こんにちは。Cacooチームの木村です。以前プルリクを起点に検証環境が自動で構築されるようにしたら すぐにレビューできるようになったのでみんなハッピーになれた話をしたのですが、色々課題があったのでKubernetesのJobを使って改善しましたので紹介します。
この記事はヌーラバー真夏のブログリレー2024の12日目の記事です。
目次
【経緯】プルリク環境は便利
前回の記事では、以下のような経緯からプルリク環境を構築しました。
-
開発中の機能を試せる検証環境がある
-
検証環境があると複数人でレビューできて便利
-
便利すぎてみんなが検証環境のリビジョンを変更したがる
-
プルリクエスト用の環境が構築される仕組みをつくった
-
複数のプロジェクトが同時進行してても、みんながそれぞれの環境を試せて便利
プルリク環境はチーム内でたいへん好評でした。使い方は非常に簡単で、プルリクエストを作成すると、CIがそのブランチのコードをもとにPodがビルドと検証環境へのデプロイを実行します。プルリク環境にアクセスするには発行されたURLを開けばいいだけなので、開発チームだけでなくマネージャーやデザイナーにも手軽に使ってもらえていました。
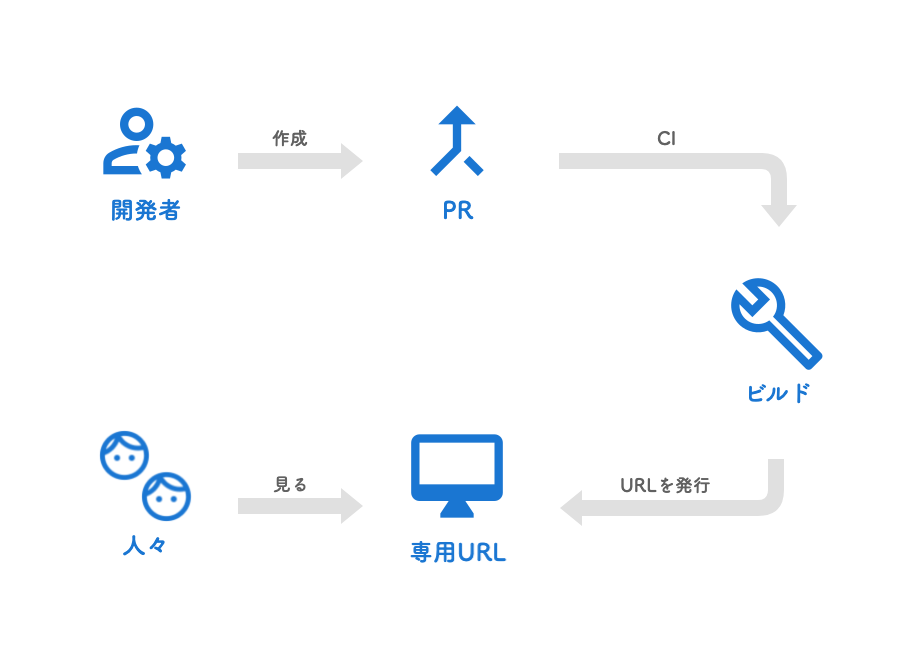
プルリク環境は便利
【問題点】なんかPodが消えてるんだが
ところが、それなりに使ってもらってると「エラーが返ってきてアクセスできない」という問い合わせが開発チーム内外から来るようになってきました。プルリク環境にアクセスするためのURLを開くと500エラーが返ってきてしまうようです。
kubectlをカチャカチャ、ッターン!と打って調べてみると、あるはずのプルリクに対応するPodがありませんでした。ログをみる限り、なんらかの理由でプロセスが終了してPodも終了していたようです。
「そういうのは普通自動的に再起動するようになってるんじゃないのか?」と思うかもしれません。実は、プルリク環境では意図的にそれをオフにしています。ひとつひとつのプルリク環境は恒久的に必要なものではなく、レビューが終われば不要になります。その性質上、一定期間後にプロセスが終了するようになっており、その時に再起動してしまわないようにしています。
Kubernetes上でアプリを動かす場合、再起動ポリシーを設定してプロセスが異常終了しても再起動するように設定することが多いと思います。プルリク環境用のPodは再起動ポリシーをNeverに設定しています。そのため、Pod内のプロセスが終了してしまうとPodもそのまま役割を終えて実家に帰ってしまいます。
以下はプルリク環境用のPodを作成するためのテンプレートに使っているファイルです。restartPolicyをNeverに設定しており、コンテナ起動時にtimeoutコマンドが実行されるようになっています。これにより、一定期間が過ぎた後のPodが終了するようにしているのです。
apiVersion: v1
kind: Pod
metadata:
name: pr-env #Pod作成時に変更
labels:
app: pr-env
spec:
hostname: pr-env #Pod作成時に変更
subdomain: pr-env
restartPolicy: Never
affinity: #(省略)
