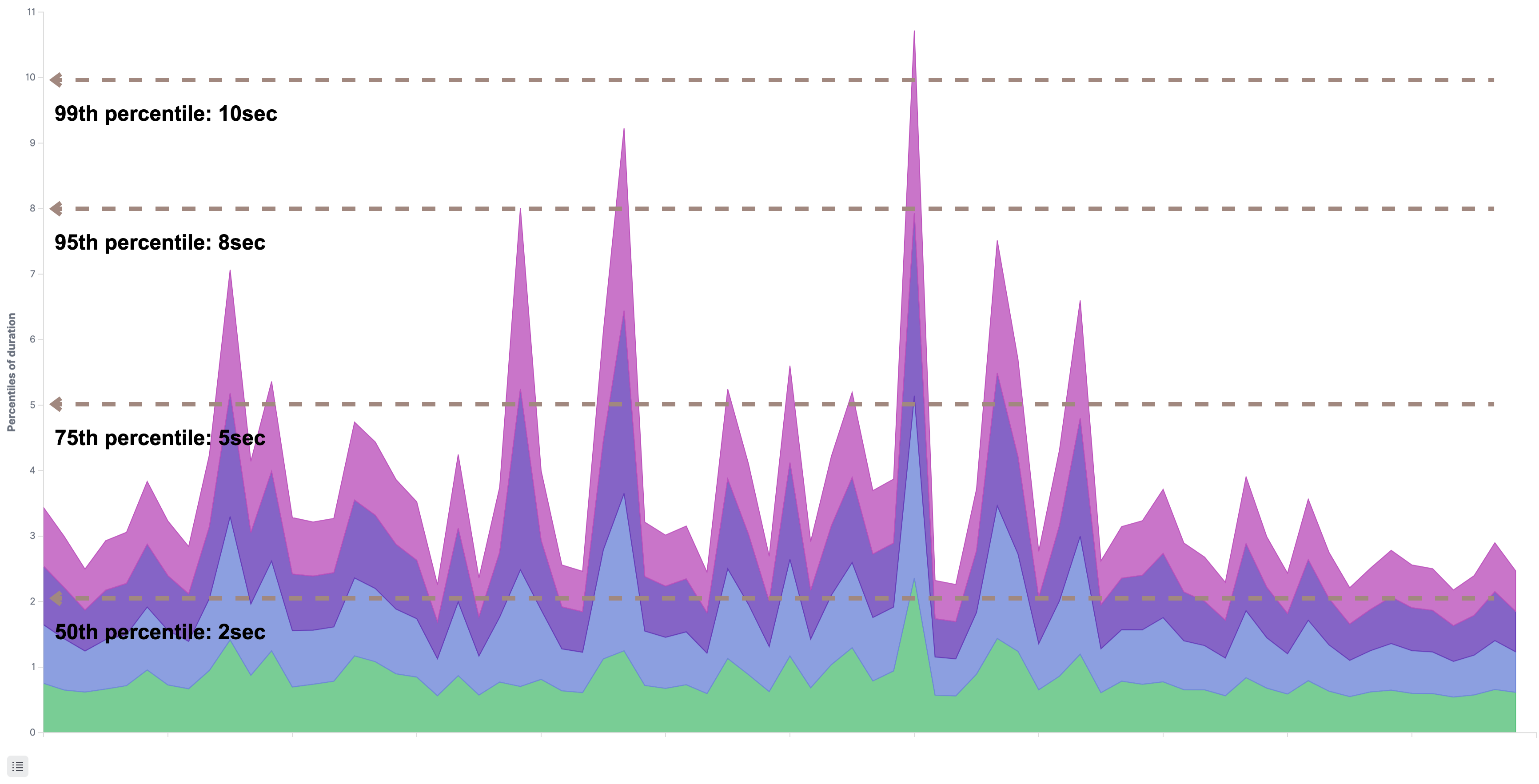
しかし、git-httpのホストのコンテナやアプリケーションのメトリクスは特に跳ねたような形跡はありませんでした。そのため、ボトルネックになりうるのは連携している他のアプリケーションへのリクエストだと推測しました。
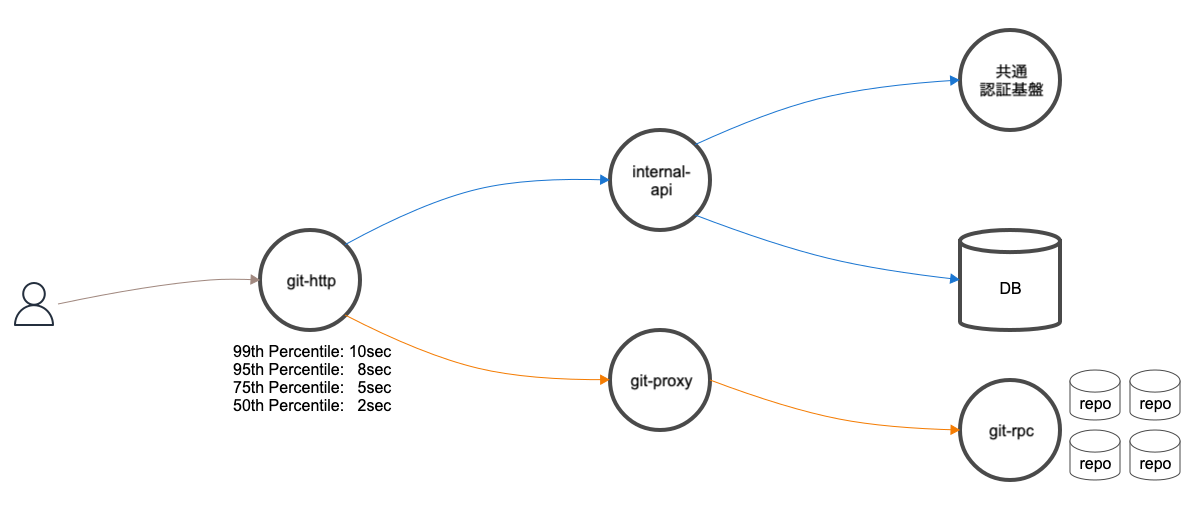
git-proxy、git-rpcの応答時間
git-httpは処理がブロックされる原因となるようなリポジトリの読み書きは行っていません。リポジトリの読み書きを行うためにgit-proxyを介してgit-rpcにgRPCで接続します。
git-rpcはgit-httpだけではなく、Backlog内の複数のアプリケーションからGitに関する読み書きのリクエストをgit-proxyを介してgRPCで受けます。様々なRPCが呼ばれているため、まずはアラートに関係するRPCを特定する必要がありました。幸い、今回のアラートとなった外形監視に紐付くリクエストは自明なので、そのリクエストから派生するRPCを特定しました。
次のグラフは、git-proxyとgit-rpcが処理する対象のRPCの応答時間をパーセンタイルで表したものです。特に劣化はなく正常に応答していました。
[git-proxy]
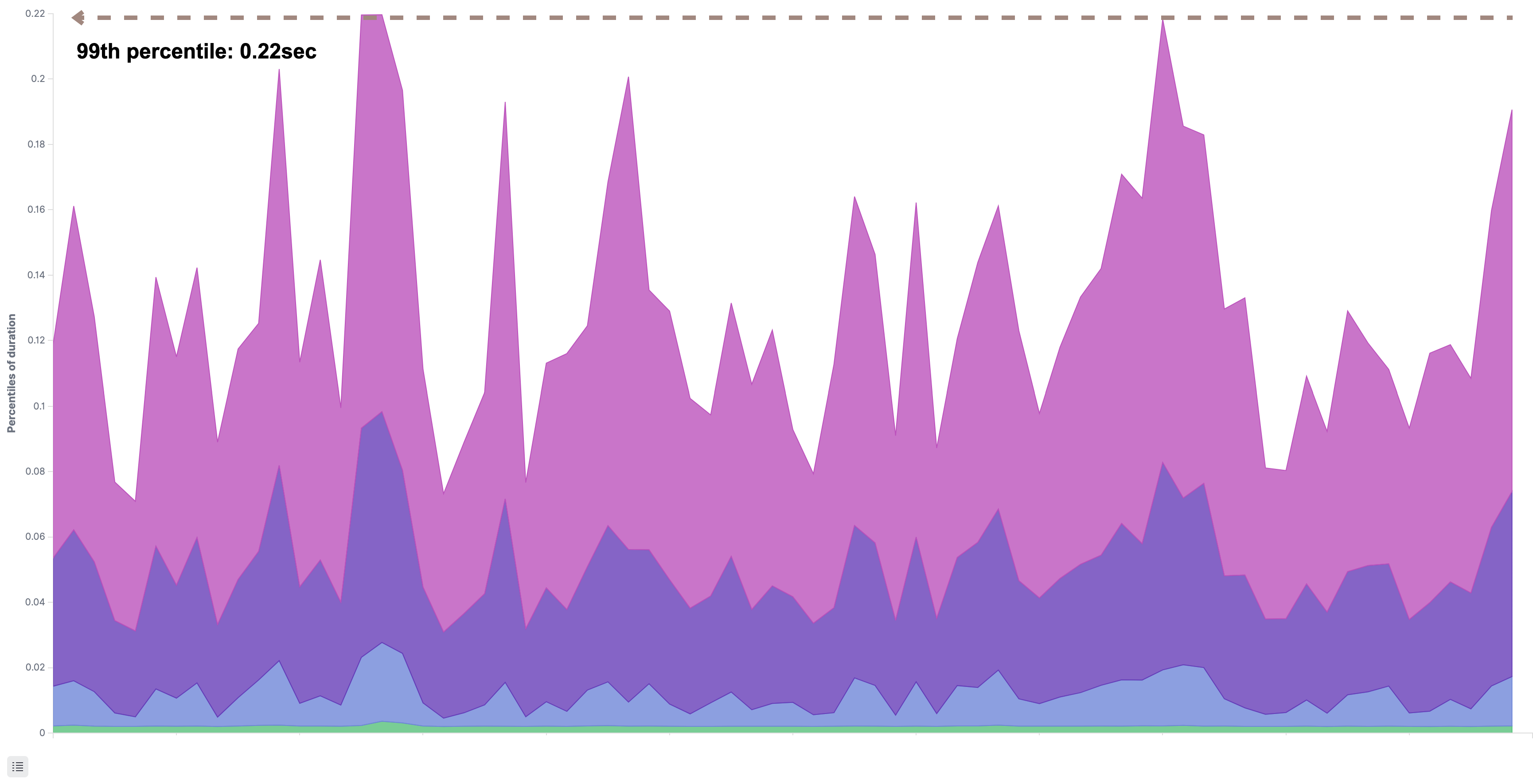
[git-rpc]
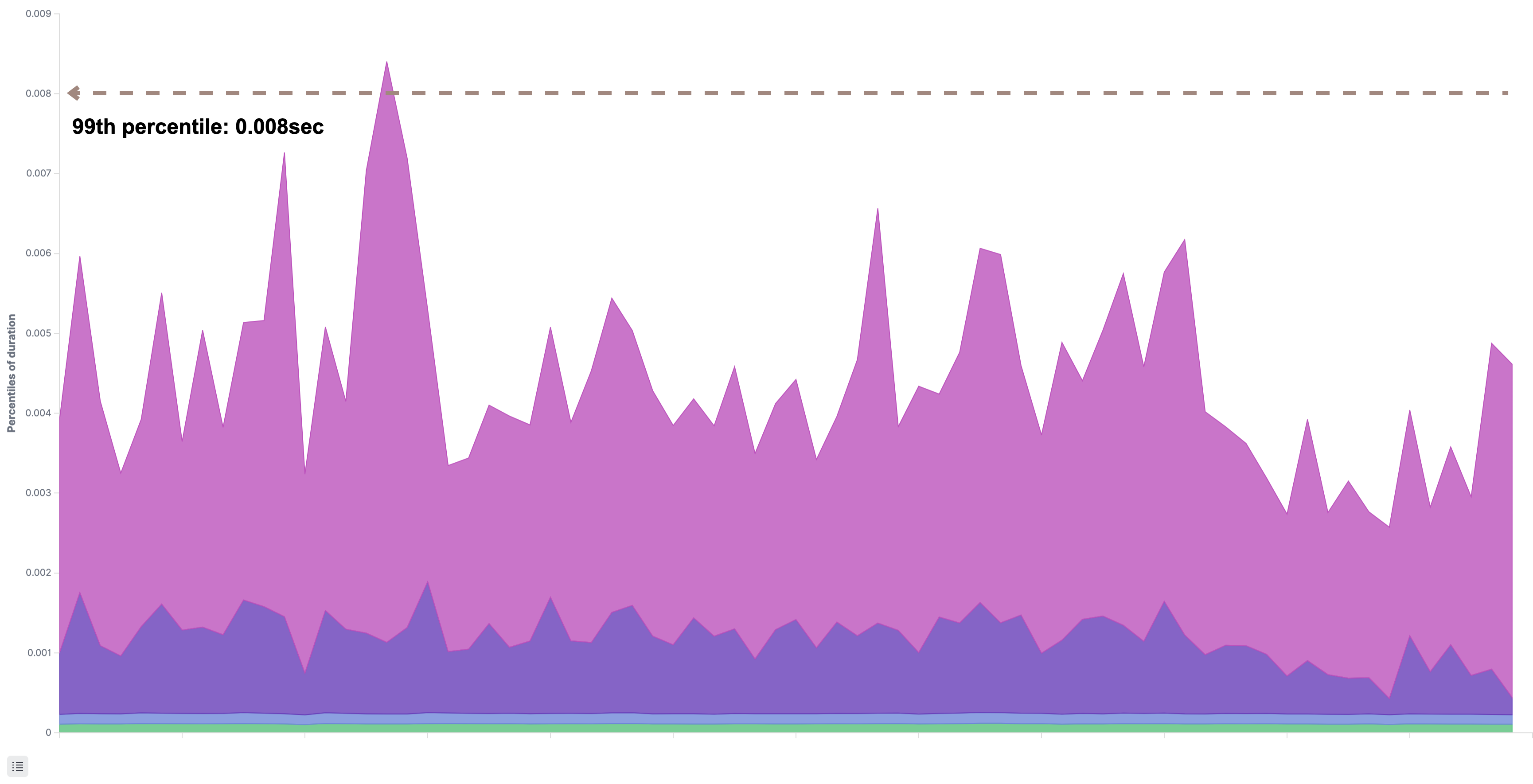
ここまでの調査で、git-httpの応答時間はGitリポジトリのデータを取得する通信経路にボトルネックはないことがわかりました。
ユーザーを認証する通信経路の調査
次に、internal-api、共通認証基盤、データベースが関わるユーザーを認証する通信経路にボトルネックがないか調査を進めました。
2つの認証経路を抽象化した認証API
