Backlog課の@vvatanabeです。我々Gitチームの毎朝のルーティンの一つに、
「前日の各種アプリケーション・AWSリソースのアラートやメトリクスを把握する」
と言うものがあります。
これは、SREの@maaaato氏がGitチームにエンベッドされてから毎朝欠かさずやっている習慣です。
先日開催された #NuCon2022 の彼のセッション「チームでサービスの運用をうまく支えていくための取り組み ~SREと共に~」でも、継続している取り組みの一つとして紹介しています。
この取り組みのおかげで、実際に問題を検知して改善に繋げたケースも多々あります。今回はその中から一つ、大容量のストレージを持つサーバーの奇妙なメモリ使用量の増加原因を究明して改善に繋げた話をご紹介します。
目次
TL;DR
Amazon Linux 2のようなRHEL/CentOS系のディストリビューションに大量のファイルを保持している場合、anacronによるmlocate(updatedb)の定期実行でファイルを大量に読み取った結果、Slabキャッシュが増大することがあるので、/etc/updatedb.confの設定を見直しましょう。
朝会で見つかる異変
某日、Gitチームの毎朝のルーティンで前日のアラート・メトリクスのチェックをしていると、Gitホスティング機能で使用している大容量のストレージを持つサーバーで異変が見つかりました。
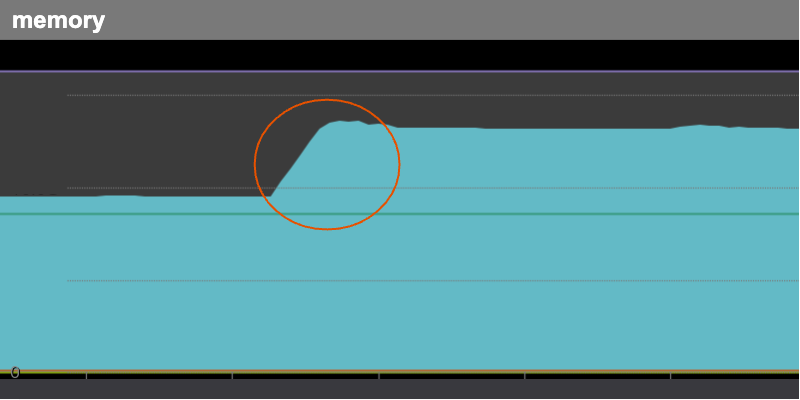
毎朝定時に急上昇するメモリ使用率
早朝の決まった時間(分単位の揺らぎ有り)にメモリが急上昇して、数時間かけてなだらかに解放されるといった現象です。この動きを図のように毎日繰り返していました。
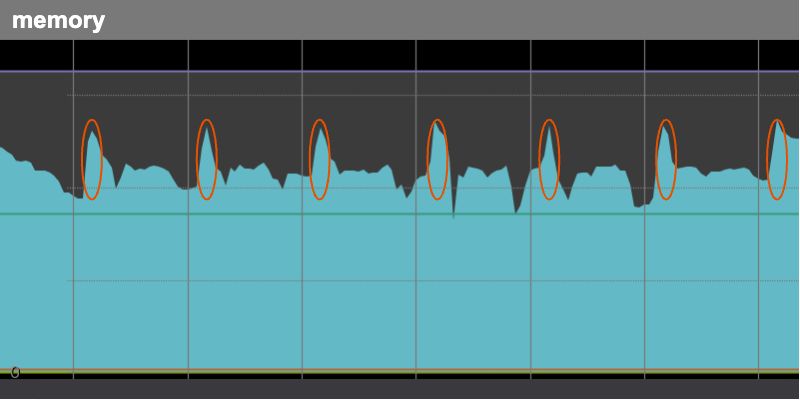
このサーバーはAWSのEC2で稼働しており、1つのサーバーにつき合計数テラバイトのEBSを複数小分けにマウントしています。このサーバーでユーザーのGitリポジトリを管理しています。一般的なWebアプリケーションのサーバーと比較すると、たくさんのファイルを持つことが特徴です。
データ(リポジトリ)は特定のグループで分割され、Multi AZかつPrimary/Replicaな冗長構成になっているため、複数のサーバーが存在します。
補足ですが、BacklogのGitホスティングについての全容は弊社のブログ「BacklogのGitホスティングにおける冗長化と負荷分散の仕組み」でも紹介しているので、興味がある方は是非ご覧ください。
大容量のストレージを持つサーバーで共通して発生
同じようにEC2で稼働している他のサーバーを見てみると、Backlogのファイル共有機能を提供するファイルサーバーでも、ほぼ同じくらいの時刻に(完全に同じではない)、似たような症状がでていました。
ただし、サーバーによってその波の大きさは大きく異なりました。
原因の追跡
Gitリポジトリを取り扱うサーバーなので、大きめのファイルを大量に送受信することも多々有るのでメモリは大量に積んでいるのですが、このような動きは不可解です。
各種メトリクスの調査
対象のサーバーの監視にはMackerelを使用しており、基本的なホストサーバーのメトリクスとアプリケーションプロセスのメトリクスを閲覧できるようにしています。
ホストメトリクス
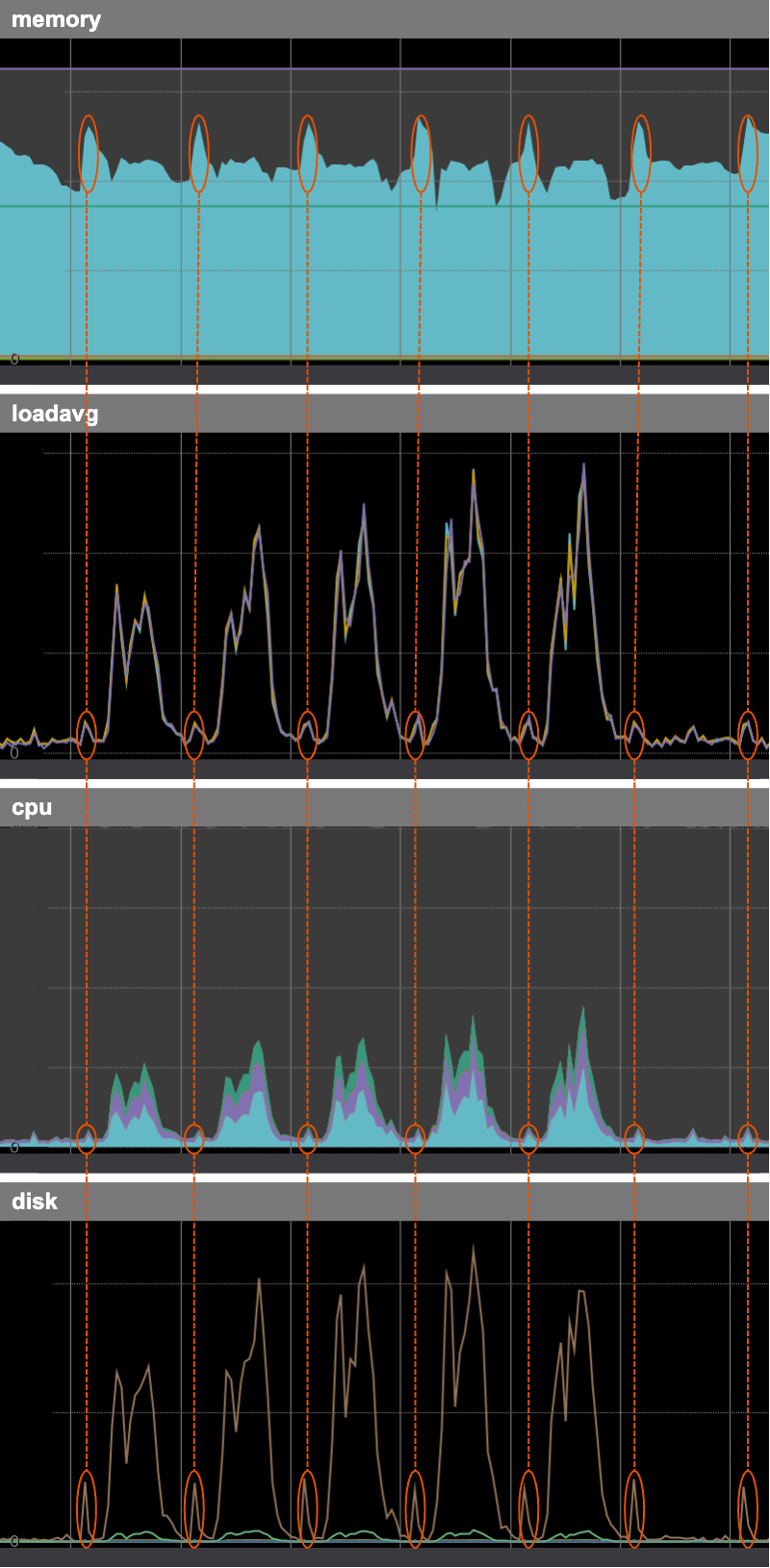
まずは、サーバーのメモリが消費されている時間帯に、なにかしらのメトリクスに怪しい動きはないか確認しました。
Load AverageとCPUはごく僅かですが同じタイミングで上昇していました。同じく、DiskのIOPSのreadが同じタイミングで上昇していました。そのタイミングでもwriteは上昇していませんでした。
「何かしらのファイルの読み取りが定期的に行われている」のは間違いなさそうです。
