こんにちは、@vvvatanabe です。
OSS への貢献が趣味で、社内 OSPO で OSS への寄付活動を取りまとめたり、業務で使用している OSS には積極的にコントリビュートするように心掛けています。Go 言語が好きで最近は crypt パッケージへの脆弱性報告を行ったり、AI エージェントを開発する際に使用している Mastra へバグ修正・機能追加などコントリビュートしています。
本記事は、2025/12/20 に開催された JAWS-UG Presents – AI Builders Day で発表した「Mastra×AWS におけるサーバーレスなAIメモリの実現」というセッションをブログ化したものです。
サーバーレスな AI メモリにおいて、「どれが最強か」ではなく、「運用負荷を抑える」前提で、AI メモリの構造に対して各マネージドサービスがどこまで素直に対応できるかを比べます。
次の論点で解説し、
-
DynamoDB / Aurora v2 / DSQL の 向き・不向き
-
Memory 特有の 落とし穴
-
要件別の構成パターン
「この選択をすると、どの実装や運用が増えるか」を整理します。
目次
AI メモリの前提
Mastra Memory(何を保存し、どう使う?)
まず、前提として、図をもとにMastra の Memory を分解して解説します。
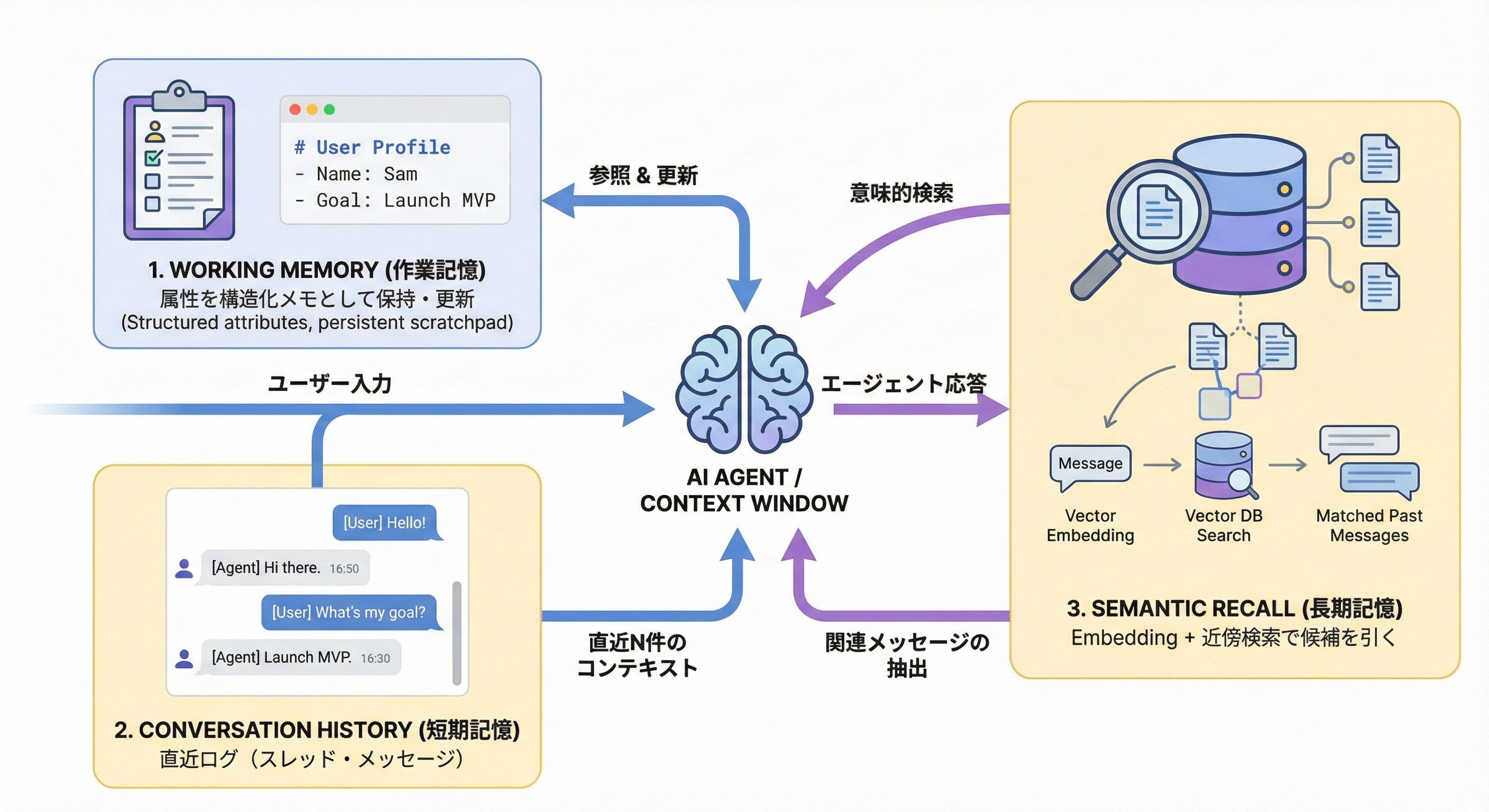
1. Working Memory(作業記憶)
会話から抽出した属性(名前・目的・好み等)を構造化して保持し、会話のたびに更新します。つまり、更新が前提のデータです。
2. Conversation History(短期記憶)
AIエージェントとの会話のヒストリになるスレッド・メッセージです。ここは時系列での取得が主で、おおむね append-only です。
3. Semantic Recall(長期記憶)
過去のAIエージェントとの会話を embedding 化して、近いものを検索する仕組みです。ここはベクタ検索が必要です。
なぜ AI エージェントの Memory は難しい?
なぜ Memory が難しいのか。LLM はステートレスなので、会話が継続しているように見せるための情報は、外部化が必要です。しかし AI メモリのアクセスパターンは、普通の CRUD な Web アプリと少し違います。次に、その 5 つの特徴を解説します。
1. 追記が多い
会話ログは基本「書いて、時系列に取る」が中心です。
2. 一部は更新が多い
Working Memory は会話のたびに“差分更新”されます。つまり「追記」と「更新」が同居します。
3. 意味検索が必要
全文検索ではなく embedding による近傍検索が必要になります。
4. サイズが増えやすい
AIエージェントのツールコールの結果 JSON、HTML、ログ、が肥大化しやすいです。
5. 分析したくなる
運用すると必ず「どのツールが効いた?」「どこで失敗した?」など改善指標が欲しくなります。
この 5 つが同時に来るので、ストレージの得意不得意がそのまま “実装コスト” につながります。
Round 1 – Amazon DynamoDB
まずは、Amazon DynamoDB から詳しく見ていきます。
スケール特性は良いが、クエリ形状が固定されやすい
DynamoDB はスケールと運用の軽さが強いです。 一方で、Mastra 公式の DynamoDB アダプタ @mastra/dynamodb は ElectroDB を使ったシングルテーブル設計が前提になっています。
@mastra/dynamodb の使用例:
import { Memory } from "@mastra/memory";
import { DynamoDBStore } from "@mastra/dynamodb";
// Initialize the DynamoDB storage
const storage = new DynamoDBStore({
name: "dynamodb", // A name for this storage instance
config: {
tableName: "mastra-single-table", // Name of your DynamoDB table
region: "us-east-1", // Optional: AWS region, defaults to 'us-east-1'
// endpoint: "http://localhost:8000", // Optional: For local DynamoDB