Backlogを構成するアプリケーションの一つに、通称「internal-api」と呼ばれるものがあります。Scalaで実装されており、その名のとおりネットワーク内部の様々なアプリケーションからのアクセスのみ許可したインターナルなAPIを提供しています。internal-apiの応答速度が劣化すると、提供するAPIを呼び出す全てのアプリケーションの応答速度に影響します。git-httpもinternal-apiが提供する認証用のAPI(以下、認証API)を使用しています。
認証APIが存在する理由はBacklogの認証処理がユーザーの属性毎に異なる背景にあります。一つはBacklogのネットワーク内部のDBを参照して認証処理を実施して、もう一つはネットワーク外部にあるヌーラボのプロダクトが共通して使用する共通認証基盤を使用しています。internal-apiはこれら2つの認証経路の複雑性を局所化して認証処理を抽象化した認証APIを提供しています。
認証APIの応答速度
次のグラフは、このinterna-apiが提供する認証APIの応答速度です。
git-httpの応答が劣化している時間帯とほぼ同じ時間帯にinternal-apiが提供する認証APIの応答時間も劣化していることがわかりました。internal-apiがボトルネックになっているのは間違いなさそうです。併せて、internal-apiが稼働するホスト(Amazon EC2)の基本的なメトリクスとして、Load Average、CPU、Memory、送受信バイト数、TCP接続数を確認しましたが、どれを見ても異常は見られませんでした。サーバーリソースが枯渇しているわけではないようです。
認証API内で発生するネットワーク越しのIOで待たされている可能性もあります。具体的には共通認証基盤への通信とデータベースへの通信の2つです。
共通認証基盤の応答速度
今回のアラートの元となった外形監視では共通認証基盤を使用するユーザーを対象にしていました。そのため、共通認証基盤の応答時間が劣化するとinternal-apiの応答速度に影響を与えます。
次のグラフは共通認証基盤が提供するAPIの応答速度を調査した結果です。99パーセンタイルは1sec以下で応答していました。共通認証基盤はボトルネックではないようです。