containers:
- env: #(省略)
image: #(省略) #Pod作成時に変更
imagePullPolicy: Always
livenessProbe: #(省略)
name: pr-env
ports: #(省略)
resources: #(省略)
startupProbe: #(省略)
command: ["/usr/bin/timeout"]
args: ["14d", "/httpd/entrypoint.sh"]
これだと異常終了時にPodが再起動してくれません。かといって再起動ポリシーをAlwaysやOnFailureにしてしまうと、今度は一定期間後に役目を終えたPodが再び元気に息を吹き返してしまいます。Podが減らないままプルリクエストが作られるたびに新しいPodが供給され続けるので、不要なPodが堆積し続けることになります。
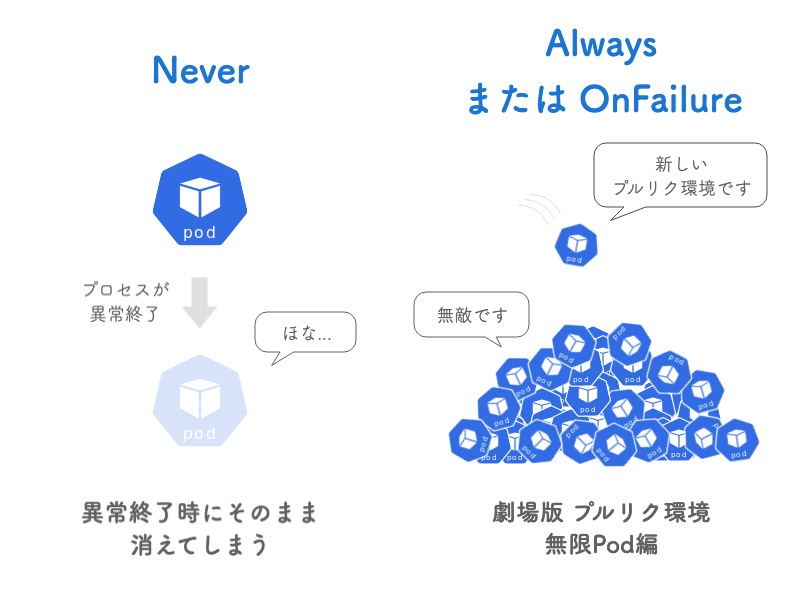
プルリク環境と再起動ポリシーのジレンマ
【解決策】そうだ Job、使おう
そんな感じでPodが終了しても再起動してくれず、「しばらくするといつの間にかプルリク環境が使えなくなっていた」という問題が発生するようになっていました。残念ながらいい感じの解決策を思いつかなかったので対策が打てずじまいで、問題が発生したらその都度手動でCIを再実行するなりkubectlでPodを作り直すなりしていました。
面倒なので完全に放置していた解決策を慎重にじっくり検討に検討を重ねていたところ、同じ開発チームの方が某チャット系生成AIに聞いてくれました。どうやら Job を使うと問題が解決するようです。AIが言うなら間違いありません。愚かな人類である我々はAIに従うことにしました。
Jobは指定された数のPodが正常に終了するまで、Podを作成し続けるやつです。ちなみに前回紹介した CronJob はスケジュールにしたがって永続的に実行し続けるやつでしたが、実はその中で作成しているのがJobです。
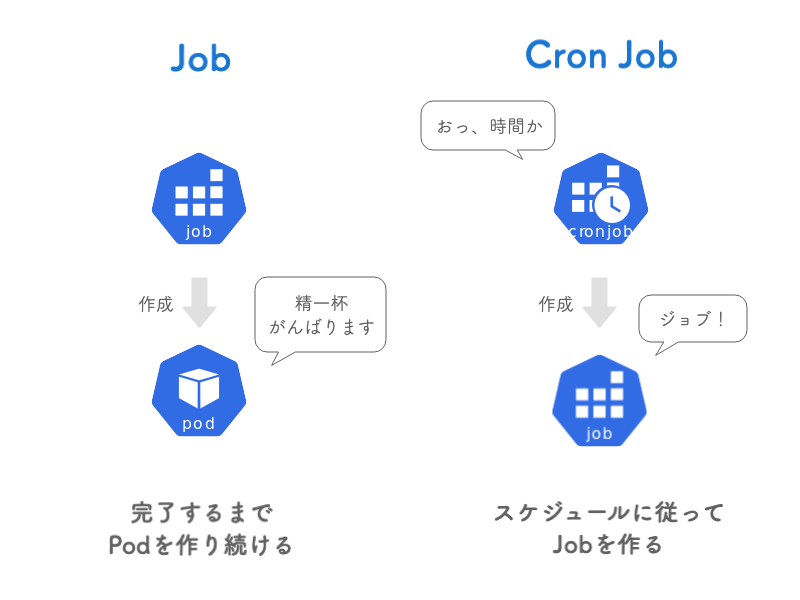
JobはPodを作り、Cron JobはJobを作る
重要なのは、Jobを使ってPodを作成すれば、きちんと完了するまで再作成してくれるということです。これならプロセスが異常終了してもPodの再作成によってプルリク環境が維持されそうです。さすがAI。完璧なソリューションです。
具体的には以下のような手順でプルリクエストごとに動的にJobを作成できるようにします。
- あらかじめテンプレートになるファイルjob.yamlを用意しておく
- CI上でkubectl patchコマンドを使ってJobを作成する
あらかじめテンプレートになるファイルjob.yamlを用意しておく
以下のようなファイルを準備しておきます。
apiVersion: batch/v1
kind: Job
metadata:
name: pr-env
spec:
activeDeadlineSeconds: 1209600
ttlSecondsAfterFinished: 100
template:
metadata:
labels:
app: pr-env
spec:
subdomain: pr-env
restartPolicy: OnFailure
containers:
#(以下省略)
kindにJobを指定します。ここに今まで使ったことないやつを指定するときってなんだかワクワクドキドキしますよね(します)。あとはJobならではのフィールドとしてactiveDeadlineSecondsとttlSecondsAfterFinishedというものがあります。
activeDeadlineSecondsはJobの活動期間です。JobがactiveDeadlineSecondsに達すると、実行中のすべてのPodが終了します。今回の用途ではプルリク環境が2週間ほどあれば十分なので、1209600を設定しています。
ttlSecondsAfterFinishedはJobのお掃除のために必要なフィールドです。Jobが終了してから100秒後に自動的に削除されるように設定しています。
あとはこれまで通りPodの設定を .spec.template に入れておけばいいですが、restartPolicyをOnFailureにしておくことコンテナ内でプロセスがエラー終了しても自動で再起動してくれるようになります。また、これまでの例ではtimeoutコマンドで自動終了するように設定していましたが、それは必要ありません。
CI上でkubectl patchコマンドを使ってJobを作成する
あとはCI上で動的にJobを作成すればプルリクエストごとにJobおよびPodが作成され、プルリク環境の完成です。前回同様、kubectl patchを使います。詳しくは前回の記事を参照してください。
kubectl patch --local=true –-output yaml –-filename job.yaml --type json --patch ${JSON} | kubectl apply -f -
前回と同様に、nameと(Podの)hostname、imageをプルリクエストごとのあたいに書き換えればいいのですが、Podとは構造が異なるので指定するフィールドが少々変わります。実際には、JSONで指定する値は以下のようになりました。
[
{
"op": "replace",
"path": "/metadata/name",
"value": "pr-env-${tag}"
},
{
"op": "replace",
"path": "/spec/template/spec/hostname",
"value": "${tag}"
},
{
"op": "replace",
"path": "/spec/template/spec/containers/0/image",
"value": "${imageName}"
}
]
.metadata.nameはJobの名称です。プルリクエストごとにユニークな値(この場合tag)を使って重複するのを避けています。
.spec.template.spec.hostnameはPodに設定する hostname の値です。これを使って任意のPodにリクエストできるようにします。詳しい方法は前回説明しているので省略します。こちらもプルリクエストごとにユニークである必要があります。
.spec.template.spec.containers\[0\].imageはコンテナイメージです。CIでビルドしたイメージを指定することでプルリク環境を実現します。
【結果】や、やったか…?
