※このブログはヌーラバー Advent Calendar 2020の22日目の記事です。
目次
はじめに
どうもこんにちは。鶴田です。
ヌーラボではいわゆる縦割りの組織ではなくフラットな組織という考え方で組織活動が行われています。
フラットというと勘違いしそうですが、誰でも役員やプロダクトマネージャに好き勝手に物事を言えたり、やりたいことを強行できたりということではありません。フラットだからこそしっかりと他者へ説明する義務が発生し、同時に自分の発言や行動に責任を持つことが必要です。
こうして他者にフォロワーとなってもらい後押しを受けるということが前提で、誰にでも自分の考えを発信したり、やりたいことを実現する道が開けているということです。
そのための仮説検証を行うため、誰でも必要な情報にアクセスできるという環境はフラットな組織の前提となります。
この記事は、必要な情報に誰でもアクセスできるという環境を整えるために、2年ほど前から行ったAWS上でのデータ基盤の構築とその改善活動について段階を踏んで書きます。
データ活用の課題とアーキテクチャの変化
ここからデータ活用を初めてからぶつかってきた課題と、どのようにアーキテクチャを変化させて向き合ってきたかについての話になります。
課題1: データサイロ
データ基盤の構築を考え始めた当初、社内でのデータ活用の課題は大きく2点ありました。一つ目はデータサイロの課題、もう一つが分析の一元性の課題です。
まずデータサイロの課題と向き合うことにしました。データサイロというのは、データが組織境界を越えてしまうとアクセスできなくなってしまい、データの存在有無さえわからないという状態です。
具体的な状況を説明すると、各サービスのデータを分析するためにプロダクトの本番データベースにアクセスできる開発者にデータ抽出を依頼する必要がありました。しかしデータベースの構造は開発者でなければわからず、どのようなデータが存在しているかわからない、そもそも開発者の工数が無いなど、データを集めること自体が難しいという状況にありました。
この解消のためにまずデータレイクを構築し、各サービスの生データを収集しました。
そして収集したデータレイクに対し、クエリを発行することでデータレイクにアクセスできる分析者は各サービスのデータへ自由にアクセスすることができるようになりました。
この時点のAWS側の構成はこんな感じのとてもシンプルなものです。
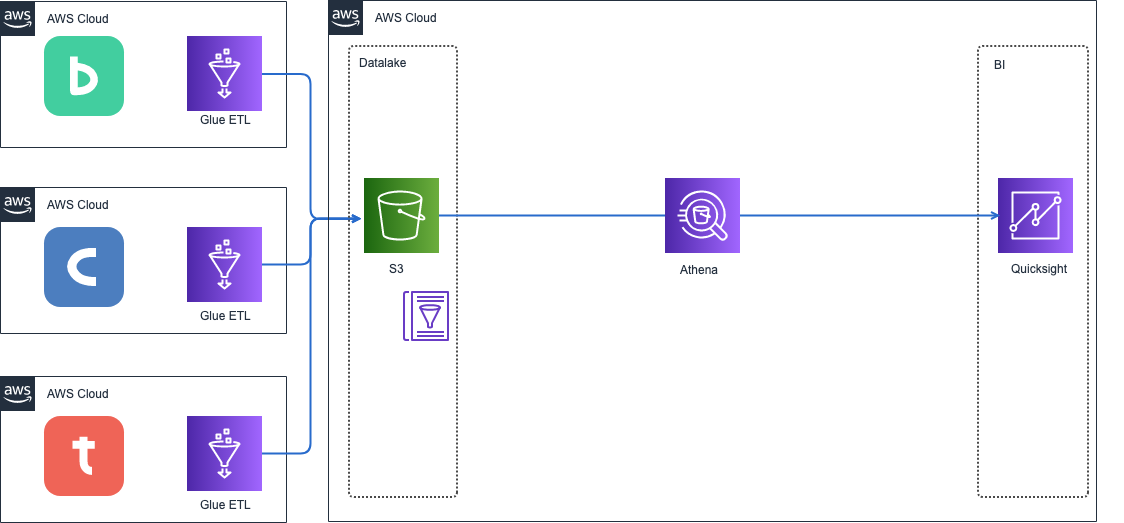
見てのとおりデータ基盤はAWSのマネージドサービスで構築しました。この構成を採用した背景について説明します。
他にもいろいろな構成を検討しましたが、データ基盤の構築は他プロジェクトの合間に行わなければならず、あまり多くのリソースをかけられないことが予想されました。