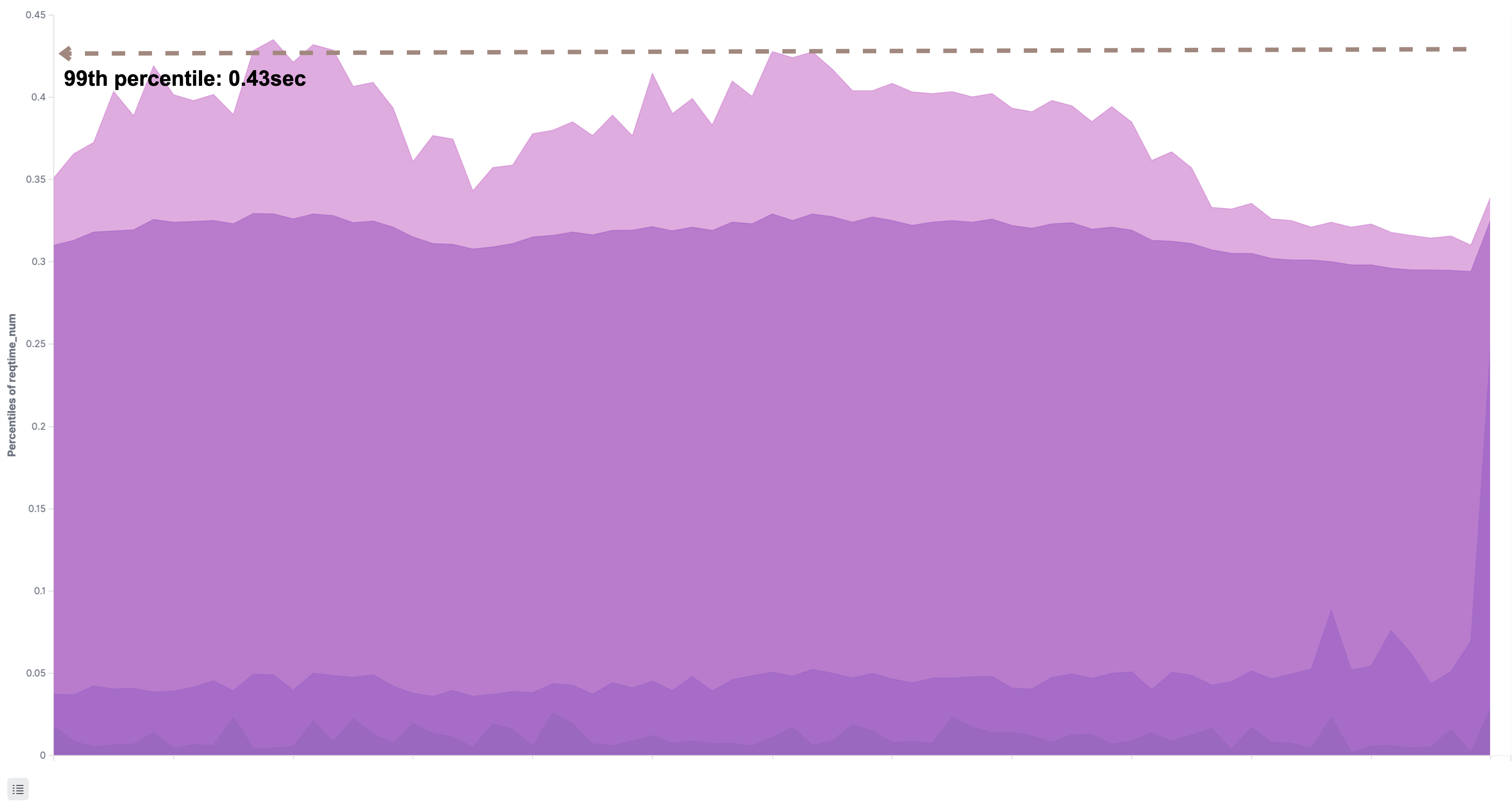
余談ですが、共通認証基盤のログもBacklog同様にAmazon OpenSearch Serviceで検索できるようになっており、共通認証基盤のチーム以外の各プロダクト(Backlog、Cacoo、Typetalk)のチームも利用できるようになっています。こういったチームを横断した問題の一次調査において、その都度他チームへ調査を依頼する必要がないのは、余計なコミュニケーションコストが発生しないので、双方において効率的だと感じています。
データベースの応答時間
BacklogではデータベースにAmazon Auroraを使用しています。このデータベースの読み書きの応答速度が劣化していないか、所謂スロークエリと呼ばれる実行が遅いクエリがないか調査しました。Backlogではスロークエリのログを専用のDBに保存しており、Redashを使って参照できるようになっています。
しかし、認証APIの処理で発行されるクエリで1sec以上かかる遅いクエリはありませんでした。念の為、Amazon RDSのメトリクスやパフォーマンスインサイトを確認するも特に目立った異常値やクエリはみられませんでした。さらに、internal-apiが持つDBのコネクションプールのメトリクスも確認しましが、こちらも余裕がある状態でした。
ここまでの調査で、internal-apiで発生するネットワーク越しのIOに時間がかかっているわけではないということがわかりました。
internal-apiの状態の深堀り
internal-api自身がボトルネックになっていることは推測できたので、internal-apiのアプリケーションの状態を深堀りして調査しました。
internal-apiはScalaで書かれており、内部で用途によってグルーピングされたスレッドプール(java.util.concurrent.ExecutorService)を複数持っています。スレッドプールのスレッドの状態は全てMackerelのカスタムメトリクスとして取得しています。認証APIで使用するスレッドプールは次の2つです。