送受信したバイト数を示すinterfaceは、rxBytes(受信)もtxBytes(送信)も平常でした。TCP接続も特に増えていませんでした。どうやら、「外部からの大量のgit fetchやgit push」ではなさそうです。 アプリケーションのログを見ても局所的な大量アクセスは見受けられませんでした。また、ファイルシステムの使用量も特に変化は有りませんでした。
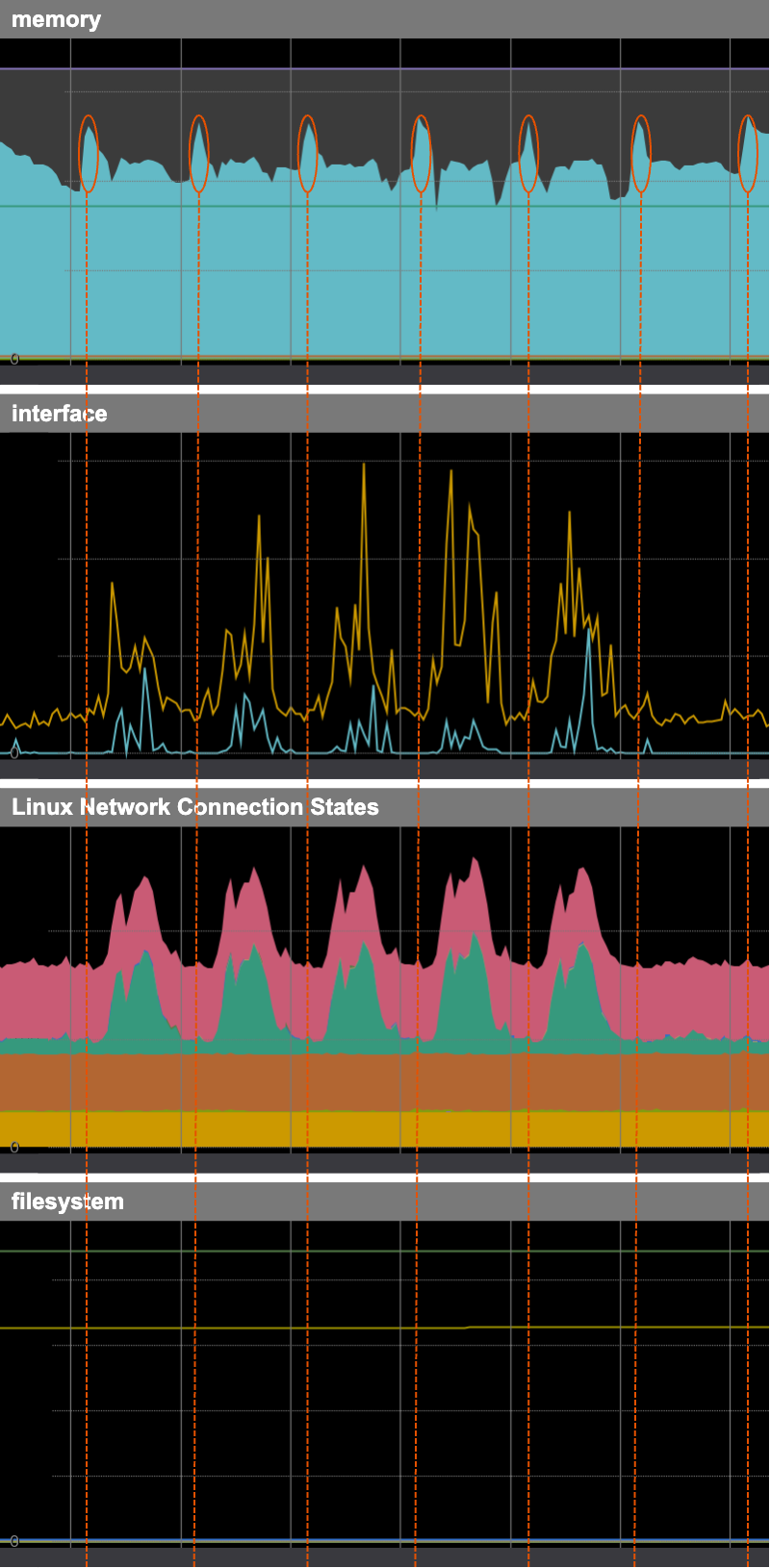
ここまでの調査でわかった事:
- 何かしらのファイルの読み取りが定期的に実行されている
- 定期的な処理の実行開始時間には数分の揺らぎがある
- 外部からのリクエスト起因ではない
- ファイルへの大きなデータの書き込みはない
アプリケーションのログ・メトリクス
次に、サーバーの主要なプロセスであるGo製のアプリケーションのメトリクスとログを調査しました。
もしアプリケーションに異常があれば、GoのpprofでCPUやHeapのプロファイルを解析することで調査が捗ります。しかし、以下のメトリクスは全て平常でした。
- GCの回数
- Goroutineの数
- メモリアロケーション
- Stackサイズ
- Heapサイズ
このアプリケーションでディスクIOが発生するのは、cgoを介して呼び出すC言語で書かれた関数か、外部プロセスとして起動するGitコマンドです。そのため、C言語で書かれた関数や起動したGitコマンドがメモリを大きく消費しても、Goのヒープサイズには反映されません。
そこで、cgoの呼び出し回数のメトリクスや、対象の時間帯にリクエストサイズやレスポンスサイズの大きいものがないかアプリケーションのログを見て調査しました。結果、メモリが上昇する時間帯に怪しい動きは見当たりませんでした。やはりユーザーからのリクエスト等の外的要因ではなさそうです。
ここまでの調査でわかった事:
- 何かしらのファイルの読み取りが定期的に実行されている
- 定期的な処理の実行開始時間には数分の揺らぎがある
- 外部からのリクエスト起因ではない
- ファイルへの大きなデータの書き込みはない
- [New] アプリケーションはメモリを消費していない
実行中のプロセスの状態の調査
ここまで、メトリクスやログを調査しましたが、決定的な原因の特定まで至りませんでした。そのため、実際にメモリを消費している時間帯(以下の図の赤枠の時間帯)にサーバーに入って状態を調査することにしました。
基本的なところではありますが、topコマンドで実行中のプロセスの状態をメモリ使用率順にソート(Shift+m)して確認しました。しかし、特に大きくメモリを消費しているプロセスは見当たりまん。メインのアプリケーション以外のなにかしらのデーモンプロセスがメモリを消費している訳ではなさそうです。
ここまでの調査でわかった事:
- 何かしらのファイルの読み取りが定期的に実行されている
- 定期的な処理の実行開始時間には数分の揺らぎがある
- 外部からのリクエスト起因ではない
- ファイルへの大きなデータの書き込みはない
- アプリケーションはメモリを消費していない
- [New] その他のデーモンプロセスもメモリを消費していない
システムのメモリ使用率の内訳の調査
次にfreeコマンドでシステムのメモリ使用率の内訳を見てみました。結果、圧倒的にキャッシュが多いことがわかりました。
ページキャッシュ(ストレージ上のファイルのキャッシュ)が圧迫しているのか? システムのメモリの情報をさらに詳しく確認するために、/proc/meminfo を見てみました。するとSlabという項目が異常にメモリを消費していることに気づきました。
Slabとは? 調べてみると、ディレクトリのメタ情報を格納するdentryのキャッシュや、ファイルのメタ情報を格納するinodeのキャッシュのことで、カーネル領域に保存されるものらしいです。
