目次
目次
はじめに
こんにちは。futahashi です。先日、4歳の娘が親の知らぬ間にお友だちと公園で会う約束をしてきました。しかし、この公園はかなり広く、連絡先 / 集合場所 / 集合時間が分からないという絶望的な環境下で、約束したお友だち全員と奇跡的に会うことができました。当たり前のようにある人間関係や技術のありがたみを感じますね!
ということで、今回は Datadog の Archive Search を使ってみたので紹介したいと思います。Log は誰しもが使う身近なものでありながらも設計が難しくコストが膨らみやすいところでもあり、今回のアップデートのありがたみを感じてくれる人も多いと信じています。
本記事では、信仰上の理由により AWS のみを例に扱います。ご了承ください。
TL;DR
- Archive された Log を Rehydration 不要で即座にストリーム検索可能
- 必要に応じて Rehydration も可能
- 時間や Attribute で Scan 対象を絞り込み可能
- 課金は Scan したデータサイズに依存
- Search 毎に最大 100k Event の検索結果を24 時間無料保持
- Rehydration しない場合の制約
- 集計や視覚化といった高度な分析はできない
- 他機能 (Dashboard / Notebook / Log Explorer など) からの参照ができない
何が変わったか
「3 週間前の Log を検索したい」 — この環境は Log Retention Periods が 15 日なのに。みたいなこと割とありますよね。そんな時、我々人類は以下のように対応してきました。
- ①Rehydrate を実行する
- Datadog の Rehydrate 機能を使って Archived Logs を Index します。バッチ処理で動き、Log が検索可能な状態になるまで数分から数時間必要です。また、Index 化するための課金も発生します。
- ②他のツールを使う (Amazon Athena など)
- 他の Archive Log 分析用のツールを使います。Datadog の優れた UI が使えず、調査効率が低下してしまいます。
- ③Log Retention Periods を見直す
- 次回以降に効く形になりますが、頻度によっては Log Retention Periods を見直すこともあるかもしれません。ただし、Index は Log Retention Periods に応じて課金額があがるので、投資対効果の判断が重要です。
そこで今回 GA した Archive Search の出番です。Rehydrate のようなバッチ処理待ち時間がなく、結果がストリームで逐次表示されます。実行前には最大 1,000 件の Archive Log のサンプルでクエリを Preview できるので、誤ったスキャンを走らせる前に Filter を確認できます。課金体系も Rehydrate と異なり、Archive Search は Scan 料金のみで Rehydrate による Index は任意です。そして、Archive Searchごとに最大 100k Event の Log を 24 時間無料で保持できます。Datadog で手軽に素早く賢く Archive Log を検索できるので、調査効率や料金節約の観点でも効果が大きいです。
まとめると以下のとおりです。