- DBに接続するためのスレッドプール
- 共通認証基盤が提供するAPIに接続するためのスレッドプール
これらのスレッドプールのスレッドが枯渇していなかったかどうか、アプリケーションのカスタムメトリクスを確認しましたが、両方とも枯渇しているようには見えませんでした。
[DBへ接続するためのスレッドプール]
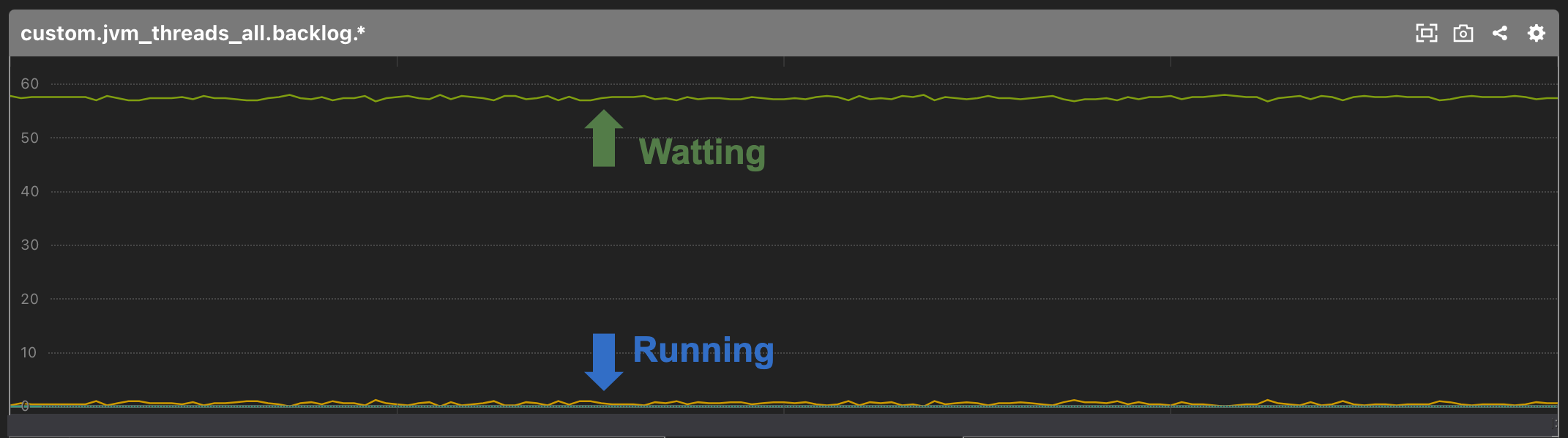
[共通認証基盤へ接続するためのスレッドプール]
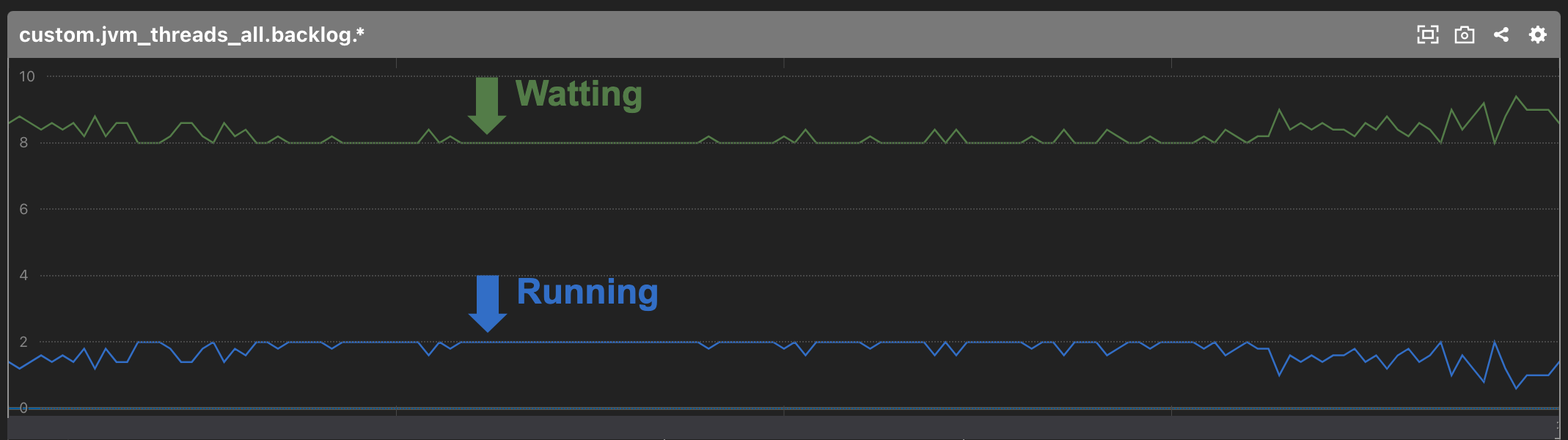
ここまで調査したところで、別のチームの谷本氏から「共通認証基盤が提供するAPIにアクセスする際に使用するHTTPクライアントのコネクション数が怪しい」と情報提供がありました。
余談ですが、彼は過去にも今回のようなパフォーマンス問題への取り組みについての記事を書いており、改めて本記事でも紹介させてください。
このHTTPクライアントのコネクションの数や状態に関してはメトリクスを取れていませんでした。そのため、実際にローカルマシンでinternal-apiの認証APIに対してロードテストを実施しながら、jcmd $PID Thread.print でスレッドダンプを取得してアプリケーションの状態を確認しました。
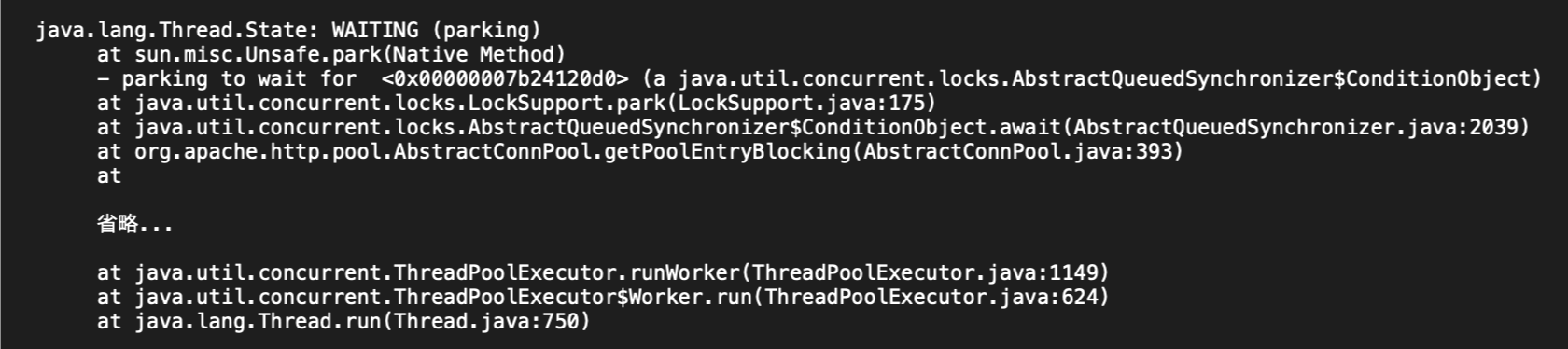
結果、共通認証基盤に接続するためのスレッドプールのスレッドのほとんどが、次の加工したスレッドダンプにあるとおり、WAITING (parking)になっていました。スタックを辿るとorg.apache.http.pool.AbstractConnPool.getPoolEntryBlockingで処理が止まっています。Apache HttpClientでプールしているコネクションが空くのを待っているように見受けられます。
[加工したスレッドタンプ]
VisualVMのTimelineビューでスレッドの状態を見ても、同時にRunningになっているスレッドが必ず2つになっていました。