そこで当時はまだ事例は少なかったですが、ETLやデータカタログをマネージドで提供するAWS Glueというサービスを採用することにしました。
Glueで各サービスからデータを収集するETLを実装し、Amazon S3にロード、Glue CrawlerでS3をクローリングし、データカタログを作成し。最後にBIツールであるAmazon QuickSightがAmazon AthenaでS3にクエリを発行した結果を表示していました。
この構成の特徴はとにかくコストが低いことです。フルマネージドサービスで処理時間単位の課金なのでEMRとは違い、サーバー費用やインフラのメンテナンスコストをさらに抑えることができます。また、Glue Crawlerがだいたいのスキーマ変更を吸収しますのでサービス間との調整コストも省けます。VPC内で実行できることでデータソースへの接続が容易なことも構築コストの削減に繋がります。
さらに、Athena は Redshift とは違い、クエリに対して課金されます。どの程度使われるかもわからないデータ活用をこれから始めようという段階として最適なものでした。
BIツールにはQuickSightを採用しました。当初、他社でよく採用されていたTableauやLookerなどを考えていました。しかし、前提で説明したように、誰でも必要な情報にアクセスできるという環境を整えるために全員分のアカウント発行が必要となりました。
TableauやLookerを全従業員に対しアカウント発行するということは現実的ではありません。ありえない料金がかかりますし、仮に高い費用を支払い全員分発行したとしても実際に使う人数は限られるだろうと考えました。その点、Quicksightは1ユーザーの料金が極めて安価で、さらにあまりアクセスしないユーザーにはあまり料金がかからないようにプラン設計されていました。
もちろん、SPICEやAthenaとの接続、データガバナンス関連の機能など、他の要素もありましたが、一番の決め手はやはりユーザー人数に対する料金が桁違いに安いことでした。最初は機能に物足りなさを感じていましたが、今では、ML Insightsや発表されたばかりのQuickSight Q など新たな機能も増え、仮に再構築するとしてもやはりQuickSightを第一候補にと考えると思います。
データ基盤構築自体はマネジメントコンソールからGUIでポチポチするだけだったので構築は2ヶ月ほどで完了したように記憶しています。
課題2: データの一元性(データカオス)
ダッシュボードに情報を表示して全従業員に公開するための最初のステップが実現しました。
次に取り組んだのが一元性の課題です。データを欲している人は、いろんな方法やルートでいろんな式を使って計算していました。
例えばアナリストに「一言でユーザー数を教えて。」と依頼した場合、人によって様々な数字を出して来るでしょう。