参考記事:
SReclaimableは回収可能なキャッシュで、SUnreclaimは回収不可なキャッシュのことらしく、これらを足したものが上記のSlabになるとのことでした。
このSlabの詳細はslabtopコマンドや、/proc/slabinfo で確認できるようです。
slabtopコマンドを実行してみるとxfs_inodeとdenrtyのサイズが極端に上がっていました。
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME 4393116 4352924 99% 0.94K 587694 34 18806208K xfs_inode 2713956 2535566 93% 0.19K 129236 21 516944K dentry
全体のメモリ使用量が落ちはじめる時間帯に再度slabtopコマンドを実行してみるとxfs_inodeとdentryが極端に下がっていました。
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME 2023702 1478177 73% 0.94K 200638 34 6420416K xfs_inode 1015497 637110 62% 0.19K 48357 21 193428K dentry
メモリを消費しているのはSlabで間違いなさそうです。
参考記事: slabtop(1) — Linux manual page
ここまでの調査でわかった事:
- 何かしらのファイルの読み取りが定期的に実行されている
- 定期的な処理の実行開始時間には数分の揺らぎがある
- 外部からのリクエスト起因ではない
- ファイルへの大きなデータの書き込みはない
- アプリケーションはメモリを消費していない
- その他のデーモンプロセスもメモリを消費していない
- [New] Slab(dentryやinodeのキャッシュ)がメモリを消費している
定期実行されている処理の調査
それでは何が原因でSlabが増えているのか、原因を特定する必要があります。Mackerelに記録されている某日のメモリのメトリクスでは、3:41から急激にメモリ使用率が上昇して3:48にピークを迎えています。
この時間帯に何か関連しそうな足跡はないのか、 /var/log/cron を確認してみました。
# cat /var/log/cron 03:41:01 anacron[6362]: Job `cron.daily' started 03:41:01 run-parts(/etc/cron.daily)[17050]: starting logrotate 03:41:01 run-parts(/etc/cron.daily)[17079]: finished logrotate 03:41:01 run-parts(/etc/cron.daily)[17050]: starting man-db.cron 03:41:02 run-parts(/etc/cron.daily)[17118]: finished man-db.cron 03:41:02 run-parts(/etc/cron.daily)[17050]: starting mlocate 03:48:07 run-parts(/etc/cron.daily)[19009]: finished mlocate 03:48:07 anacron[6362]: Job `cron.daily' terminated
すると、対象の時間帯に実行されているログを発見しました。以下の3つです。
- logrotate
- man-db.cron
- mlocate
ここまでの調査でわかった事:
- 何かしらのファイルの読み取りが定期的に実行されている
- 定期的な処理の実行開始時間には数分の揺らぎがある
- 外部からのリクエスト起因ではない