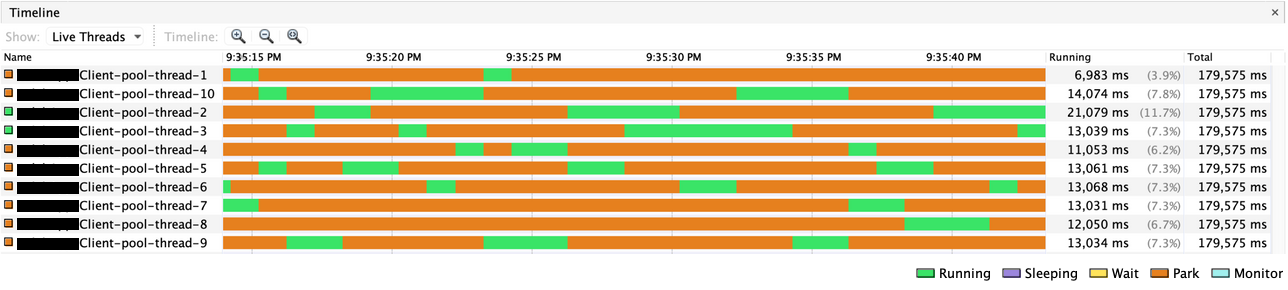 internal-apiが持つ共通認証基盤のAPIへ接続するHTTPコネクションが枯渇していることがわかりました。
internal-apiが持つ共通認証基盤のAPIへ接続するHTTPコネクションが枯渇していることがわかりました。
改善策の実施
共通認証基盤は各プロダクト(Backlog、Cacoo、Typetalk)と連携するために、プライベートなAPIとAPIへアクセスするためのJava製クライアントライブラリを提供しています。そして、ライブラリの実装には「Apache HttpClient」を使用しています。
Apache HttpClientのコネクション数を調整
調査したところ、Apache HttpClient 4系のコネクションプールはデフォルトで指定されたルート毎に最大2つ、5系では最大5つののコネクションを保持するようです。
Apache HttpClient のコードを見ると次のように設定されていました。
Apache HttpClient 5系
public static final int DEFAULT_MAX_TOTAL_CONNECTIONS = 25; public static final int DEFAULT_MAX_CONNECTIONS_PER_ROUTE = 5;
Apache HttpClient 4系
this.pool = new CPool(new InternalConnectionFactory( this.configData, connFactory), 2, 20, timeToLive, timeUnit);
PoolingHttpClientConnectionManagerのドキュメントにも次のように説明されています。
Per default this implementation will create no more than than 2 concurrent connections per given route and no more 20 connections in total.