Jobを使うことで再起動ポリシーを設定しつつ自動で削除されるPodを動的に作ることができました。おかげでプロセスがエラー終了しても再起動するプルリク環境ができあがりました。
ところが、一部のプルリク環境がactiveDeadlineSecondsで指定した2週間の期間をを待たずして終了していることがわかりました。まずはカチャカチャ、ッターン!とJobの状態を確認します。
$ kubectl get jobs -l app=pr-env NAME COMPLETIONS DURATION AGE pr-env-1000 1/1 9h 11d pr-env-1001 1/1 8h 11d
COMPOLETIONSが1になっていますね。これは変です。activeDeadlineSecondsに達して強制的に終了した場合、そのJobは失敗扱いになります。完了しているのはこちらの意図とは異なります。
無事天寿を全うしたJobは次のようになるはずです。
$ kubectl get jobs -l app=pr-env NAME COMPLETIONS DURATION AGE pr-env-2000 0/1 16d 16d
2週間ほどPodが生きてて欲しいのですが、Jobが無事完了してしまっては困ります。それ以上Podが作られません。なぜこうなるのでしょうか。Jobが完了したのか失敗したのかは、コンテナ内のプロセスの終了コードに依存します。終了コードが0であれば無事に処理完了、それ以外なら異常終了扱いとなります。プロセスが終了コード0で終了してしまっているようですね。これを解決するにはみっつの方法があります。
ひとつはタスクの完了回数を設定する方法です。.spec.completionsを2以上に設定します。設定した完了数に達するまではタスクが実行されるので、プロセスが終了コード0で終了しても完了回数に達するまではPodが再作成されます。
ふたつめは失敗ポリシーを設定することです。失敗ポリシーでは終了コードごとにルールを設定できるので、終了コードが0の場合にも失敗と見なすことができます。失敗したJobはbackoffLimitに達するまで再施行されます。
(追記)この方法は使えないことがわかりました。spec.podFailurePolicyに「終了コードが0の場合」という条件を入れることはできません。
みっつめは終了コードが0になっている原因を追求して対策することです。そもそもサーバーアプリケーションのプロセスが「完了しました!」と無事に終了していることが変な状態です。なんらかのエラーならそれを調査することが望ましいです。
まとめ
この記事ではプルリク環境を題材に、Podの作成をJob経由で行う方法について解説しました。Jobは1回きり(または数回)の処理をPodを作成することで実行するための仕組みでが、activeDeadlineSecondsを設定することで一定期間だけ活動するPodを動的に作成することも可能です。
この改善により、プロセスがエラー終了したときにコンテナ(またはPod)が再起動してくれるようになりました。また、今までPodを作成→timeoutコマンドで終了→CronJobでPodの削除という流れをJobでひとまとめにすることができました。ありがとう生成AI。ありがとうLLM。
まだ課題は残っていますが、これからも開発がいい感じになることをやっていきたいと思います。