- ファイルへの大きなデータの書き込みはない
- アプリケーションはメモリを消費していない
- その他のデーモンプロセスもメモリを消費していない
- Slab(dentryやinodeのキャッシュ)がメモリを消費している
- [New] 該当の時間にcronで定期実行しているスクリプトがある
続いて、/etc/cron.daily に配備されているshellスクリプトの挙動を調査しました。
logrotate
以下のスクリプトは /etc/cron.daily/logrotate です。 内部でlogrotateコマンドを実行していました。
#!/bin/sh
/usr/sbin/logrotate -s /var/lib/logrotate/logrotate.status /etc/logrotate.conf
EXITVALUE=$?
if [ $EXITVALUE != 0 ]; then
/usr/bin/logger -t logrotate "ALERT exited abnormally with [$EXITVALUE]"
fi
exit 0
logrotateはログファイルの自動ローテーション、圧縮、削除、メール送信を行うツールです。通常は毎日のcronジョブとして実行されます。
参考記事: logrotate(8) – Linux man page
man-db.cron
以下のスクリプトは /etc/cron.daily/man-db.cron です。内部でmandbコマンドを実行していました。
#!/bin/bash
if [ -e /etc/sysconfig/man-db ]; then
. /etc/sysconfig/man-db
fi
if [ "$CRON" = "no" ]; then
exit 0
fi
renice +19 -p $$ >/dev/null 2>&1
ionice -c3 -p $$ >/dev/null 2>&1
LOCKFILE=/var/lock/man-db.lock
# the lockfile is not meant to be perfect, it's just in case the
# two man-db cron scripts get run close to each other to keep
# them from stepping on each other's toes. The worst that will
# happen is that they will temporarily corrupt the database
[[ -f $LOCKFILE ]] && exit 0
trap "{ rm -f $LOCKFILE ; exit 0; }" EXIT
touch $LOCKFILE
# create/update the mandb database
mandb $OPTS
exit 0
mandbは、通常 man によって維持されているインデックスデータベースキャッシュを初期化したり、手動で更新するために使用されます。
参考記事: mandb(8) — Linux manual page
mlocate
以下のスクリプトは /etc/cron.daily/mlocate は内部でupdatedbコマンドを実行していました。
#!/bin/sh
nodevs=$(awk '$1 == "nodev" && $2 != "rootfs" && $2 != "zfs" { print $2 }' < /proc/filesystems)
renice +19 -p $$ >/dev/null 2>&1
ionice -c2 -n7 -p $$ >/dev/null 2>&1
/usr/bin/updatedb -f "$nodevs"