次のスタックトレースは、実際にローカルマシンでinternal-apiの認証APIに対してロードテストしながら、jcmd $PID GC.heap_dump を実行して取得したヒープダンプを加工したものです。
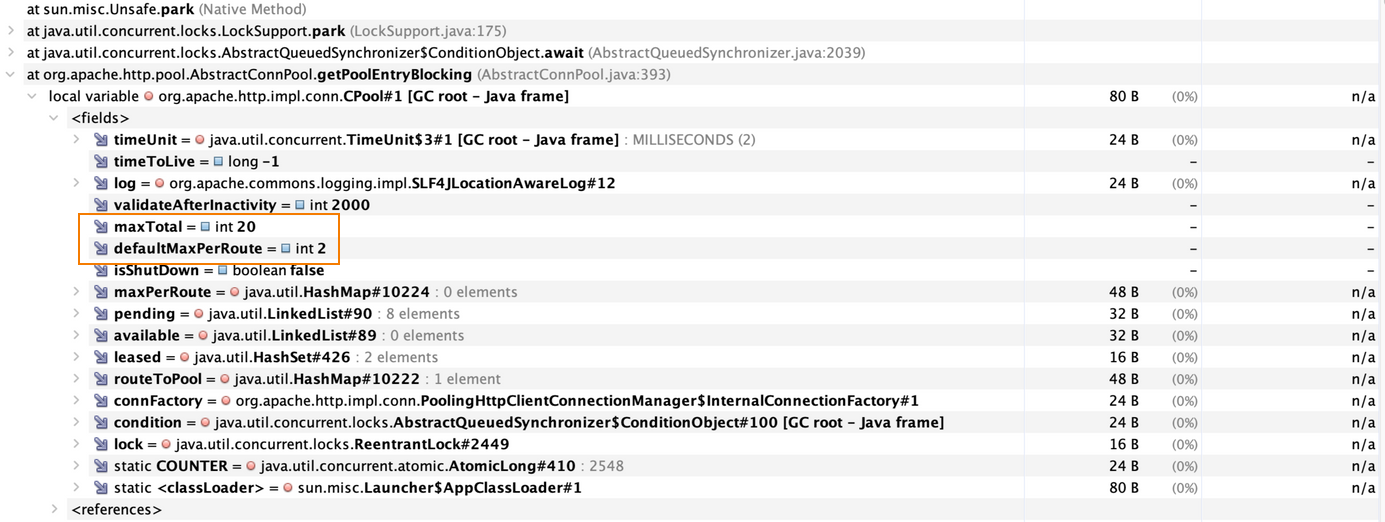
実際に、maxTotalフィールドは20、defaultMaxPerRouteは2で設定されていることがわかります。
PoolingHttpClientConnectionManagerの設定変更
次のコードはPoolingHttpClientConnectionManagerを用いた設定の例です。
val connMgr = new PoolingHttpClientConnectionManager() connMgrr.setDefaultMaxPerRoute(threadPoolSize) val clientBuilder = HttpClientBuilder.create().setConnectionManager(connMgr)
このコネクションのサイズを変更するにはPoolingHttpClientConnectionManagerのsetDefaultMaxPerRouteメソッドを使用します。引数にコネクションの数を指定するのですが、この数(threadPoolSize)は次の理由から共通認証基盤に接続するためのスレッドプールのスレッド数と同じにしました。
- コネクション数 < スレッド数 => コネクションが枯渇した際にスレッドが余る
- コネクション数 > スレッド数 => スレッドが枯渇した際にコネクションが余る
HttpClientBuilderのsetConnectionManagerメソッドにPoolingHttpClientConnectionManagerを渡すことで、コネクションの上限の変更を設定できます。