// credentials: { accessKeyId: "YOUR_ACCESS_KEY", secretAccessKey: "YOUR_SECRET_KEY" } // Optional
},
});
// Example: Initialize Memory with DynamoDB storage
const memory = new Memory({
storage,
options: {
lastMessages: 10,
},
});
補足:シングルテーブル設計のよしあし
DynamoDB のシングルテーブル設計は、「JOIN がない代わりにデータを事前に寄せておく」発想です。同じ Partition Key に異種アイテム(例:User と Orders)をまとめることで、1 回の Query で必要なデータを一括取得でき、直列の複数リクエストを減らせます。結果としてネットワーク往復が減り、スケールしてもレイテンシが安定しやすいのが主なメリットです。また、副次的に、運用対象のテーブルが減る/プロビジョンド運用ではコストが少し有利というメリットもあります。
一方でデメリットは、設計の自由度を前払いで失う点です。アクセスパターンから逆算してテーブルを特化させるため、後から検索条件や取り回しが増えると、属性の付け替えや ETL 的な更新が必要になり、変更が重くなります。また、非正規化して最適化したデータは分析用途にそのまま使いにくく、別基盤へ出す際に紐解いて整形する手間が増えがちです。
DynamoDB の得意・不得意
DynamoDB はアクセスパターンが固定なら綺麗に解けます。
例:threadId ごとに createdAt で並べて直近 N 件を取得
ただし運用が進むと「複数の条件で絞る」「集計する」が増えます。DynamoDB では基本 GSI を増やすか フルスキャンになり、どちらもコストが出ます。改善ループとDynamoDBの設計思想が噛み合わない局面が出やすいということです。
ポイントは次のとおりです。
-
DynamoDB は 想定したクエリは非常に速い
-
でも運用が進むと 想定外の検索条件・集計が必ず増える
-
その瞬間に「GSI の追加」or「フルスキャン」が前提になりがち
-
DynamoDB の Memory で当たりやすい落とし穴と解決策のパターン
DynamoDB の Memory で当たりやすい落とし穴を 4 つにまとめます。
-
ベクタ検索:DynamoDB 単体でベクタ検索をサポートしていません。
-
400KB 制限:400KB 制限でツールコールの結果が制限以上になり保存できないケースがあります。
-
条件検索・集計:GSI の事前設計や分析基盤が前提となります。
-
ページングの仕組みのギャップ:スレッド・メッセージの UI・IF は offset、DynamoDB は cursor 形式でページングの仕組みのギャップがあります。
結論として、DB 運用は軽い一方、Memory 固有の制約を アプリ側で吸収し続ける形になりやすいです。では実際どうするか。解決策のパターンを整理します。
1. 400KB 制限
400KB 制限は、ほぼ必ず S3 オフロードが候補になります。DynamoDB には索引として、S3 のキーなど最小情報を保持し、本文は S3 に圧縮して置きます。ただし書き込み失敗時に S3 の”残骸” が出るので、クリーンアップ設計が必要です。
2. ベクタ検索
ベクタ検索は、OpenSearch や pgvector、S3 Vectors などの別サービスを使用します。
3. 条件検索・集計
条件検索・集計は、重要なキーだけ GSI、深い分析は ETL で 分析基盤 へ、という二段構えになりがちです。
4. ページングの仕組みのギャップ
offset ページングは、offset 情報と、cursor の ID の対応表キャッシュなどで吸収します。
全体的に、できるけど仕組みを作るコストが大きいです。回避策はあるけど、回避策の分だけ実装と運用が増えますね。
Round 1 結論
Round 1 の結論です。素直に合うのは 単純な追加と一覧取得にとどまる Conversation History です。Working Memory も小さく 400KB 以下に保てるなら、単一キー更新 + 条件付き更新 で制御できます。一方、柔軟検索・集計、Semantic Recall、巨大ログは別サービスやオフロードが前提になりがちです。
マッチするもの:
-
Conversation History(スレッド・メッセージ):単純な追加と一覧取得
-
小さめの Working Memory:単一キー更新 + 条件付き更新(楽観ロック風)
マッチしにくいもの:
-
柔軟検索・集計:GSI設計か別基盤へ
-
Semantic Recall:ベクタストア別建て