| 従来 (Rehydrate のみ) | Archive Search | |
|---|---|---|
| Log の取得 | バッチによる遅延処理 | ストリームでの高速処理 |
| 待機時間 | 数分から数時間オーダー | 逐次表示 |
| クエリの事前確認 | できない | 1,000 件のサンプルで確認可 |
| Index の必要 | 必須 | 任意 |
| 課金軸 | Index 料金、Scan 料金 | Scan 料金 (Rehydrate した場合のみ Index 料金) |
| 保持期限 | 3〜180 日 | 24h (Rehydrate した場合は3〜180日) |
| 保持イベント | 制限なし | Archive Search ごとに 100k Event まで 24 時間無料保持 |
| 用途の例 | Archive Log を 24 時間以上調査する時、高度な分析が必要な時 | Archive Log を単純に検索したい時、Rehydrate 前に賢く Log を絞り込みたい時 |
全体イメージ
Archive Search とそれに関係するものたちを表したイメージ図は以下のとおりです。これは私の愉快な脳内を図にしただけで、公式情報ではないので雰囲気を掴むためのものとして扱ってください。
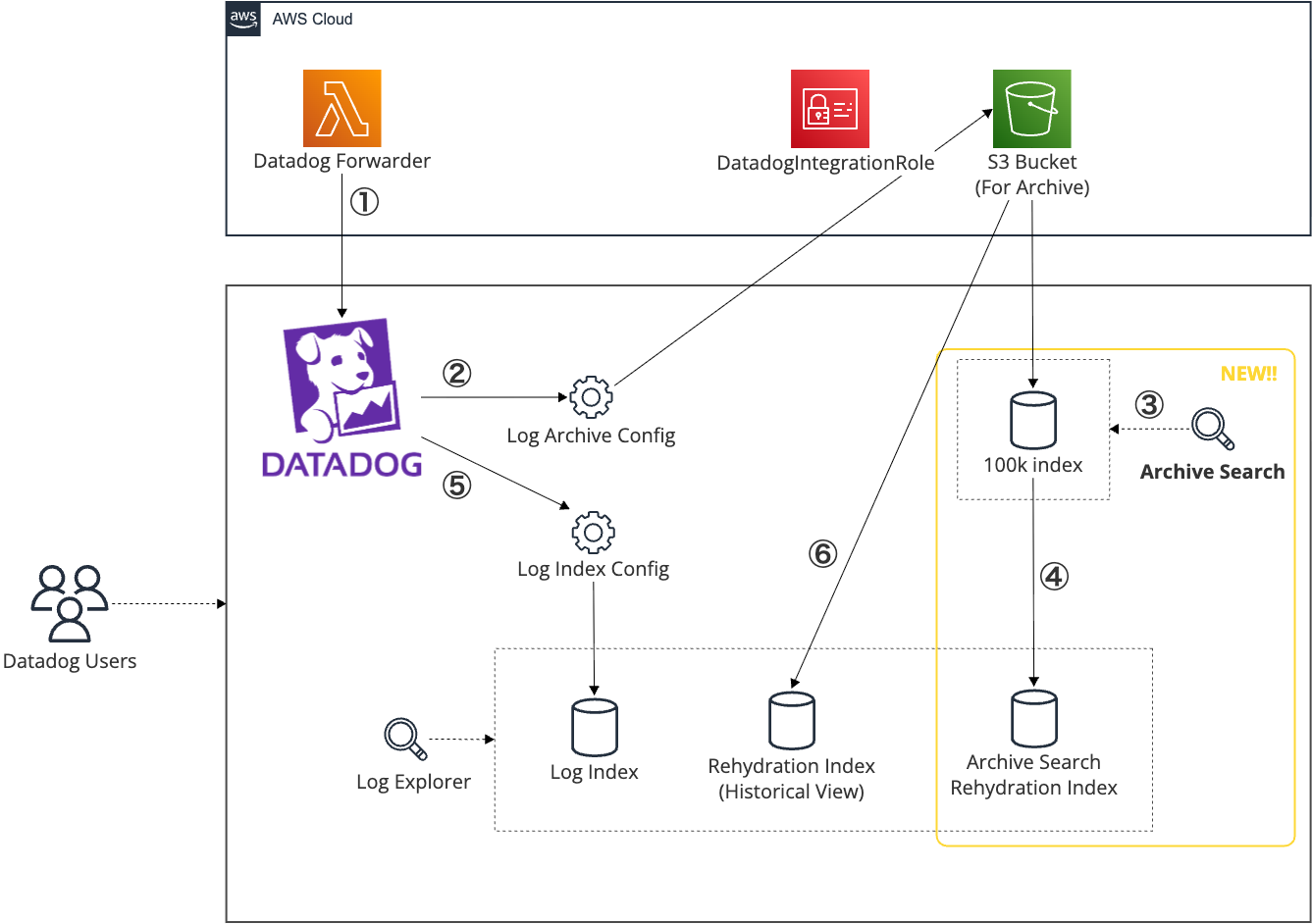
- ① Datadog Forwarder などから Datadog へ Log を Ingest します。
- ② Log が Ingest されたら、Log Archive の Config に基づき、Filter された Log を Archive 用の S3 Bucket へ送信します。この時、Datadog が利用する Role (通常 DatadogIntegrationRole) には S3 Bucket への読み書きを許可する Policy の付与が必要です。
- ③ Archive Search を実行すると、Archive 用の S3 から Log を取得し、最大 100k Event の Archive Search 用の Index に 24 時間保持されます。この Index は Log Explorer からは利用できません。
- ④ 必要なら Rehydration することで、Log Explorer から参照できる Index に保持できます。
- 補足
- ⑤ 通常の Log Index は Log Archive とは別の Config で Log を保持します。
- ⑥ 従来の Rehydration と Archive Search からの Rehydration を分けているのは、現時点では Archive Search から Rehydration しても Historical View には現れず、別物として扱っているようなのでそれに従っています。
やってみた
Archive Search を早速試してみたので、内容と学びを共有します。新規で Archive を作るところから始める想定なので、既に Archive がある場合は権限設定の箇所まで読み飛ばしてください。
S3 Bucket と IAM Policy の設定
はじめに、Archive の Log を保存するための S3 Bucket が無い場合は作成してください。Archive の Log の出力先は Path を指定することも可能なので、既存の何かしらの適切な Bucket を使うことも可能です。