ある人はトライアル中のユーザー含めてカウントするでしょう。ある人は解約済みのユーザーは取り除くでしょう。ある人はEメールの同一性などを確認し、同一人物の重複を除いてくるかもしれません。ある人はいま時点の人数かもしれませんし、先月末時点の人数を持ってくる人も居ると思います。
このため指標の定義のズレ、計算式のズレなどを取り除く必要があります。しかし全員の認識をあわせることは難しいです。
賛否は有ると思いますが、まず独自のデータ分析を行わないように働きかけ、数字の乱立がこれ以上進まないようにお願いしました。
データを構造化データに変換し、適切にモデリングされたデータウェアハウス(DWH)のレイヤーを配置し、ダッシュボードは必ずデータウェアハウスの内容を表示するようにしました。
これにより、計算式の一元性は担保されるようになりました。
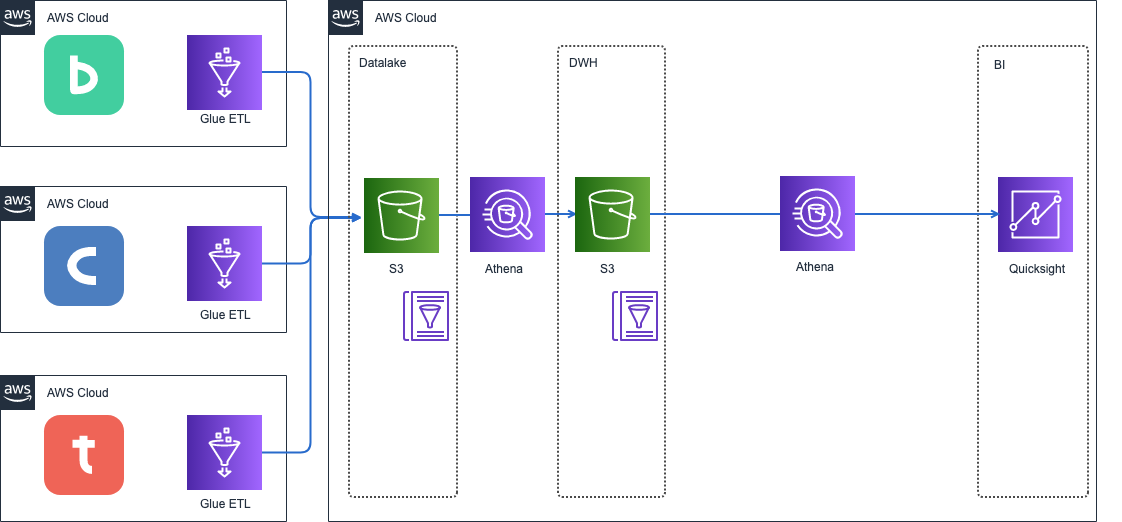
課題3: バッドデータ(データ品質の低下問題)
データ活用を進めていくと、また新たな課題が表に出てきました。それがバッドデータの問題です。
バッドデータというのは私達をとにかくイライラさせるデータという定義のようです。
特に困ったのはデータの完全性です。
ヌーラボのサービスは幸いなことにリリース依頼長い期間ユーザー様にご利用していただいています。その間にはサービスを成長させるためにたくさんの改善や、ユーザーからの要求に応えるために例外的な運用を繰り返してきました。
そのこと自体はめっっっちゃ素晴らしいことだと考えています。しかしその速度にデータはついていくことができませんでした。サービス開発側はデータの場所は教えてくれますが、そのデータのライフライクルやデータ欠損、さらにはいつ時点からデータが入り始めたか、どのように運用されているかなど、細部まで把握しているとは限りません。
そもそもサービス側に溜まっているデータは分析のために用意されたものではなく、システムを動かすために用意されたものなのです。渡されたものは期待している通りのデータだと考えず、データ自体を疑ってかかる必要があります。
データを入手したら分析を始める前にデータの品質について調査すべきです。
確かにビッグデータという資産はどの会社にも眠っているとは思いますが、データが完全なものだと思って分析を行うと誤った分析結果を作り出し、誤った意思決定へ導いてしまいます。
私達はデータの品質に確信が持てず、分析結果に対しても自信が持てないという状況が続きました。
そしてここで初めてデータマネジメントの必要性について気づくことができ、データマネジメントを学び始めました。データマネジメントの要素はたくさんあります。しかしアプリケーションを動かす上で必須の考え方ではなく、データエンジニアの前はアプリケーション開発者だった私にはとてもめんどくさく見えました。
面倒な作業が嫌いな私は組織全体にいきなりデータマネジメントを強制してもうまくいかないと考えました。少しずつデータ活用の価値と、そのためのデータマネジメントへの重要さを啓蒙することとしました。そうすることで各自が少しずつデータの品質について気にしてもらえるようになり、バッドデータが増えていく速度を緩めることができてきたと思います。
同時に、自分たちだけでできる対策としてBacklog上に誰でも参照できるデータカタログを用意し、どのようなデータであるかメタデータ管理を始めたり、Airflowを構築してジョブフローをコントロールすることでデータ基盤の更新を監視したりしました。
また、小さくできる対策として、課題の発見ごとにデータソースへの地道なデータ修正依頼を続けました。
この時点で、データカタログとBacklogによるメタデータ管理、Airflowによるジョブフローの管理が始まり、このような構成になりました。
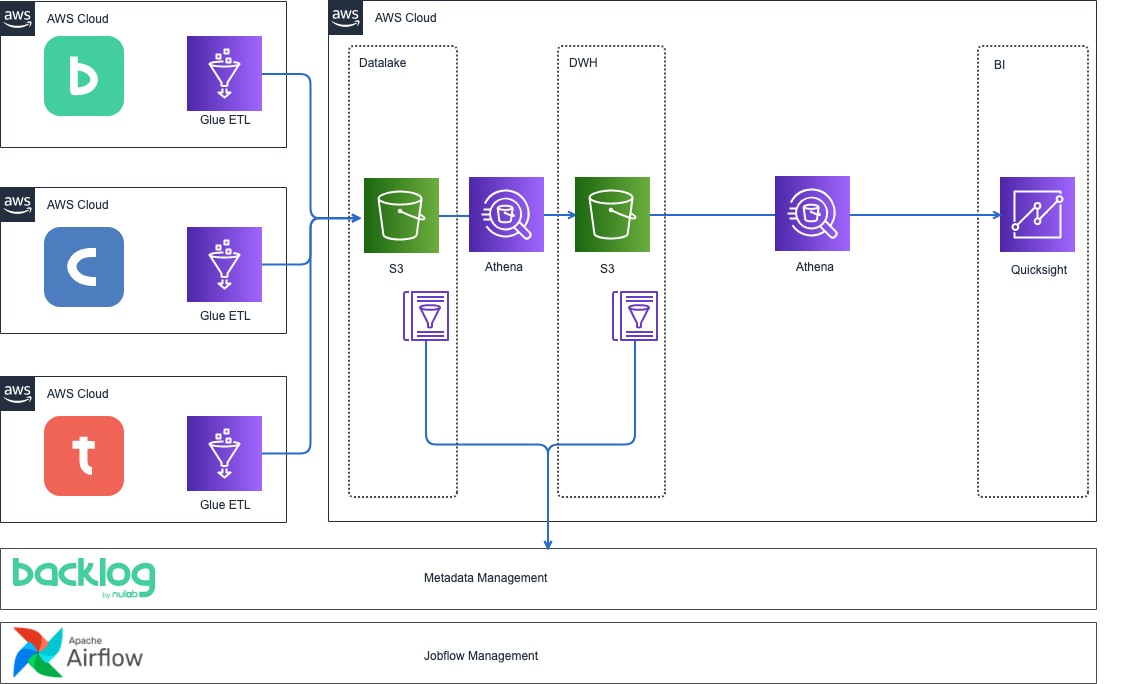
課題4: クエリの複雑さ
最後に出てきたのはクエリの複雑さとの戦いです。
バッドデータと戦っているうちに、DWHのデータロードクエリには欠損値の処理など様々な要素が組み込まれました。テーブルによっては数千行のクエリへと膨らみ、人の手ではクエリを変更することが困難になってきました。
しかし同時に、分析のデータ活用側からの要求も広がって来て、活用側の目的がたくさんクエリに入ってくる様になり、様々な目的で何度もクエリに手を入れ、構造を変更する必要がありました。分析者は自分の目的ではないカラム追加や構造の変更に対し注意を払う必要が出てきてしまい、同じDWHのテーブルを参照している公開済みのたくさんのダッシュボードを修正しなければならないようになりました。一つのダッシュボードを修正するとどこか別のダッシュボードがおかしくなり、メンテナンスは地獄でした。
このことについて、分析の一元性を考えすぎるあまり、DWHにすべてを押し込めすぎたことが原因だったと考えています。
DWHを基点にした一元性のため、ダッシュボードはDWHを参照することを推奨していました。
確かに欠損値やバッドデータの処理、計算式の定義などはDWHレイヤーで解消されていなければなりません。しかし部署や目的によって分析に必要なデータモデルは異なるため、部署や目的ごとのテーブルを作成しても問題無かったように感じます。
対策として、目的ごとのデータモデルを定義するレイヤーとしてデータマートを配置しました。
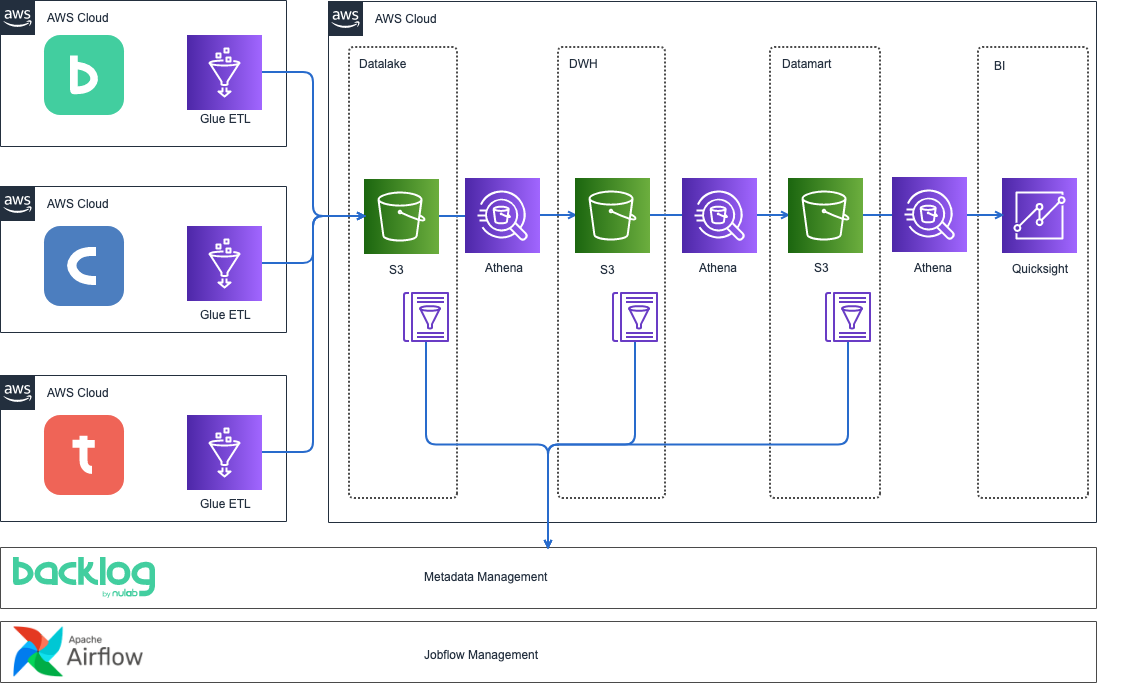
ディメンショナルモデリング
同時にDWHからデータマートを作成するにあたり、DWHのモデリングの失敗が表面化してきました。これはDWHを通常の業務アプリケーションのモデリング手法で設計していたためです。この時点でのDWHは明細データを中心に構成されており、データマートを作成するたびに集計ロジックを実装する必要が出てきました。
DWHのモデリングとして、ディメンショナルモデリングを採用し、スタースキーマの形に変更することとしました。
数を分析するには、数字と、数字の分析切り口のカラムがあれば、目的ごとのテーブルはDWHの切り口を追加削除するだけで良くなります。
ディメンショナルモデリングでは、数字をファクト、切り口をディメンションとしてテーブルを構成します。ファクトをスキーマの中心に配置し、その数字をグルーピングするディメンションテーブルと関連付けます。
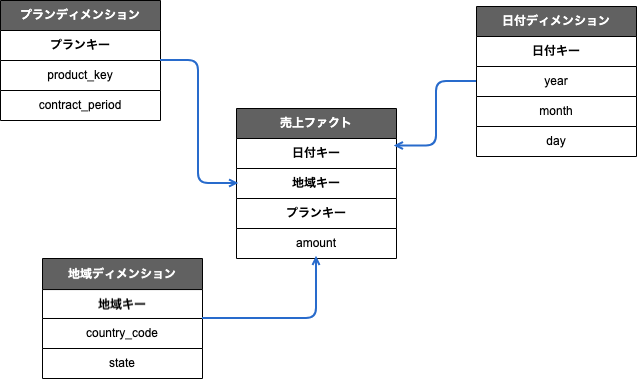
データマートはDWHのディメンションを調整して集計してロードすることで、DWH側の変更をデータマートが追わなくて良くなり、結果的にDWHや関係無いデータマートの変更の影響をダッシュボードがウケることがなくなります。
残念ながらこの対応は影響範囲が広く、一気に対応することは困難で終わっていません。少しずつ移行していく必要がありそうです。
ここまでがデータ活用を初めてからのデータ基盤の変化です。他にもIT統制のためのアクセス制御など、取り組んだ課題はあるけど、他の機会に書ければいいかなあ。
おまとめ
2年の間に表面化してきた課題に向き合うために、データ基盤がどのように変化してきたを書きました。回り道をしたかのように思うけど、最初から今の姿で構築することは難しかったかなーと思った。
まずはデータ活用の品質はどうあれ、始められる環境を用意し現状を知ることは大事。小さく失敗を積み重ねることで、データ基盤は少しずつ成長していっていると思う感じある。
少しずつだけど分析を見せられたことで社内のデータ活用での仮説検証という熱量を上げることができたと思うので何よりそれが良かった。
最後のポエみ
ここまでデータ基盤の技術的な部分を中心に触れてきた。しかし、テクノロジーだけでは解決できない問題がたくさんある。
データ活用を進める上で忘れてはいけないこと。データ活用の目的は何か。
それは優れた意思決定を行うため。
優れた意思決定には仮説を裏付ける質の高い分析結果が必要。
質の高い分析には、どのように活用するつもりなのかというデータ活用フロー、そして質の高いデータを蓄積するためのデータマネジメントこそが大切。分析する式やモデルを考えることが目的ではないんじゃないかなーという感じ。
しかしデータマネジメントを組織全体で情熱を持って取り組むことは難しい。特に歴史が長くなれば長くなるほど過去や現状を追いかけるためのコストは無限大!
例え質の低い分析であったとしても、データ活用へのモチベーションを上げ、より質の高い分析を求める文化を生み出すことが最終的にはデータマネジメントの成功、延いてはデータ活用の成功につながる。と、思う。たぶん。にわとりとたまごみたいな感じ。
今ならなななんとデータエンジニア募集中!
こちらから!