updatedbは、locate(ファイルやディレクトリを高速に検索するコマンド)が使用するインデックスデータベースを作成または更新します。updatedbは通常、デフォルトのインデックスデータベースを更新するためにcronによって毎日実行されます。
参考記事: updatedb(8) – Linux man page
Gitサーバーやファイルサーバーはファイル数が圧倒的に多いため、このupdatedbがトリガーとなってinodeとdentryのSlabが極端に増えるのも頷けます。また、/etc/cron.daily/mlocate の実行に7分もかかっており、これはサーバーのメモリ使用量がピークに達する時間と一致しています。
前述のtopコマンドでプロセスの状態を確認した時に、メモリを消費しているプロセスは表示されないけれどもOSのメモリ使用率は上がっていました。
その原因は、既にupdatedbコマンドの処理は終了しており、処理終了後にSLABキャッシュが残っていたためだと推測できます。
改善策の実施
/etc/cron.daily/mlocateが設定されている理由
今回の調査の目的は、異常なメモリ使用量を抑えることです。このままでは、サーバーのリポジトリが増えれば増えるほど線形にメモリ使用量も増えることが予想されます。
しかし、安易に /etc/cron.daily/mlocate を削除できません。誰がどのような目的でこのcronを設定しているのか調査しました。
Backlog課では様々なサーバーをプロビジョニングするためのコード(Ansible等)を1つのリポジトリに集約しています。そこで、そのリポジトリ内を検索して見ましたが、/etc/cron.daily を設定しているコードは見当たりませんでした。
BacklogのGitサーバーやファイルサーバーは、RHEL/CentOSベースのAmazon Linux2を使用しているのですが、どうやら、RHEL/CentOSではデフォルトでログローテーションやman-dbの更新、mlocateのインデックスデータベースの更新のトリガーにcronを使用しているようでした。
ここまでの調査で、社内の誰かが意図して設定したものではないことがわかりました。さらに、定常業務でサーバー内のファイル検索に対してlocateコマンドを使うような作業もなかったので、/etc/cron.daily/mlocate が呼び出すupdatedbの処理に変更を加えても問題なさそうです。
/etc/updatedb.confの設定変更
そこで、updatedbの設定ファイルである/etc/updatedb.conf を変更しました。以下はそのデフォルトの設定です。
PRUNE_BIND_MOUNTS = "yes" PRUNEFS = "9p afs anon_inodefs auto autofs bdev binfmt_misc cgroup cifs coda configfs cpuset debugfs devpts ecryptfs exofs fuse fuse.sshfs fusectl gfs gfs2 gpfs hugetlbfs inotifyfs iso9660 jffs2 lustre mqueue ncpfs nfs nfs4 nfsd pipefs proc ramfs rootfs rpc_pipefs securityfs selinuxfs sfs sockfs sysfs tmpfs ubifs udf usbfs fuse.glusterfs ceph fuse.ceph" PRUNENAMES = ".git .hg .svn" PRUNEPATHS = "/afs /media /mnt /net /sfs /tmp /udev /var/cache/ccache /var/lib/yum/yumdb /var/spool/cups /var/spool/squid /var/tmp /var/lib/ceph"