次に Datadog の AWS Integration Role に S3 の読み書き権限の Policy を付与します。以下は設定例です。ご自身の環境に合わせて適切な Bucket name と Prefix に置き換えてください。
対象バケットの例
- Bucket name:
some-datadog-enthusiast-bucket - Prefix:
datadog/logs/
追加するポリシーの例
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DatadogUploadAndRehydrateLogArchives",
"Effect": "Allow",
"Action": ["s3:PutObject", "s3:GetObject"],
"Resource": [
"arn:aws:s3:::some-datadog-enthusiast-bucket/datadog/logs/*"
]
},
{
"Sid": "DatadogRehydrateLogArchivesListBucket",
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": [
"arn:aws:s3:::some-datadog-enthusiast-bucket"
]
}
]
}
Archive の設定
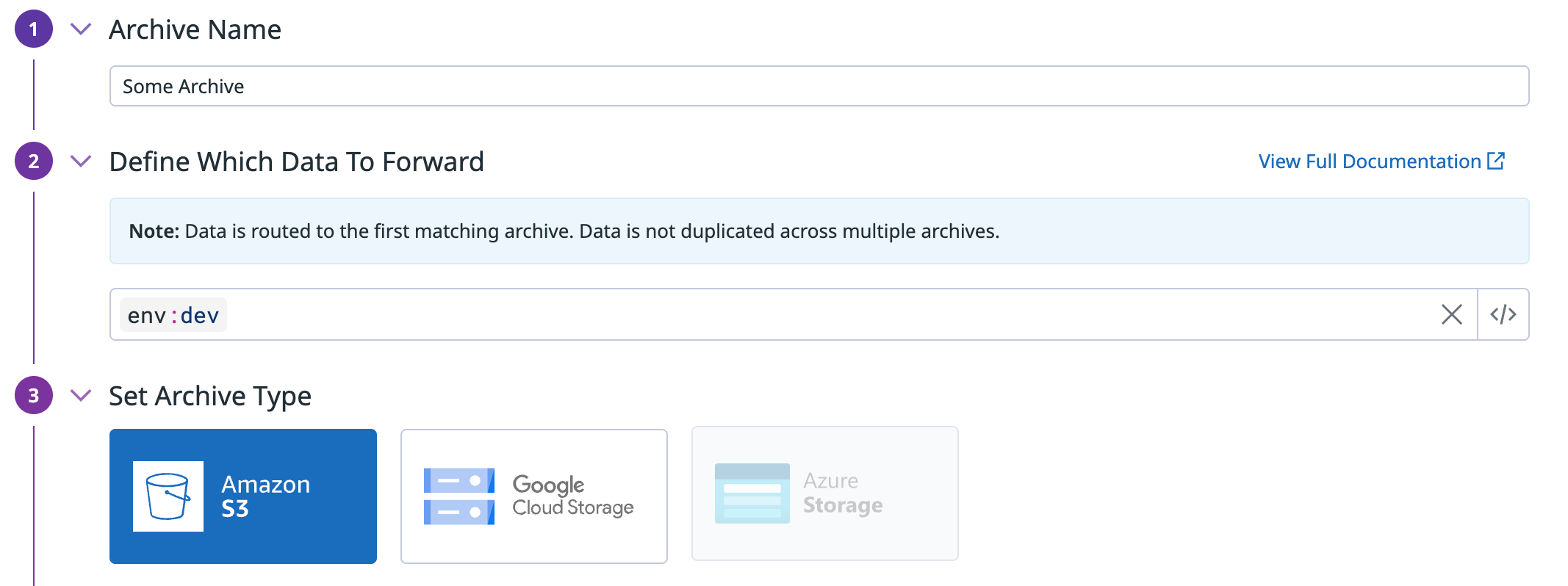
Archive を作成します。設定項目は以下のとおりです。
- Archive Name: Archive の名前
- Define Which Data To Forward: Archive として転送する Log の Filter
- Set Archive Type: Archive の種類 (Amazon S3 / Google Cloud Storage / Azure Storage)
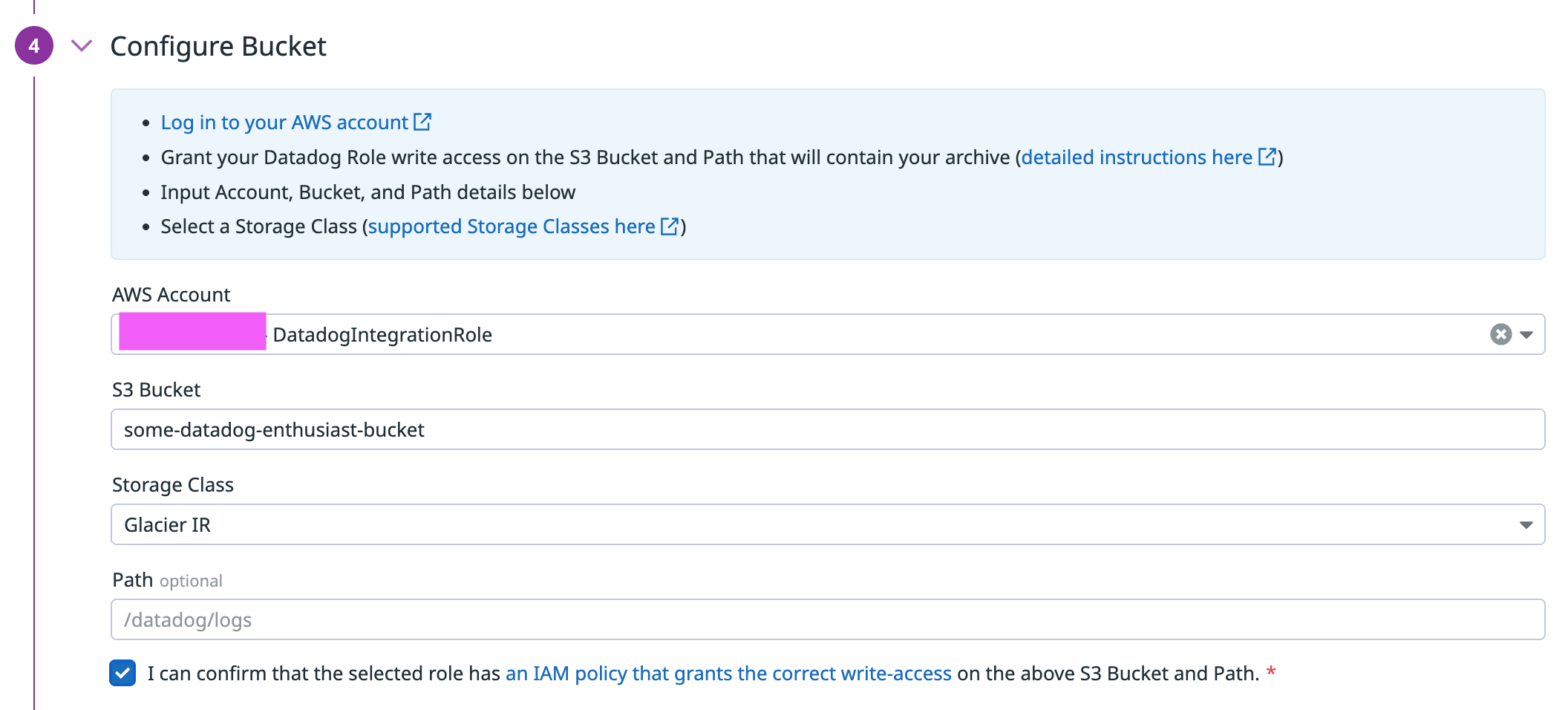
- Configure Bucket
- AWS Account: AWS アカウントと DatadogIntegrationRole の指定
- S3 bucket: Archive の S3 Bucket 名
- Storage Class: オブジェクトの Class (Standard / Standard IA / Intelligent Tiering / One Zone IA / Glacier IR)
- Path (Optional): 保存先の Path
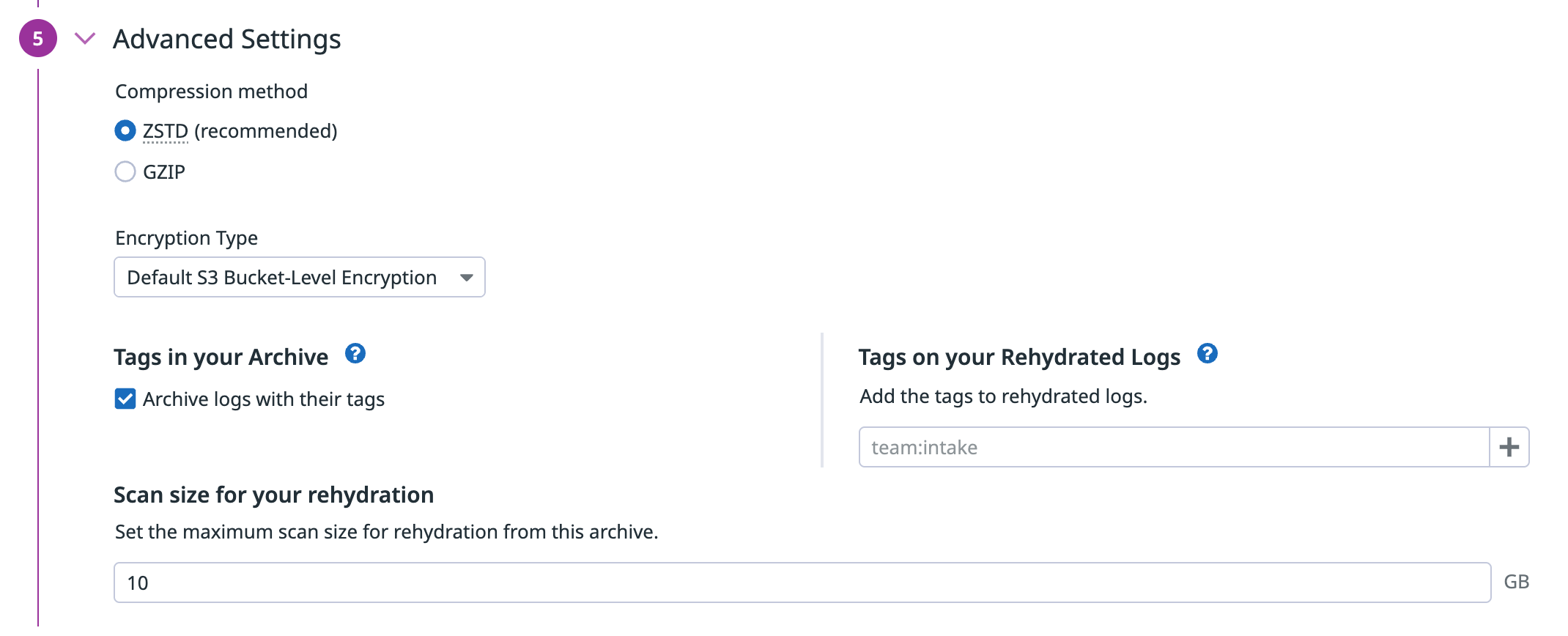
- Advanced Settings
- Compression method: 圧縮方法 (ZSTD / GZIP)
- Encryption Type: 暗号化の種類 (Default S3 Bucket-Level Encryption / Amazon S3 Managed Keys / AWS Key Management Service)
- Tags in your Archive: Datadog の Tag を Log に追加保存する設定
- Tags on your Rehydrated Logs: Rehydrate した Log に特定の Tag を付ける設定