-
巨大ログ:S3オフロード前提になりやすい
Round 2 – Aurora Serverless v2 (PostgreSQL)
次は Aurora Serverless v2(PostgreSQL)を詳しく見ていきます。
SQL / JSON / トランザクション / pgvector を同居できる
ここは真逆の方向で、SQL/JSONB/トランザクション/整合性/pgvector といった”DB の表現力”を使って Memory を支えられます。 Mastra の @mastra/pg は storage と vector を同じ DB に向けられるので、Semantic Recall まで一つに寄せる構成ができます。構成が単純になるのは強いです。 一方で、待機コスト・ゼロスケールした時の再開遅延・DB 自体のアップデート運用がネックになります。
@mastra/pg の使用例:
import { PostgresStore, PgVector } from "@mastra/pg";
const memory = new Memory({
storage: new PostgresStore({ connectionString: process.env.DATABASE_URL! }),
vector: new PgVector({ connectionString: process.env.DATABASE_URL! }),
});
SQL:分析クエリを必要な時に書ける
エージェントは必ず改善したくなります。例えば「どのツールが失敗している?」「失敗後にユーザーが再質問している?」「どんなセッションが離脱する?」など。こういうのは集計とフィルタが必要です。 DynamoDB だと、GSI を増やすか、ETL パイプラインを作って分析基盤に流すか、を早い段階で考える必要が出ます。 PostgreSQL なら、とりあえず SQL を書いて見てみる → インデックス追加 → 改善、ができます。これが改善サイクルを速くします。 そのため Aurora v2 (PostgreSQL)の価値は「機能が揃ってる」だけでなく、「運用の意思決定が速くなる」ことにあります。
pgvector:同居できるが、計算リソースを使う
pgvector ですが、本文・メタデータ・ベクタを同居させると、同じDBで完結できて構成が単純になります。ただし HNSW(Hierarchical Navigable Small Worlds)のような高速なインデックスはデータ量・次元が増えるほど メモリの要求が上がり、Aurora v2 では ACU とコストに跳ねます。「寄せると単純になるけど、その分の計算コストを DB が背負う」という整理です。
課題:Scale to Zero の現実(auto-pause)
Aurora Serverless v2 の悩みどころがここです。0 ACU (ゼロスケール)に落とせるのは魅力ですが、再開にはレイテンシが乗ります。AIエージェントの UX は「最初の応答が返ってくるまでの体感」が重要です。DB の再開遅延は、そこに直撃します。なので、「夜だけ止める」「休日は止める」みたいな運用はコストには効くけど、初回アクセスの体験が悪くなる可能性がある。ここは要件次第で、例えば 最低 ACU を 0 にしない、あるいは 常時最小で回す、という判断になると思います。
課題:Reader/Writer の使い分け
Aurora は Writer/Reader のエンドポイントが分かれるので、読みを Reader に逃がしたくなります。ただ @mastra/pg は基本、単一の connectionString と pool で動く設計なので、Reader/Writer を分離したいならラッパーを作ってルーティングする必要があります。MastraのストレージアダプタはMastraStorageクラスをIFに準拠することで実装できます。
カスタムストレージアダプタの例:
class AuroraSplitStore implements MastraStorage {
constructor(private writer: PostgresStore, private reader: PostgresStore) {}
// Read系 → reader
getThread(args) { return this.reader.getThread(args); }
listMessages(args) { return this.reader.listMessages(args); }
// Write系 → writer
saveThread(args) { return this.writer.saveThread(args); }
saveMessages(args) { return this.writer.saveMessages(args); }
}
Round 2 結論
まとめると、Aurora v2 は Memory に必要な機能を 1 つの DB に寄せられるのが最大の強みです。SQL/JSONB/整合性/pgvector。DynamoDB の 400KB のような厳しい制約も相対的に回避しやすいです。 ただし、サーバーレス運用の観点では「待機コストを削るほど初回が遅い」問題と、「DB 運用(アップデート計画など)」が付いてきます。
ここで「SQL の表現力を保ちつつ、待機コストをもっと従量に寄せられないか?」といった次の問いが出ます。
Round 3 – Amazon Aurora DSQL
問いへの回答として Amazon Aurora DSQL を詳しく見ていきます。
SQL を保ちつつ、従量寄りに寄せたい
Aurora DSQL への期待は次の 3 つです。
-
DynamoDB では課題となっていた柔軟検索・集計を SQL で回収したい。
-
Aurora v2 の待機・再開のジレンマを軽くしたい。
-
RDB でありがちなバージョン追従の運用コストを減らしたい。
ただし DSQL は PostgreSQL そのもの ではないので、制約があり、それをどう吸収するかが鍵になります。
DSQL を Mastra から使う:アダプタで吸収する
Mastra は現時点では DSQL のアダプタを公式サポートしていません。なので、@mastra/dsql を自作しました。Mastra 本体にも既に PR を作っています。
@mastra/dsql は内部で AWS 公式の @aws/aurora-dsql-node-postgres-connector を使用して、IAM 認証、接続トークン生成を隠蔽しています。重要なのは、IAM 認証や再試行など分散 DB 側の事情をアプリに漏らさないことです。store 側に寄せて、アプリ層を単純に保ちます。
@mastra/dsql の使用例:
import { DSQLStore } from '@mastra/dsql';
const store = new DSQLStore({
// Required
id: 'my-dsql-store',
host: 'abc123.dsql.us-east-1.on.aws',
// Optional - Connection settings
user: 'admin', // default: 'admin'
database: 'postgres', // default: 'postgres'
region: 'us-east-1', // auto-detected from host if not specified
schemaName: 'public', // default: 'public'
});
踏んだポイント:非同期 DDL / スキーマ変更 / JSON 型
DSQL の互換だけど違う部分はこの辺です。
非同期 DDL
まず非同期 DDL です。インデックス作成などがジョブ化される前提だと、マイグレーションは「流して終わり」ではなく、「完了待ち」「失敗時のリトライ」「並行実行の制御」が必要になります。
スキーマ変更
次にスキーマ変更です。ALTER TABLE ADD COLUMN 自体はできても制約付きで一気にやれないなど、段階的移行が前提になることがあります。NOT NULL / DEFAULT / CHECK を追加と同時に適用できない前提の設計が必要です。
JSON 型
そして JSON を列型として持てません。そのためレコードには TEXT で保存して、クエリ時に ::jsonb キャストして扱います。SQL の表現力はあるけど、ストレージ表現が違います。
イメージ:SELECT * FROM threads WHERE (metadata::jsonb)->>'plan' = 'pro';
これらは「DSQL を使うならアダプタ層で吸収して、アプリ側には普通のストアに見せる」のが設計として重要です。
踏んだポイント:サイズ上限
DSQL にも TEXT/bytea や行サイズの上限があり、ツール結果で上限を超える場合があります。ただし、DSQL はおよそ 2MB 上限なので、DynamoDB の 400KB の制限よりもかなりゆるいのが救いです。PR を送っている @mastra/dsql はオフロード機能は未実装なので、今後対応できたらと思っています。
踏んだポイント:楽観的同時実行制御(OCC)
DSQL は競合すると SQLSTATE 40001(serialization error)で失敗するケースがあります。
ここは「失敗で終わり」ではなく、再試行前提で設計しました(Exponential Backoff + Jitter)です。実装はアプリに散らさず、アダプタに閉じ込めています。
Round 3 結論
DSQL のまとめです。
-
DynamoDB の辛い部分の柔軟な検索・集計は SQL がやりやすいです。
-
Aurora v2 の悩みの待機/再開、運用の重さを軽くできます。
-
ただし、分散 DB の前提(非同期 DDL、JSON の扱い、OCC の再試行など)を織り込む必要があります。
そして大きい穴が pgvector が使えないことです。拡張が入れられないなら、Semantic Recall は DB 内で完結しません。
これを補うのが、次の S3 Vectors です。
補足:Amazon S3 Vectors
ここからは補足として、サーバーレス寄りの別サービスで Semantic Recall(ベクタ検索)を実現するために、S3 Vectors について詳しく見ていきます。
サーバーレスなベクタストアとして切り出す
DynamoDB も DSQL も、ベクタ検索はサポートしていないので単一の DB に同居できません。Aurora v2 だけが pgvector で同居できます。同居できないなら、ベクタ検索だけ別にするアプローチを取る必要があります。ここで候補になるのが S3 Vectors です。S3 上のベクタに対して検索でき、メタデータの絞り込みもできます。1 index あたり最大 20 億 vectors(以前は 5,000 万だったのがなんと 40 倍)とスケールの上限も大きく、サーバーレス寄りに運用しやすい、という狙いです。
Mastra から使う:@mastra/s3vectors
ベクタ検索だけ切り出すときに、Mastra 側にストレージアダプタがあるかが重要です。当時公式のアダプタが無かったので @mastra/s3vectors を自作して、コントリビュートしました。
@mastra/s3vectors の使用例:
import { S3Vectors } from "@mastra/s3vectors";
const vector = new S3Vectors({
vectorBucketName: process.env.S3_VECTORS_BUCKET!,
clientConfig: { region: process.env.AWS_REGION! },
// 大きいテキストは filter に使わない(容量と制約対策)
nonFilterableMetadataKeys: ["content"],
});
const memory = new Memory({ vector });
詳しくは、以前私が書いたブログ「
Introduction to @mastra/s3vectors
」で解説していますので、是非ご一読ください。
課題:Semantic Recall は「単一 index 前提」
ベクタ DB を導入しても、運用で問題になるのがテナント分離です。SaaS ならなおさらですね。 しかし、Mastra の Semantic Recall が単一 index 前提の設計になっているので、セキュリティ要件や、大規模運用で index を分割したい要件に対応しづらいという課題があります。
回避策:RequestContext で Memory を差し替える
回避策として、リクエストの文脈から userId や tenantId といった属性の情報を受け取り、Memory を動的に生成して保存先を分ける、という手があります。しかし、これだと、いちいち新しいバケットが必要になるので、インデックス単位で選択する仕組みが欲しいところです。(なので Mastra 本体に提案したいと思います。)
回避策のイメージ:
new Agent({
memory: ({ requestContext }) => {
const tenantId = requestContext.get<string>("tenantId");
return new Memory({
vector: new S3Vectors({
vectorBucketName: `my-vector-bucket-${tenantId}`, // バケット単位
clientConfig: { region: process.env.AWS_REGION! },
}),
});
},
});
まとめ
比較マトリクス
次の表は「どれが強いか」より「どこにコストが乗るか」の整理です。DynamoDBは回避策が積み上がり、Aurora v2は待機/運用、DSQLは分散前提の吸収、という見立てです。
-
DynamoDB:待機コストと初回応答は強いが、検索/分析とベクタ検索で別サービス。DB の制約による回避策が多く、実装コストが積み上がる。
-
Aurora v2:検索/分析とベクタ検索まで同居できるが、auto-pause 再開遅延や DB 運用が乗る。
-
DSQL:SQL を持ちながら従量寄りに寄せられるが、ストレージアダプタで分散前提の吸収が必要(@mastra/dsql がマージされるとこの辺りが解消される)。ベクタ検索は別サービス。
| 観点 | DynamoDB + S3 Vectors | Aurora v2 + pgvector | DSQL + S3 Vectors |
| 待機コスト | ◎ | △(0 ACU/再開遅延) | ◎ |
| 初回応答 | ◎ | △(再開が課題) | ◎ |
| 検索/分析 | △(設計必須) | ◎(SQL/JSONB/集計 | ○(SQLだが制約あり) |
| 実装コスト | 高(回避策多め) | 小 (接続/運用が焦点) |
小(@mastra/dsql) |
| 運用コスト | 低 | 中(バージョンアップ) | 低 |
| Vector検索 | ○(S3 Vectors補完) | ◎(DB内完結) | ○(S3 Vectors補完) |
要件別・構成パターン
最後は要件別・構成パターンをまとめます。
-
A. SQL で分析・運用しつつ、寄せ先を 1 つにまとめたい
-
👉 Aurora Serverless v2 + pgvector
-
(検索、集計、JSON、ベクタを同居させやすい)
-
-
B. 運用コストを抑え、SQL を使用したい
-
👉 Aurora DSQL + S3 Vectors
-
分散 DB 側の制約は アダプタに閉じ込める(@mastra/dsqlがマージされたら楽)
-
-
C. 運用コストを抑え、まず動かしたい
-
👉 DynamoDB + S3 Vectors も候補
-
ただし 回避策(サイズ制限/Offload/別ベクタ/分析/ページング) は自前
-
A は「分析が大事」「構成を単純にしたい」。この場合は Aurora v2 + pgvector が一番素直です。改善サイクルを速く回せます。B は「運用コストを抑えたい」「SQL を使用したい」。この場合は DSQL + S3 Vectors。分散前提はアダプタに閉じ込めるのがポイントです。@mastra/dsql が Mastra 本体にマージされたらだいぶ楽になります。C は「まず運用を軽く始めたい」「まず動かしたい」。この場合 DynamoDB が候補でもいいと思います。ただし回避策が必要になったときの仕組みは自前です。
この 3 つは好みではなく何を優先するかで決まります。
ここまで、Mastra の Memory を前提にして、DynamoDB/Aurora Serverless v2(PostgreSQL)/Aurora DSQL を「どれが最強か」ではなく、「運用負荷を抑える」観点で比べてきました。AI メモリは 追記・更新・意味検索・肥大化・分析欲 が同時に来るので、ストレージの得意不得意がそのまま実装コストと運用コストに跳ね返ります。
まずは自分たちが優先したい軸を決めて、寄せる/分けるの境界を引くのが効果的かと思います。この記事が、その境界線を引くための材料になれば幸いです。
参考文献
-
Mastra Docs: https://mastra.ai/docs
-
DynamoDB item limit & S3 offload: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-use-s3-too.html
-
Aurora Serverless v2 auto-pause/resume: https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-serverless-v2-auto-pause.html
-
Aurora DSQL quotas/limits: https://docs.aws.amazon.com/aurora-dsql/latest/userguide/CHAP_quotas.html
-
S3 Vectors limitations: https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-vectors-limitations.html
-
S3 Vectors GA: https://aws.amazon.com/blogs/aws/amazon-s3-vectors-now-generally-available-with-increased-scale-and-performance/