PRUNEPATHSという項目にスペース区切りで絶対パスのディレクトリが記述されています。これがupdatedbのインデックスデータベースの対象外となるディレクトリになるようです。案の定、このPRUNEPATHSにGitリポジトリを保持しているディレクトリのパスはありませんでした。PRUNEPATHSに除外するディレクトリのパスを追加することでupdatedbによる大量のファイルの読み取りを回避できそうです。
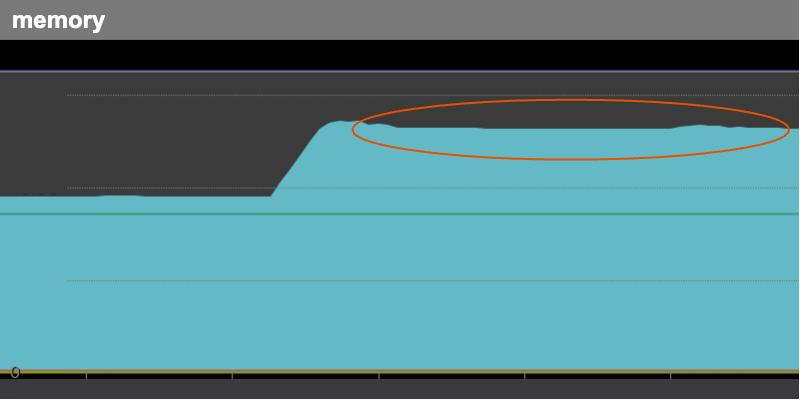
効果測定
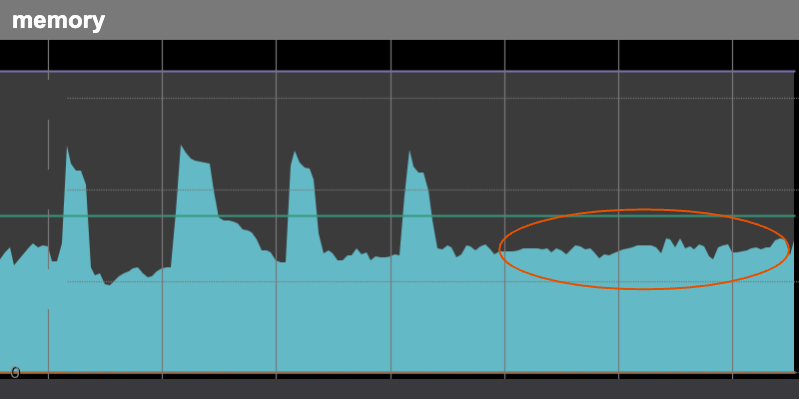
PRUNEPATHSに除外するディレクトリのパスを追加して後日メトリクスを見ると、定時に急上昇していたメモリ使用率は期待通り安定していました。
Amazon Linux 2のようなRHEL/CentOS系のディストリビューションに大量のファイルを保持している場合、/etc/cron.daily/mlocate (updatedb)の定期実行でファイルを大量に読み取った結果、Slabキャッシュが増大することがあるので、/etc/updatedb.confの設定を見直しましょう。
まとめ
日々運用しているアプリケーションやシステムのメトリクスを定期的に確認することで、アラートが飛ばない(閾値を超えない)程度の、ある意味奇妙なシステムのリソースの変化に気づくきっかけになりました。
また、以下のとおり今回の調査において技術的に高度なことは何もしていません。
- 他のサーバーで似たような現象が起きていないか確認する
- システムのメトリクスを確認する
- アプリケーションのメトリクスを確認する
- アプリケーションやシステムのログを確認する
- 実行中のプロセスやメモリ使用率の内訳を確認する
しかし、たかが基本されど基本、持ち得る情報から事実を一つ一つ確実に明らかにしていくことが、俗に言う「ハマり」を回避できる有効な手立てだと改めて実感しました。
[エピローグ] cronの実行タイミングの揺らぎについて
今回の問題を調査するにあたって、わかりにくさの原因の一つになっていた、日次ジョブの実行タイミングの揺らぎについて調査しました。
結論から言うとanacronで揺らぎを設定しているのですが、そのanacronの挙動の詳細を追ってみたので補足として解説します。
anacronとは
anacronはcronと同じく処理を定期的に実行するためのツールの一つです。anacronはcronにより1時間に1回実行されます。別途crondのようなデーモンプロセスが動作している必要はありません。さらに、指定したジョブのスケジュールにランダムなdelayを設定して実行タイミングに揺らぎを与えることが可能です。
参考記事: anacron(8) – Linux man page
anacronによるジョブ実行の流れ
以下の図はanacronによるジョブ実行の流れです。
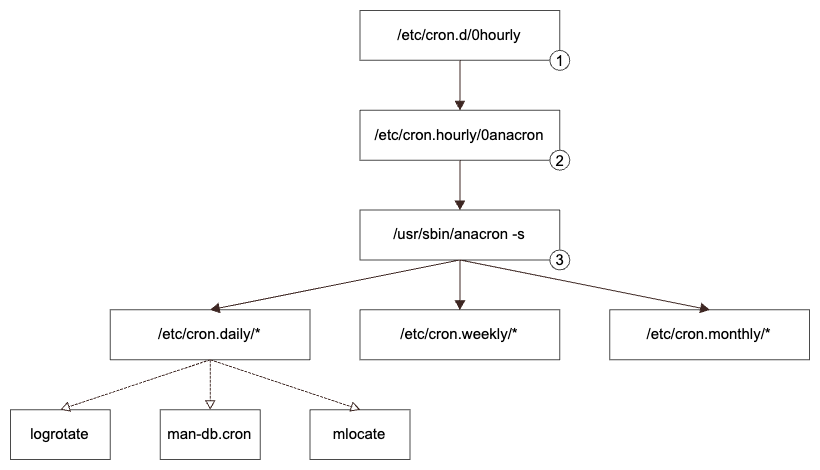
1. crondによる/etc/cron.hourly/*の実行
以下の /etc/cron.d/0hourly の設定により、/etc/cron.hourly/* の処理を毎時1分に実行します。
# Run the hourly jobs SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root 01 * * * * root run-parts /etc/cron.hourly
2. /etc/cron.houry/0anacronによるanacronの実行
以下の /etc/cron.houry/0anacron の設定により、/usr/sbin/anacron を実行します。
#!/bin/sh