- Scan size for your rehydration: Rehydrate の最大 Scan サイズの設定
Define Which Data To Forward で Archive として転送する Log の Filter が設定できるので、無駄な Log の Archive を防ぐことができます。
Compression methodでは、Archive Search や Rehydrate のみを目的とする場合、Scan と Egress のコストを抑えるため ZSTD が推奨です。他ツールとの併用が前提の環境では、GZIP も選択肢に入る可能性があります。
Storage Class と Encryption Type も指定できるので、ご利用の環境に合わせたコスト最適化や適切なセキュリティを実現できます。
Test Configuration を実行することで、Role が設定した Bucket に対して適切な読み書き権限があるか動作確認することができます。
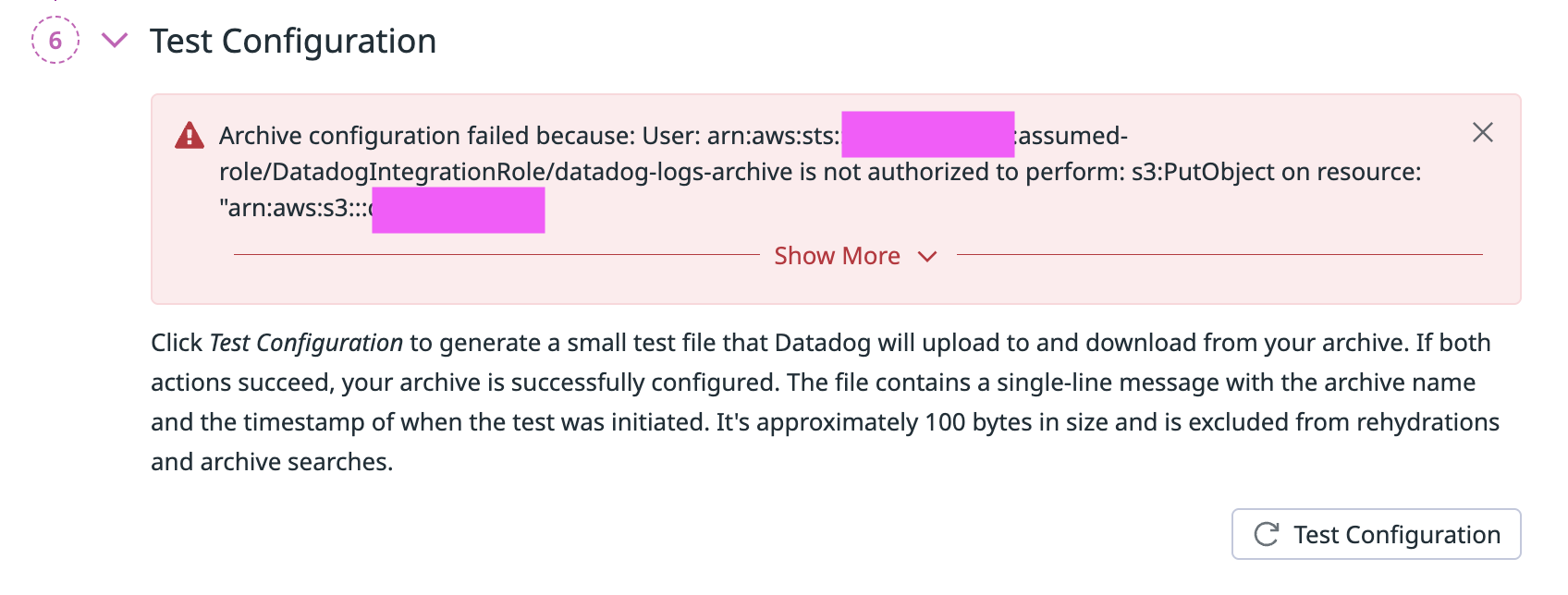
この他に、現在 Preview の Partition Attributes と Lookup Attributes という設定項目があります。これらは、属性でディレクトリ階層に分けたり、データブロック単位でスキップしたりして、Scan 量を抑えられる機能とされています。私は Preview の申請をしておらず試すことができなかったので、今回は割愛させていただきます。
権限設定
Archive Search を実行するには 2 種類の権限が必要です。利用に必要な権限を付与する設定をしましょう。
- ①Logs Write Historical Views: Archive Search 実行に必須な権限
- ②Logs Read Archive: Archive の読み取りに必要な権限
Datadog Admin Role、Datadog Standard Roleはこれらの権限を所持していますが、Datadog Read Only Role は Logs Read Archive しかないためご注意ください。また、Archive Search の結果は Restriction Queries が適用され、閲覧が許可されている Log のみを表示可能です。安心ですね。余談ですが、Datadog の RBAC のすべて が 5 分で分かる凝縮された資料を弊社の社員が作っているので、良かったら参照してくださいね。
Archive Search の実行
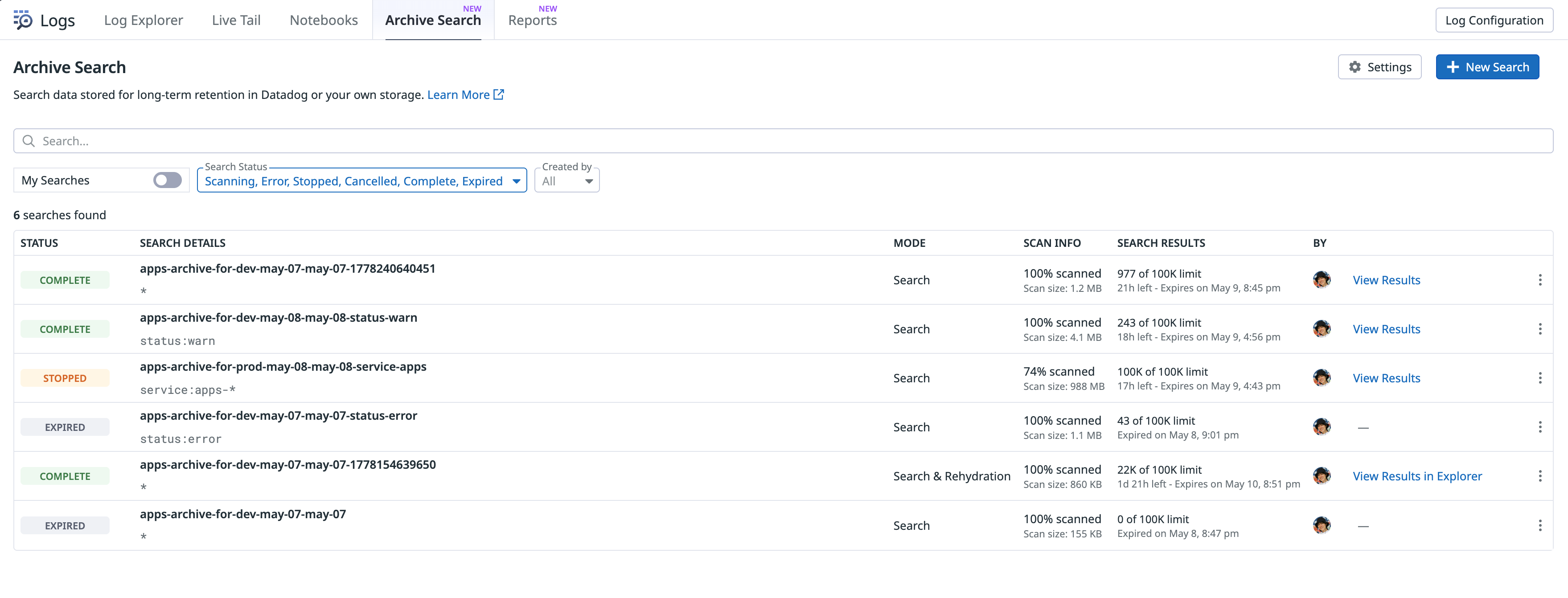
Datadog の左サイドメニューから Logs を選び、Archive Search タブに切り替えます。この画面では、Archive Search の設定、過去の Archive Search の一覧、新規 Archive Search の実行ができます。Archive Search の実行は、New Search ボタンで開始できます。
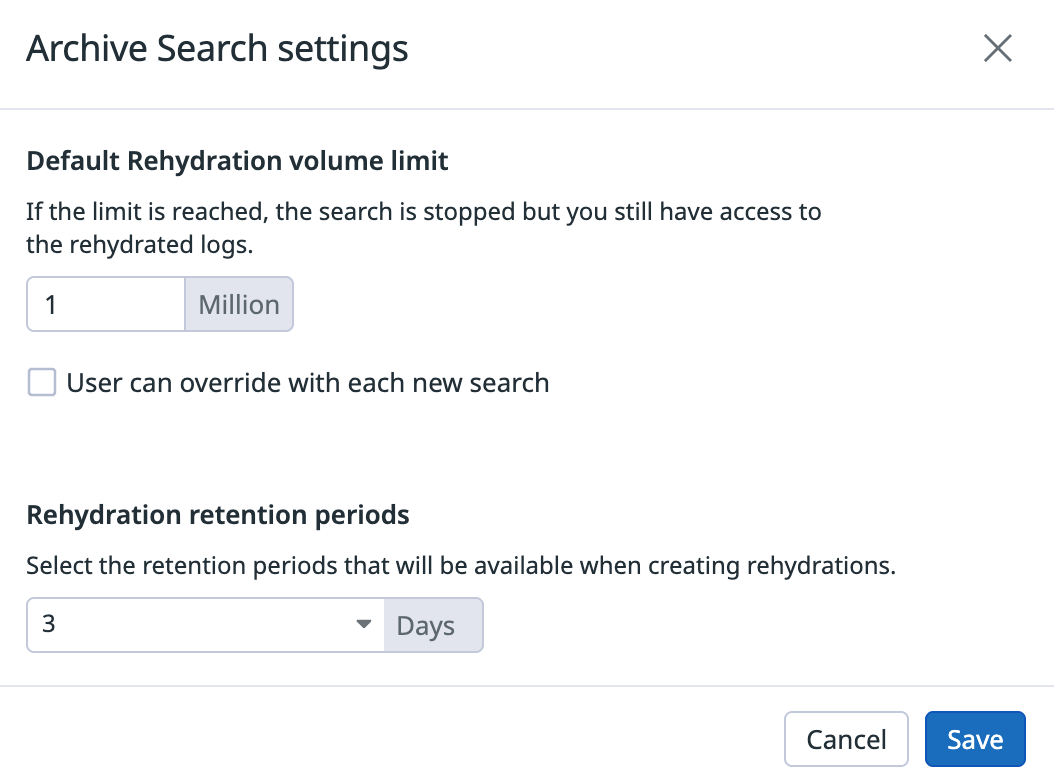
ちなみに設定では、以下のように Rehydration volume limit と Rehydration retention periods を決めることができます。
次に Archive Search の対象を選択するために、以下を入力します。