補足ですが、setMaxTotalメソッドで設定する値は、全ルートのコネクションの最大数です。setMaxTotalメソッドで大きな数を設定しても、setDefaultMaxPerRouteメソッドやsetMaxPerRouteメソッドでルート毎のコネクション数を設定しなければ、実際にプールするコネクション数は増やせません。
効果測定
詰まること無く全てRunning状態になったスレッド
VisualVMのTimelineビューでスレッドの状態を見ると、全てのスレッドがRunningになっており、HTTPコネクションの取得待ちでブロックされていないことがわかります。
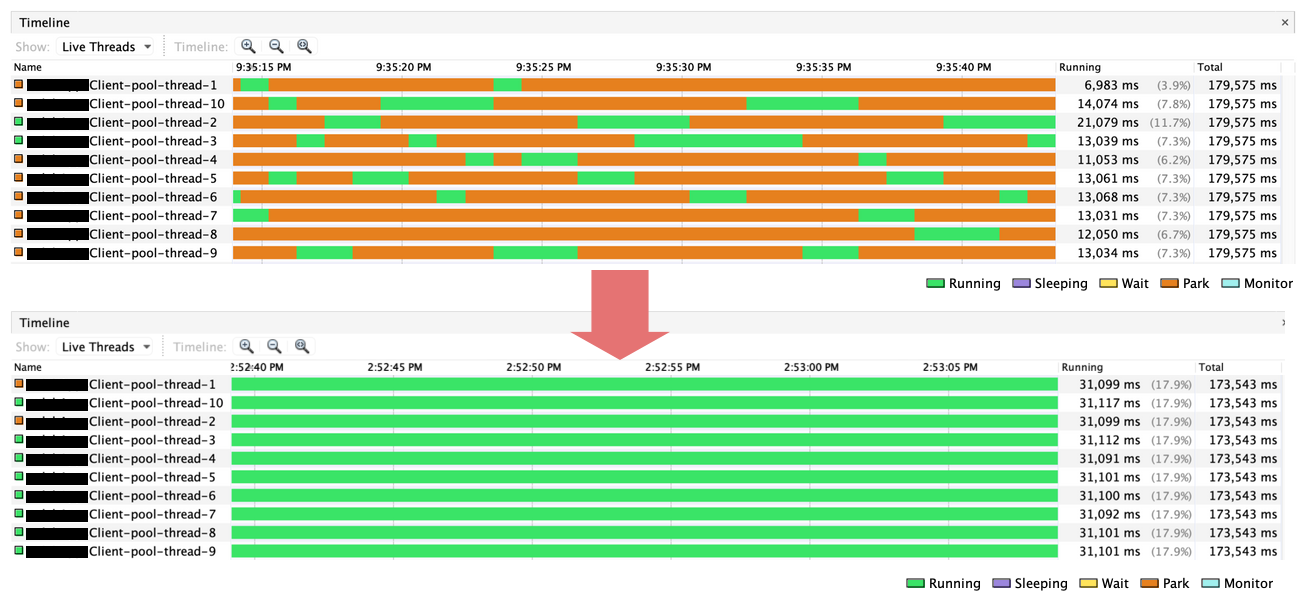
大幅に改善された応答時間
ボトルネックになっていたinternal-apiの認証APIの応答時間をパーセンタイルで確認しました。結果、internal-apiの認証APIの応答時間は大幅に改善されました。
internal-apiの応答時間
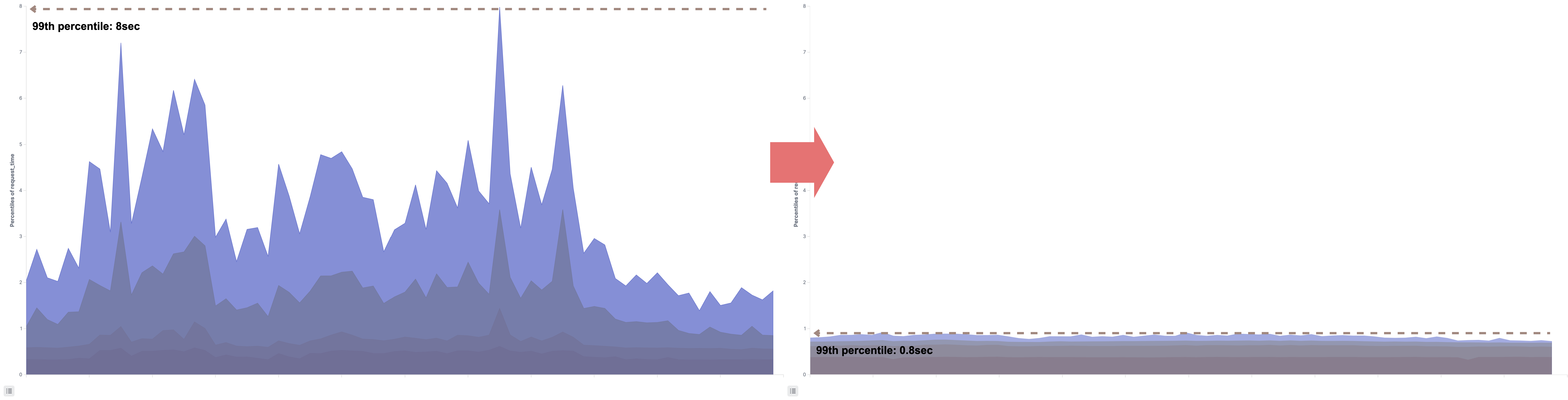
それに伴い、internal-apiの応答時間の劣化に引きずられていたgit-http(GitリポジトリへのHTTPSリクエスト)の応答時間も大幅に改善されました。
git-httpの応答時間
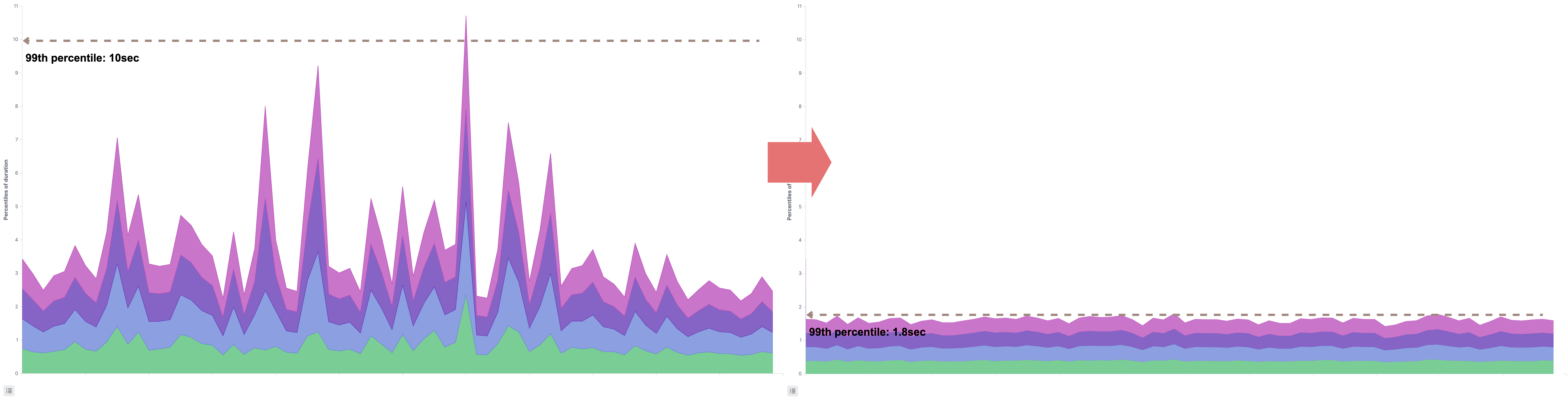
ふりかえり
日々変化するリクエスト量に応じて定期的に設定値を見直す
ボトルネックの原因は内部のアプリケーション間の通信で使用するためにプールしているHTTPコネクションが枯渇していたことでした。HTTPだけではなく各種コネクションプールと呼ばれるものや、プロセス・スレッド数などの設定値は、日々変化するリクエスト数に応じて適切なのか注意しなければならないと反省しました。サーバーのリソースに余剰がある状態で、ソフトウェアの設定がボトルネックになるのはもったいないですね。
分散システムの調査を効率化するためにトレースの仕組みを見直す
今回はサーバーやアプリケーションのメトリクス、ログ、スレッドのダンプ、DBのメトリクス、DBのスローログといった情報を地道に追跡しましたが、決して効率的とはいえません。
所謂「サービス分割」が進むと、その数に比例して複雑性が増し、どのアプリケーションがボトルネックなのか当たりをつけにくくなります。実際に関連するアプリケーションを1つ1つ確認するのは手間取りました。調査を効率化するには、トレースの仕組み自体を改善する必用があります。実際は既にBacklogに関連するアプリケーションのログにトレース用のIDを付与しているのですが、全てのアプリケーションやミドルウェアを網羅できていません。その情報を簡単に可視化できているわけでもありません。
トレースのアプローチとして、AWS X-RayやOpenTelemetryのような分散トレーシングと呼ばれるシステム全体で転送されるリクエストを追跡する仕組みが挙げられると思います。次の図はAWS X-Rayが提供するトレース画面の例です。複数のコンポーネントの応答時間が全て一つの図に可視化されています。どこがボトルネックになっているのか一目瞭然なので、調査効率の大きな改善が期待できます。
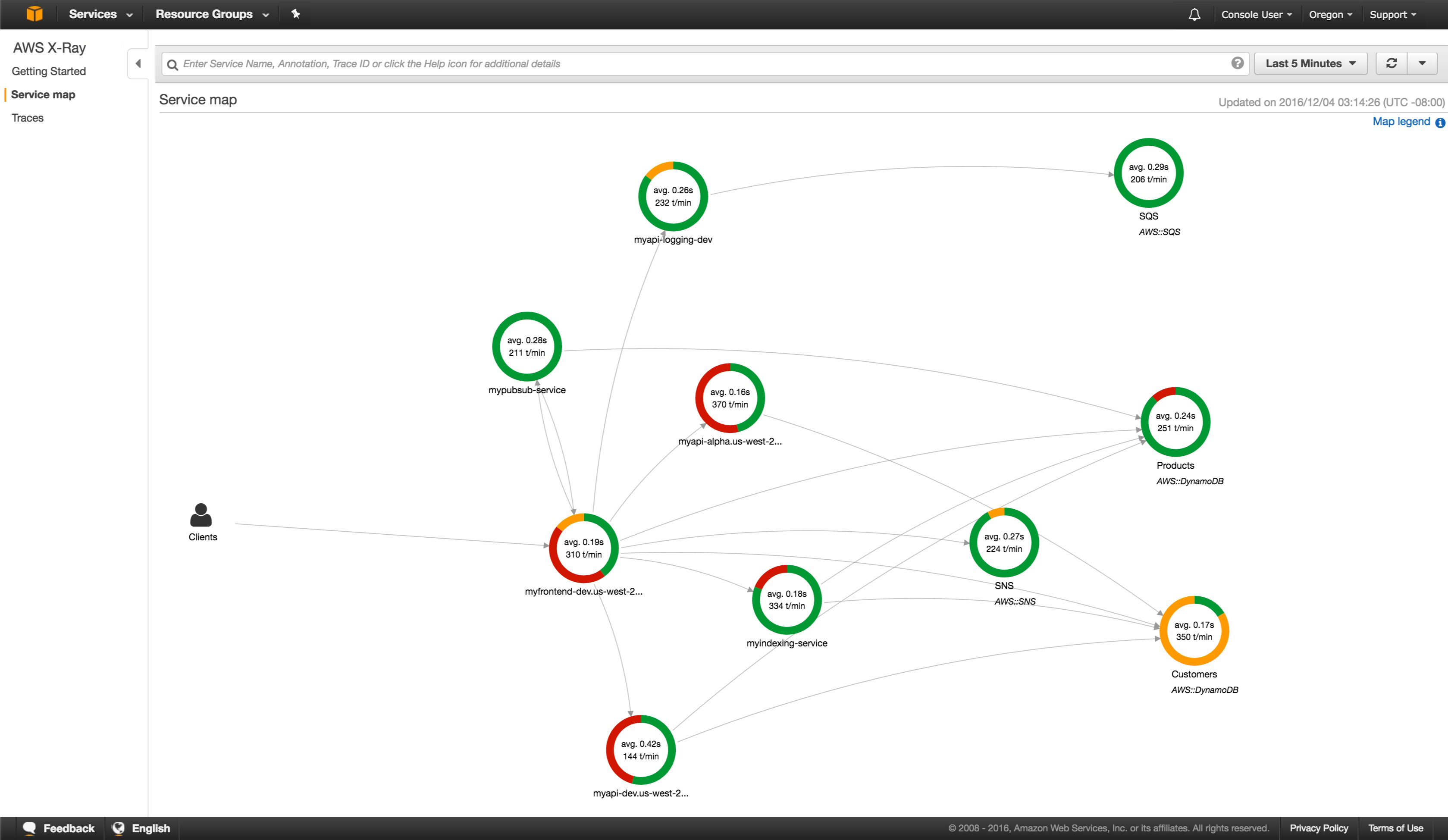
AWS X-RAYの公式サイトから引用
メトリクスやログだけでは足りない情報をスレッド・ヒープダンプから拾う
ボトルネックのアプリケーションに当たりをつけた後、コードレベルで問題を特定するには、事前に仕込んでいるメトリクスやログの情報だけでは調査に限界がくることもあります。今回の調査でもスレッドダンプから根本的な原因が特定できました。問題が起きているアプリケーションの「現在」を深堀りしていくことが結果として効率的だと感じた一件でした
まとめ
本記事では、BacklogのGitホスティングに関連する複数のアプリケーションを横断する処理の性能劣化を受けて、ボトルネックを追跡して改善に繋げた話を紹介しました。今後も変化するリクエストの量に応じた各種パラメーターの最適な設定を定期的に見直し、調査効率の改善のために分散トレーシングの導入を検討していければと思います。