# Check whether 0anacron was run today already
if test -r /var/spool/anacron/cron.daily; then
day=`cat /var/spool/anacron/cron.daily`
fi
if [ `date +%Y%m%d` = "$day" ]; then
exit 0;
fi
# Do not run jobs when on battery power
if test -x /usr/bin/on_ac_power; then
/usr/bin/on_ac_power >/dev/null 2>&1
if test $? -eq 1; then
exit 0
fi
fi
/usr/sbin/anacron -s
3. anacronによる日次、週次、月次ジョブの実行
anacronは以下の /etc/anacrontab の設定を読み取り、以下のディレクトリ内のスクリプトをrun-partsコマンドで全て実行します。
- 日次(
/etc/cron.daily) - 週次(
/etc/cron.weekly) - 月次(
/etc/cron.monthly)
# /etc/anacrontab: configuration file for anacron # See anacron(8) and anacrontab(5) for details. SHELL=/bin/sh PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root # the maximal random delay added to the base delay of the jobs RANDOM_DELAY=45 # the jobs will be started during the following hours only START_HOURS_RANGE=3-22 #period in days delay in minutes job-identifier command 1 5 cron.daily nice run-parts /etc/cron.daily 7 25 cron.weekly nice run-parts /etc/cron.weekly @monthly 45 cron.monthly nice run-parts /etc/cron.monthly
anacronによる実行タイミングの揺らぎの仕組み
上記のanacrontabの設定を見ると、RANDOM_DELAY、START_HOURS_RANGE、delay in minutesといった実行タイミングに揺らぎを持たせるようなワードが見受けられます。
RANDOM_DELAY
RANDOM_DELAYは、/etc/anacrontab で設定するジョブ全体に対して加算される、ランダムな遅延時間(分単位)の最大値です。デフォルトでは最大45分となっています。
START_HOURS_RANGE
START_HOURS_RANGEで指定した時間帯にのみジョブが開始されます。デフォルトでは3時から22時となっています。
delay in minutes
delay in minutesは、ジョブを実行する前にanacronが待機する時間(分単位)です。デフォルトの日次の設定は5分となっています。
ジョブの実行時刻を求める計算式
以下は、上記の3つの変数を元にしたジョブの実行時刻の計算式です。
ジョブの実行時刻 = anacronの起動時刻 + RANDOM_DELAYで指定した値を最大とするランダムな遅延時間 + delay in minutesで指定したジョブ固有の遅延時間
さらに、上記の式で求めたジョブの実行時刻が、START_HOURS_RANGEの範囲である場合のみ実行されます。
ここまでで解説した前提を元に、anacronによるランダム性のあるジョブの遅延実行の流れを整理します。