- Archive Name: 対象の Archive を指定します。
- Filter (Optional): 必要に応じて Filter を指定できます。Timeframe: 対象の期間を指定します。
- Mode
- ①Search: 最大 100,000 件まで無料で 24 時間一時保持
- ②Search & Rehydration: 3〜180 日 Indexing
Filter を指定することで、Rehydration 時の Index 料金を抑えたり、Preview 中の Lookup Attributes による Scan 量の削減が可能です。
Mode の選択基準として、軽量な検索で済みそうな用途の場合は Search、複雑な分析が必要な用途の場合は Search & Rehydration が良さそうです。また、Search を選んだ場合でも後から Rehydration することも可能なので、ご安心ください。
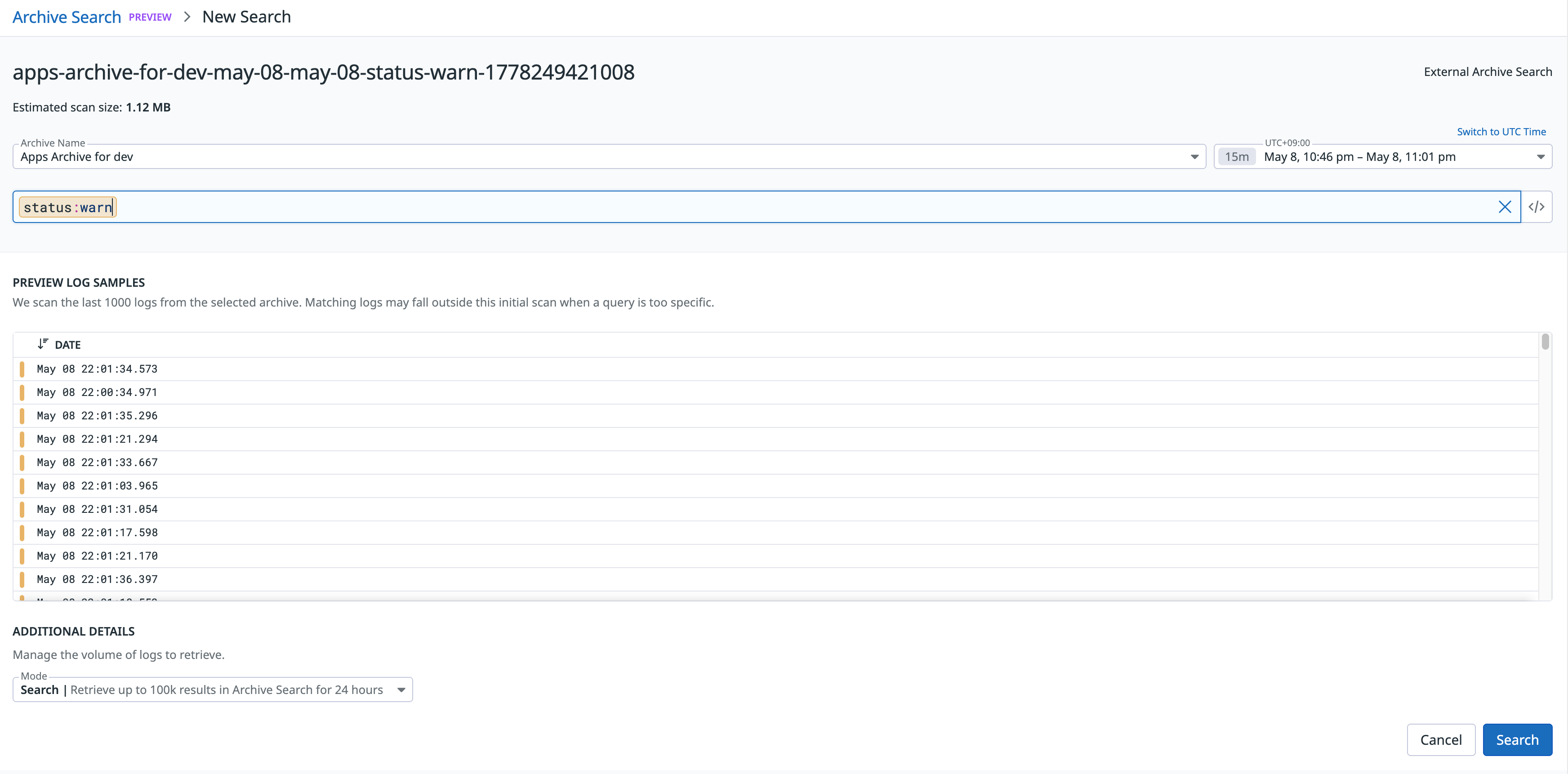
Estimated scan size を確認することで、実行前に Scan サイズの見積もりを知ることができます。また、Preview Log Sample では、対象期間の同一パーティションから最大 1,000 件 の Log を Preview できます。クリックして Log の詳細を確認したり、Filter の Query の妥当性を評価することができます。親切ですね!
Search を押すと Archive Search が実行されます。
Archive Search の確認
Archive Search を実行すると結果が逐次ストリームされ、Archive Log を素早く検索できる状態になります。Log Explorer とは異なる Archive Search 専用の画面です。集約などの分析はできませんが、Filter は利用可能です。
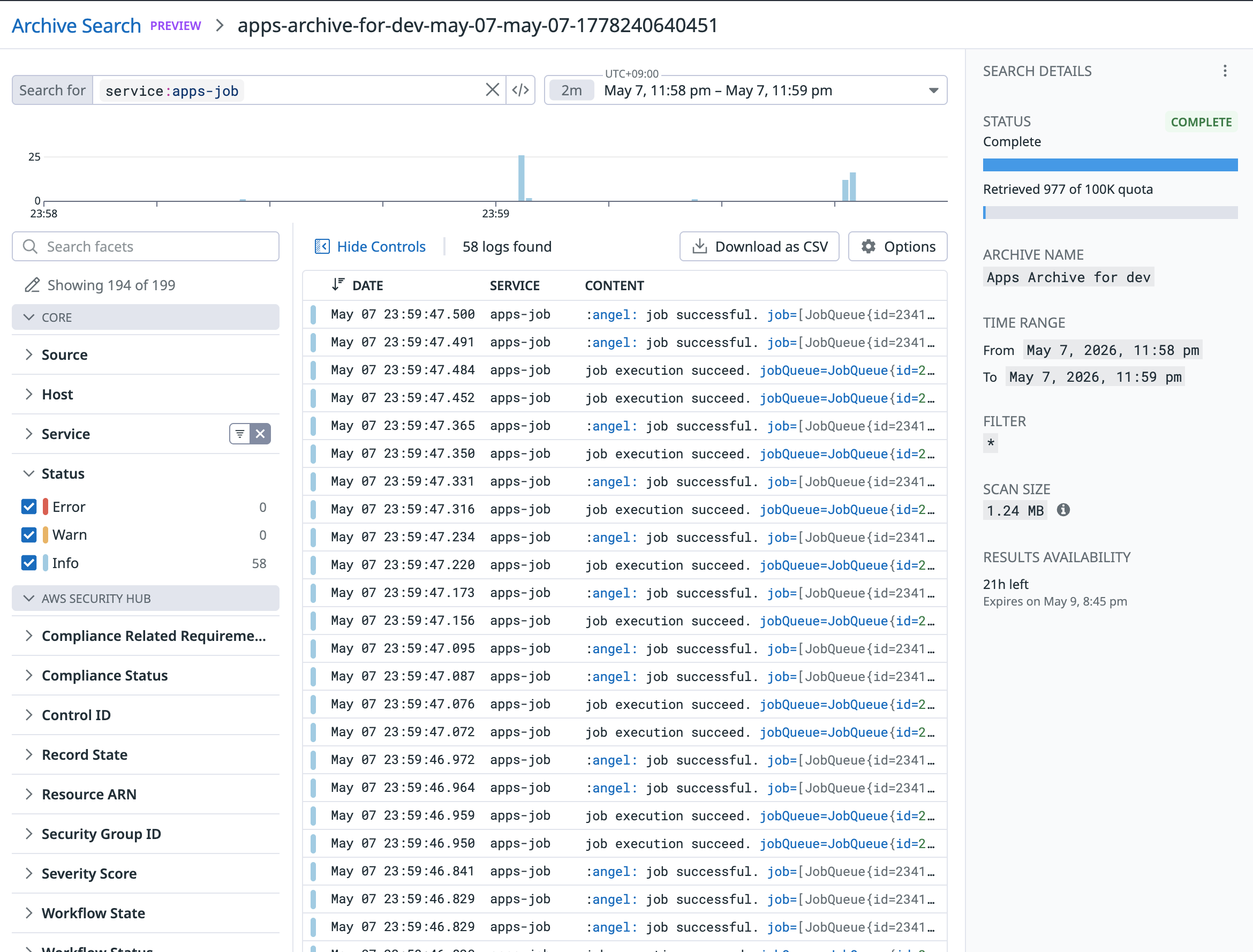
また、Options より Column の表示 / 非表示の変更が可能です。
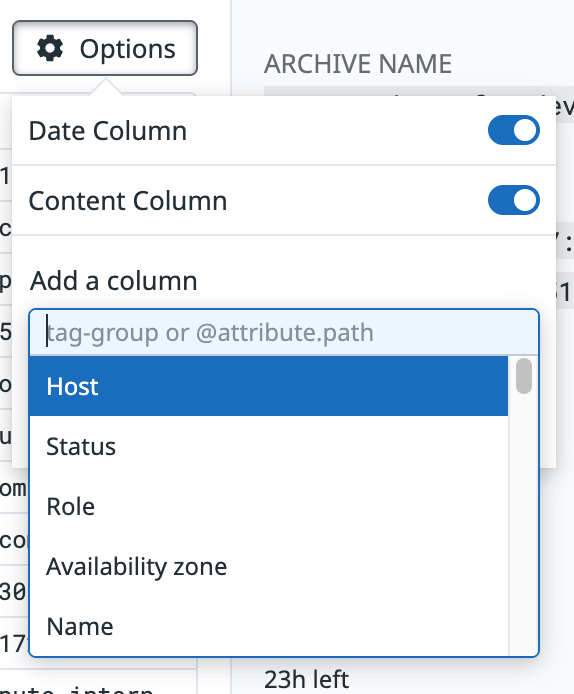
必要に応じて Rehydration を実行できます。Rehydration をすると Log Explorer での探索と分析が可能になります。複雑な分析がしたい場合や、一定期間の保存が必要な場合は Rehydration しましょう。
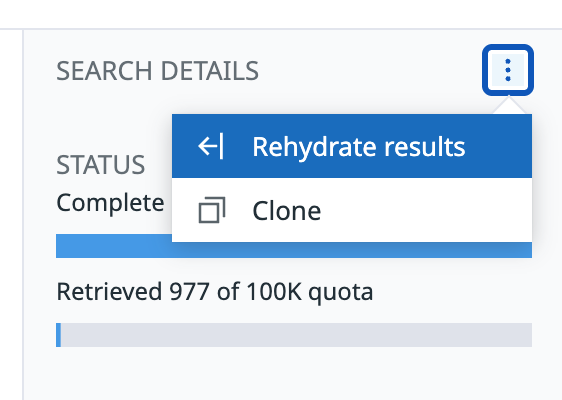
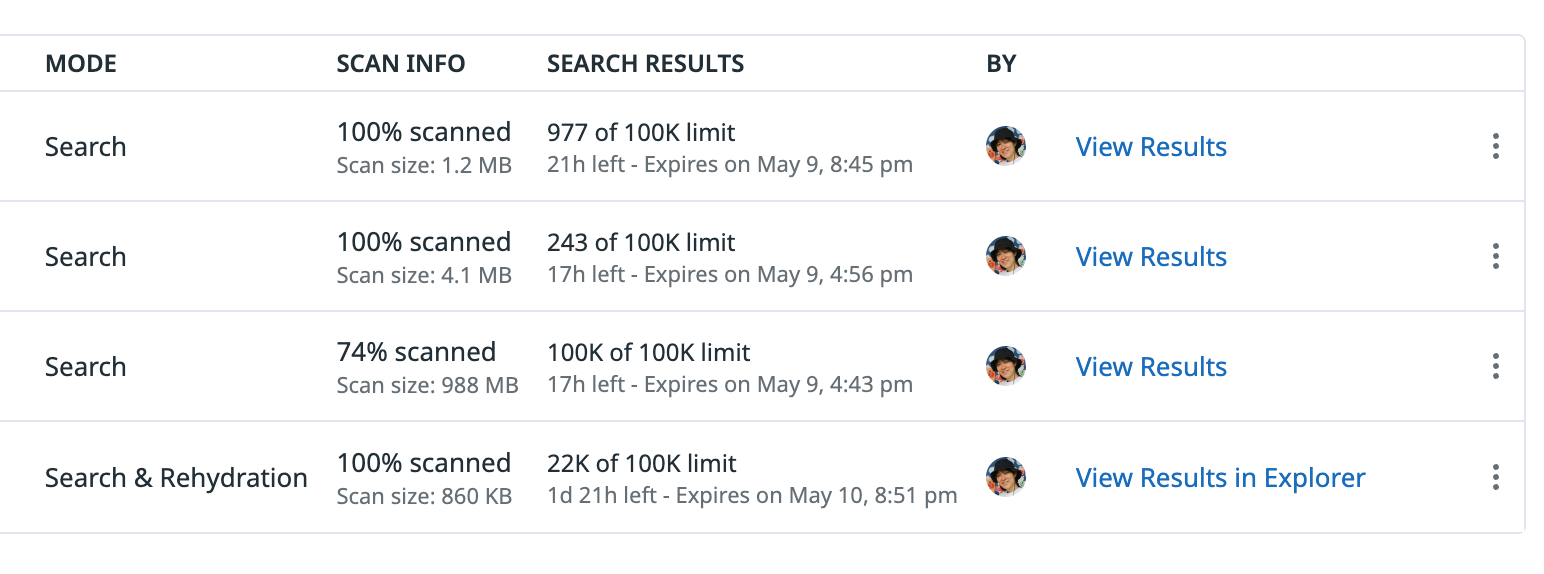
Archive Search と Rehydration の結果は、保持期間内なら Archive Search の画面からいつでも参照することが可能です。Rehydration を実行したものは、Explorer への Link も生成されて親切さを感じます。
補足と注意点
Archive Search の利用に関する補足と注意点を整理しました。
①集計 / 視覚化 / 他機能の連携はできない
Archive Search は Log Explorer とは異なる専用のビューを提供します。ここでは、Group by などの集計、Pie Chart などの視覚化、Datadog の他の機能 (Dashboard / Notebook / Log Explorer など) は使えません。これらをやりたいときは Rehydration のオプションを実行して Indexing する必要があります。
②Scan は S3 の同一階層単位で実行されていそう
Archive は以下のような構造になっており、hour 配下に複数の圧縮されたファイルが格納されます。
dt=YYYYMMDD/hour=HH/archive_*****
公式ドキュメントの記載は見つけられませんでしたが、 Scan は S3 の同一階層単位で実行される挙動のように見えました。つまり、1 時間分の圧縮されたデータすべてが Scan の対象になります。極端な例をあげると、00:00 – 00:01 の Scan と 00:00 – 00:59 の Scan サイズは同じで、00:59 – 01:00 は 2 倍のサイズということになります。ワークアラウンドとしてはよく利用する範囲に基づいた Archive 分割になりますが、実用上は大変なので Partition Attribute や Lookup Attributes に期待したいです。
③Query Preview は 1,000 件のサンプルデータ
Query Preview のサンプルには、Timeframe で指定された区間の同じパーティションに含まれる Archive のサンプル 1,000 件を表示するようです。前述の通りパーティションが 1 時間毎に切られるため、1 時間枠のうちのサンプル 1000 件ということになります。なので、この Preview は構文の検証と Archive の構造確認のための機能として扱い、Preview で 0 件だったから該当時刻でヒットしないと誤解しないようにご注意ください。
④100k Event で Scan が中断する
Archive Search の Scan は Scan 毎に最大 100,000 件で処理が中断します。指定した範囲を完全に取得したい場合は、結果を元に不要なLog を Filter で除外したり、Timeframe を絞ったりして 100k Event 以下に収まるよう調整し、再実行する必要があります。
再実行時は Clone 機能を使うと便利です。元の Search の Filter や Timeframe を引き継いだ状態でフォームに pre-fill されるので、必要な部分だけ修正して再投入できます。
⑤クラウド側の取り出しと転送料金が別途発生する
Scan 量に応じた Datadog 側の課金とは別に、S3 のコールドストレージからの取り出し料金や Datadog へのEgress はクラウドプロバイダ側で課金されます。
⑥Archive の設定は遡及適用されない
Archive の設定は、設定後にアーカイブされた Log にしか適用できません。過去にアーカイブされた Log には遡及して適用されないので、事前に設定しておく必要があります。
料金
概要
以下の価格表は執筆時点の AP1 の Ondemand 価格を参考に載せています。最新の正確な情報は公式の Datadog Pricing を参照してください。
| 項目 | 単価 |
|---|---|
| Archive Search | $0.07 / GB scanned |
| Archive Search の結果の一時 Index | 無料 (最大 100k Eventが 24 時間まで) |
| Rehydration Scan | $0.13 / GB scanned |
| Rehydration Indexing | Logs Indexing と同じ価格 |
| Logs Ingestion | $0.13 / GB ingested |
| Logs Indexing (15 day retention) | $3.19 / 1M log events |
| Forwarding to S3 / GCS / Azure (Archive 書き出し) | Logs Ingestion 料金に含まれる |
Archive Search は Scan したデータサイズに基づく課金となっています。現時点では Archive & Forwarding の Filter と Archive Search の Timeframe で Scan のサイズを絞る形になります。Preview 中の Lookup Attribute の設定ができるようになれば、Archive Search の Filter でも削減が可能になります。Archive Search も年契約があるので、一定量の利用が見込める場合はコミットによる割引を受けることができます。Archive Search の結果は最大 100,000 件のイベント保持が Rehydration 料金なしで24 時間利用できます。ありがたい!
Archive Log の書き出しに追加課金は発生しません。S3 / GCS / Azure Storage への Forwarding は Logs Ingestion 料金に含まれているためです。外部 SIEM や BI ベンダーなど Archive 以外の宛先への Forwarding は別途課金されるので、注意してください。
Rehydration の課金は 2 段階構造です。1つは圧縮された Log を Scan したサイズに比例します。もう1つはそれを Index した際の課金で、これは通常の Logs Indexing と同じ料金体系です。また、前述した Archive Search の Scan 料金の方が半額近く安くなっています。
料金比較の例
①15 Day Retention の場合
月 100 GB / 100M Log Events を生成し、Indexed Logs を 15 日 Retention で、S3 では約 10 GB と仮定します。
| 項目 | 計算 | 月額 |
|---|---|---|
| Ingestion | 100 GB × $0.13 | $13 |
| Indexing (15 Day Retention) | 100M × $3.19 | $319 |
| 合計 | $322 |
②7 Day Retention + Archive Search の場合
Archive Search を併用することで 7 Day Retention でも回せる運用になった場合を考えます。Archive Search をめちゃくちゃ使って 10 GB すべて Scan した場合でも以下の料金となり、約21%のコスト削減ができます。Indexing の占める料金の割合の大きさと Archive Search の料金の安さが分かりますね。
| 項目 | 計算 | 月額 |
|---|---|---|
| Ingestion | 100 GB × $0.13 | $13 |
| Indexing (7 Day Retention) | 100M × $2.39 | $239 |
| Archive Search | 10 × $0.07 | $0.70 |
| S3 Standard Storage | 10 × $0.025 | $0.25 |
| S3 Internet Out | 10 × $0.114 | $1.14 |
| 合計 | $254.09 |
③7 Day Retention + Archive Search + Rehydration の場合
同様の条件で、Archive Search したうち 10 %を Rehydrateした場合は、Indexing 部分が10%増えることになるため、以下のようになります。
| 項目 | 計算 | 月額 |
|---|---|---|
| Ingestion | 100 GB × $0.13 | $13 |
| Indexing (7 Day Retention) | (100M + 10M) × $2.39 | $262.9 |
| Archive Search | 10 × $0.07 | $0.70 |
| S3 Standard Storage | 10 × $0.025 | $0.25 |
| S3 Internet Out | 10 × $0.114 | $1.14 |
| 合計 | $277.99 |
極端に Archive Search と Rehydration を使い過ぎる例をあげてしまいましたが、実際には Scan する量は全量より圧倒的に小さいと思いますし、Rehydrate する Index も期間やクエリを活用することでかなり抑えられると思います。また Rehydrate の Day Retention も短い期間を選択することで更に安価にすることも可能です。
まとめ
本記事では Datadog Archive Search の使い方や注意点などを紹介しました。この機能は Datadog の従来の Index や Rehydrate の料金や時間などの課題を既存の機能を活かしながら解決し、多くのユーザーがコスト削減や業務効率化の恩恵をもたらします。
ユースケース次第では Log Retention Periods や、そもそも Indexed Logs に保持するか否かを見直すことができ、Index 料金を大幅に削減できます。また、Rehydrate の前段で賢く安価に使える便利な選択肢にもなります。過去 Log の当たりを付けてから、本当に必要な部分だけ Rehydrate することができるようになりました。
今後も安くて早くて賢い Datadog の強力な進化が楽しみです。
参考
- Datadog Docs – Archive Search
- Datadog Docs – Archive Partition Attribute (Preview)
- Datadog Docs – Rehydrating from Archives
- Datadog Pricing – Archive Search
- Datadog Pricing – How is Rehydration billed?
- Datadog Pricing – Is forwarding to S3 Archives, GCP Storage, and Azure Storage being billed?
- Search your historical logs more efficiently with Datadog Archive Search