- crondは
/etc/cron.d/0hourlyの設定により/etc/cron.houry/*の処理を毎時1分に実行する /etc/cron.houry/0anacronの設定により/usr/sbin/anacronを実行する- anacronは
/etc/anacrontabの設定を読み取り、RANDOM_DELAY、delay in minutesの変数を元にジョブの実行時刻を決定する - 決定したジョブの実行時刻が、START_HOURS_RANGEの範囲である場合のみジョブを実行する
そして、mlocateの実行時間は、
- RANDOM_DELAYが45分、daily jobのdelay in minutesが5分なので、最小で6分、最大で50分の揺らぎがある
- anacronはcrondにより毎時1分に実行され、START_HOURS_RANGEは3時から22時となっているため、毎日3時1分に実行される
ということで、3時7分から3時51分の間となることがわかりました。実際にcronのログを見ても、mlocateのshellスクリプトはこの時間帯の範囲で実行されていることが確認できました。
# cat /var/log/cron* | grep "starting mlocate" 03:43:01 run-parts(/etc/cron.daily)[23930]: starting mlocate 03:32:02 run-parts(/etc/cron.daily)[28726]: starting mlocate 03:15:02 run-parts(/etc/cron.daily)[31910]: starting mlocate 03:37:02 run-parts(/etc/cron.daily)[24432]: starting mlocate 03:21:01 run-parts(/etc/cron.daily)[27305]: starting mlocate 03:07:02 run-parts(/etc/cron.daily)[31775]: starting mlocate 03:44:01 run-parts(/etc/cron.daily)[8167]: starting mlocate 03:41:02 run-parts(/etc/cron.daily)[15845]: starting mlocate 03:10:01 run-parts(/etc/cron.daily)[3355]: starting mlocate 03:49:01 run-parts(/etc/cron.daily)[26670]: starting mlocate 03:38:01 run-parts(/etc/cron.daily)[15659]: starting mlocate 03:45:02 run-parts(/etc/cron.daily)[5610]: starting mlocate 03:38:01 run-parts(/etc/cron.daily)[29477]: starting mlocate 03:08:01 run-parts(/etc/cron.daily)[23104]: starting mlocate 03:40:02 run-parts(/etc/cron.daily)[19683]: starting mlocate 03:47:01 run-parts(/etc/cron.daily)[19850]: starting mlocate 03:49:02 run-parts(/etc/cron.daily)[16391]: starting mlocate 03:31:02 run-parts(/etc/cron.daily)[20795]: starting mlocate ...省略
参考記事:
