明けましておめでとうございます。ヌーラボでソフトウェアエンジニアとして働いている@vvvatanabeです。今年もよろしくお願いいたします。
年末年始の長期休暇を利用して、昨年参加した AWS re:Invent 2024 のワークショップ「ARC401-R1 | Advanced cross-Region DR patterns on AWS」についてのレポートを書きました。このワークショップでは、災害復旧(DR: Disaster Recovery)に対応した高可用性アーキテクチャを設計する実践的な内容が扱われました。テーマとなったのは、トレードマッチングシステムを題材に、分散システムの設計や運用における課題と解決策を学ぶことです。
特に印象に残ったポイントとして、以下の内容が挙げられます:
- Route 53 ARC を活用した迅速なフェイルオーバーの仕組み
- クロスリージョン対応のデータストアとメッセージキューの選定
- Exactly Once Processing(厳密な1回限りの処理)を実現する技術
- 障害発生時の復旧フローとオーケストレーションのベストプラクティス
本レポートでは、このワークショップで学んだ知見をもとに、DR環境における分散システムのデータ整合性を維持しながら、高可用性を実現するアプローチについて解説します。特に、データの損失、重複処理、不整合といった特有の課題にどのように対処するかを具体例とともにご紹介します。
目次
DR環境の分散システムで直面する主な課題
分散システムは、現代のソフトウェア開発において不可欠な技術です。スケーラビリティや高い耐障害性を実現できる一方で、データ処理の整合性を維持することが難しいという課題があります。特に、災害復旧(DR: Disaster Recovery)を目的とした環境では、複数のリージョンやシステム間でデータの整合性を保つことが求められます。このような環境では、以下のような課題に直面する可能性があります。
データのレプリケーションと整合性の維持
DR環境では、プライマリリージョンとセカンダリリージョン間でデータをリアルタイムでレプリケートする必要があります。しかし、レプリケーション遅延(レイテンシ)が発生すると、両リージョン間でデータの不整合が生じる可能性があります。たとえば、プライマリリージョンで障害が発生した際に、セカンダリリージョンに最新のデータが完全に反映されていない場合、一部のトランザクションが失われたり、同じトランザクションが重複して処理されるリスクが発生します。
フェイルオーバー時のトランザクション管理
フェイルオーバーの際には、未完了のトランザクションがどの時点で中断されたのか、正確に把握する必要があります。プライマリリージョンで障害が発生した場合、セカンダリリージョンでどこから処理を再開すべきかを判断する仕組みが重要です。この仕組みが不十分だと、トランザクションが部分的にしか処理されない状態が発生し、結果としてデータの一貫性が損なわれる可能性があります。このような状況は、処理漏れや重複処理といった問題を引き起こし、システム全体の信頼性を低下させる要因となります。
トレードマッチングシステムの全体像
この記事では、具体的なイメージを持って理解を深められるよう、実際のワークショップで使用されたトレードマッチングシステムを例に説明します。
システム概要
トレードマッチングシステムは、証券取引を効率的に処理するためのバックエンドシステムです。このシステムはユーザーインターフェイスを持たず、パートナー企業のバックオフィスシステムと連携するAPIエンドポイントのみを提供します。
設計上、複数のマイクロサービスを連携させたマルチステップのデータ処理パイプラインを採用しており、スケーラブルで堅牢な構造を実現しています。以下の図に示すように、このシステムはAmazon ECSクラスタ上で動作する複数のマイクロサービスで構成されており、DR対策として2つのリージョンで冗長化されています。
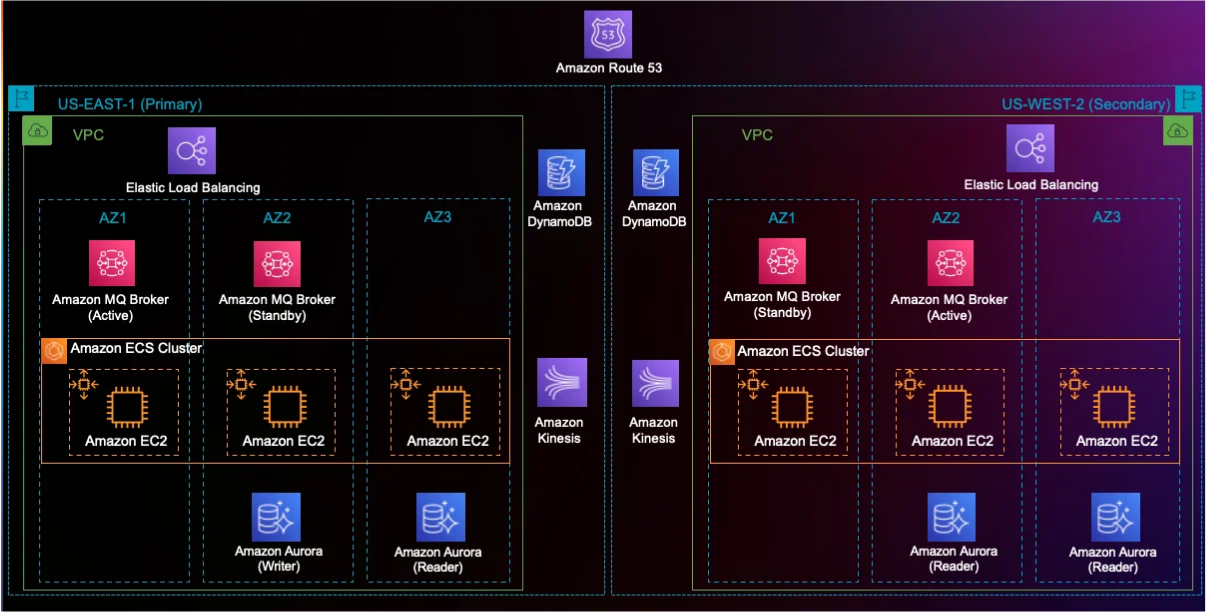
ワークショップの資料から引用した構成図
Route 53 ARCを活用したトラフィック制御
このシステムでは、Route 53 Application Recovery Controller(ARC)を利用してクロスリージョンのトラフィック制御を行い、障害発生時の迅速なフェイルオーバーを可能にしています。
具体的には、Route 53のフェイルオーバーレコードがプライマリおよびセカンダリのNetwork Load Balancer(NLB)のDNSレコードに関連付けられています。プライマリのヘルスチェック状態を監視し、異常が検知された場合には自動的にセカンダリへトラフィックを切り替えます。この仕組みにより、手動でDNSエントリを変更する手間を省き、迅速なフェイルオーバーを実現します。
公式ドキュメント:ARC とは?
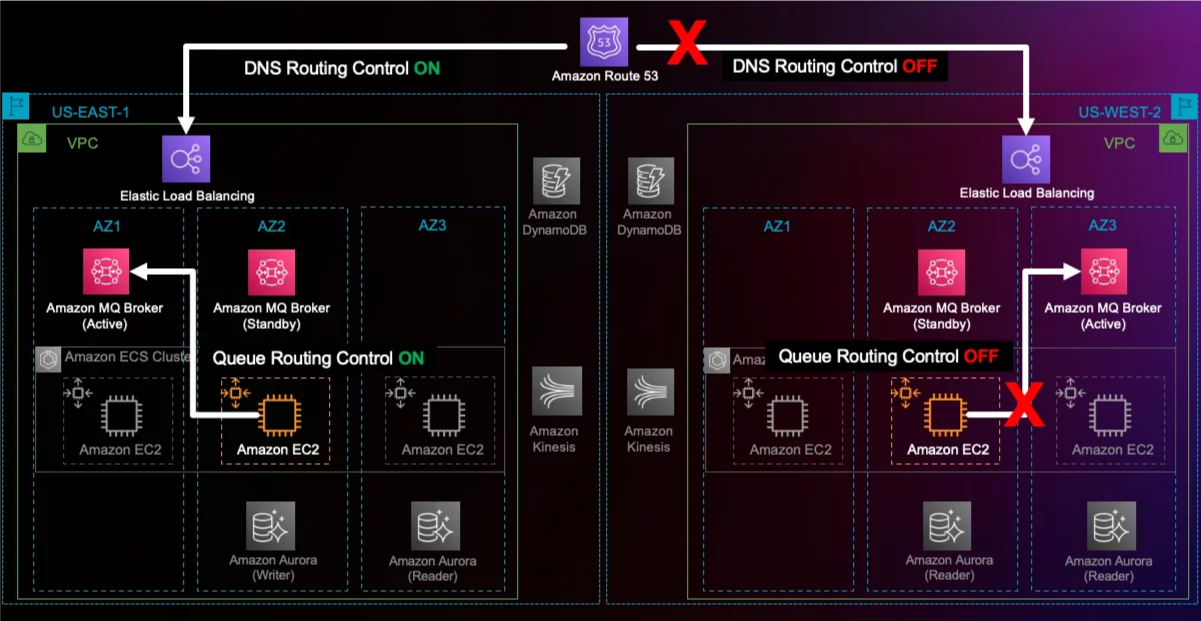
ワークショップの資料から引用した構成図
Amazon MQを活用した取引メッセージの入出力
取引メッセージの処理には、Amazon MQを使用しています。Amazon MQでは以下の役割を担う2つのキューを設定しています:
- Incomingキュー:取引メッセージの受信を担当
- Outgoingキュー:処理後の結果の送信を担当
さらに、Amazon MQのレプリケーション機能を活用し、これらのキューをセカンダリリージョンに自動的に複製することで、障害時にもメッセージを確実に利用できるようにしています。
公式ドキュメント:Amazon MQ の特徴
Amazon Kinesisを活用したローカルメッセージ転送
取引メッセージの処理は複数のマイクロサービスに分散して行われます。この際、Amazon Kinesisストリームをローカルメッセージキューとして使用し、メッセージを順序通りに次の処理ステージへ転送しています。これにより、データの整合性を維持しながら効率的なメッセージ処理を実現しています。
公式ドキュメント:Amazon Kinesis Data Streams
DynamoDBとPostgreSQLを活用したデータ保存
取引メッセージが処理されると、トランザクションのデータは次のいずれかのストレージリソースに保存されます:
公式ドキュメント:
これらのストレージはどちらも、セカンダリリージョンに自動でデータをレプリケートする設定が施されています。この仕組みにより、障害発生時にもデータの一貫性を保ちながらシステムの可用性を確保しています。
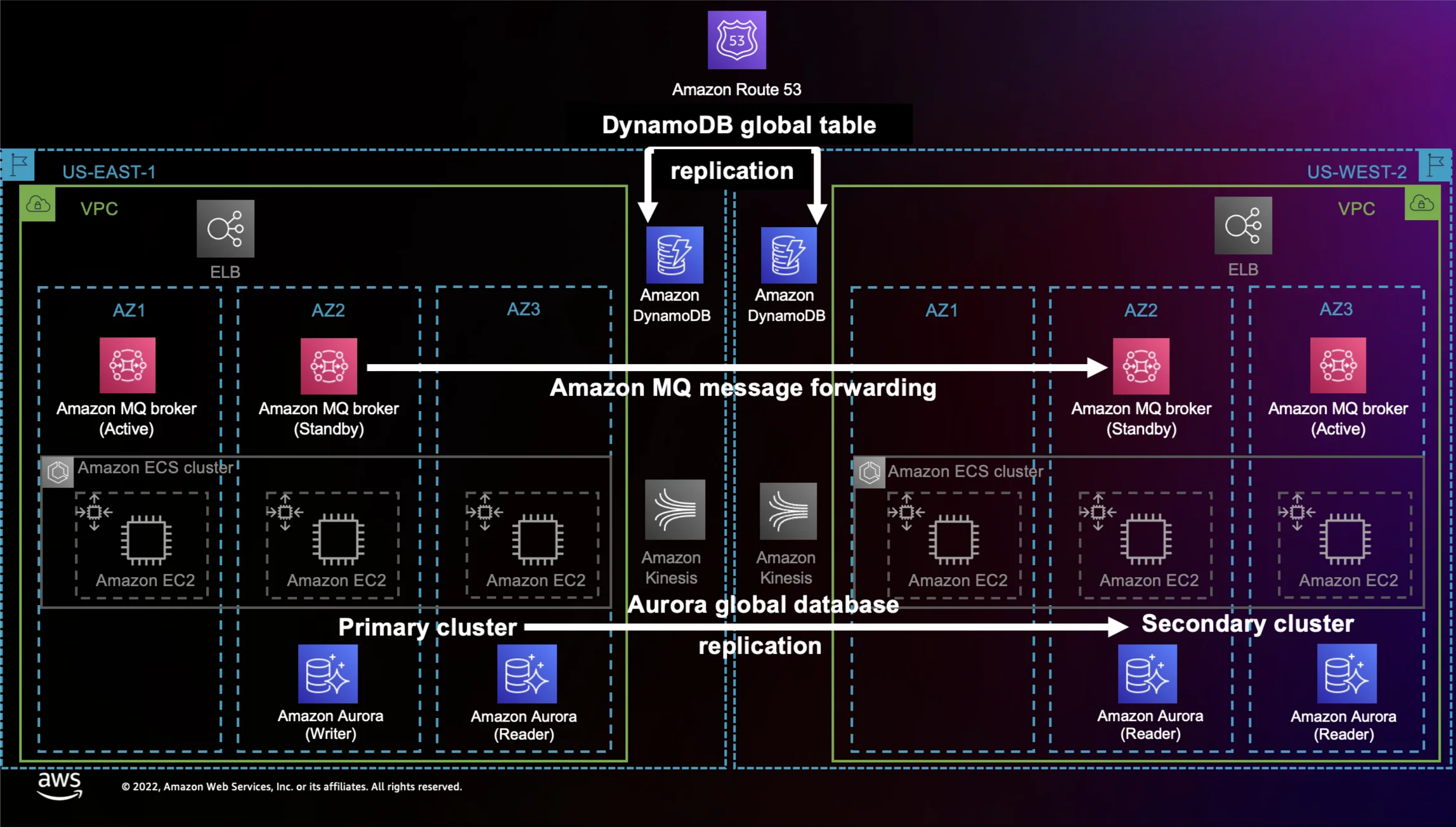
ワークショップの資料から引用した構成図
以上のシステムの構成により、分散処理の効率性とDR対策が強化され、信頼性の高いトレードマッチングが実現されています。
5つのマイクロサービスによる連携処理
以下に示すのは、システム内で動作する5つのマイクロサービスの概要です。これらのマイクロサービスは、マルチステップのデータ処理パイプラインによるデータ処理を実現しています。
各マイクロサービスは、受信したメッセージを処理し、その結果を Amazon DynamoDB や Amazon Aurora PostgreSQL に保存します。その後、Amazon Kinesis ストリーム を介して次のマイクロサービスにメッセージを伝播します。以下は、各ステージの詳細です。
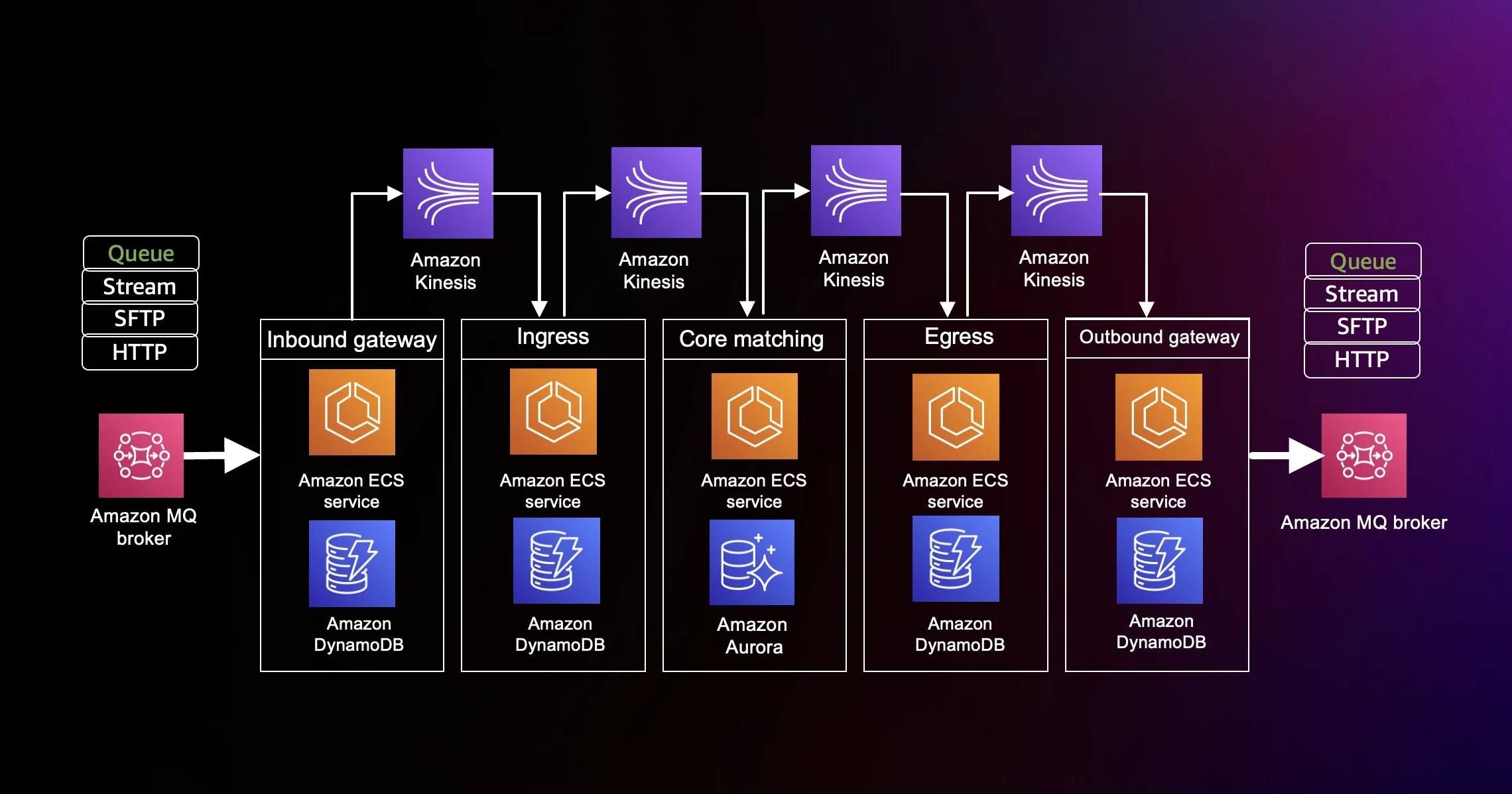
ワークショップの資料から引用した構成図
1. Inbound Gateway
このマイクロサービスは、データ処理パイプラインの起点です。以下のようなさまざまなプロトコル(Queue、Stream、SFTP、HTTP など)を使用して取引メッセージを受信します。本システムでは Amazon MQ を利用したキューを使用しています。
処理内容:
- 取引メッセージを受信し、DynamoDB に保存します。
- 保存したメッセージを Kinesis ストリーム を介して次のマイクロサービス(Ingress)に送信します。
2. Ingress
Ingress は、Inbound Gateway から送信されたメッセージを受信し、次の処理を行います。
処理内容:
- メッセージの正規化、メッセージの重要なフィールド検証を行います。
- 検証に成功したメッセージは Core Matching に送信されます。
- 検証に失敗したメッセージは、「否認(nack)」ステータスとして Egress に送信されます。
3. Core Matching
Core Matching は、取引メッセージのマッチング処理を担当します。
処理内容:
- 投資マネージャー、ブローカー、および取引IDを基にメッセージを比較し、以下のステータスを付与します:
- 「マッチ」:価格、数量、取引指標などの主要なフィールドが一致した場合
- 「ミスマッチ」:主要なフィールドが一致しない場合
- マッチしなかったメッセージは、取引データベースに保存されます。
- すべての取引メッセージ(マッチ済み、ミスマッチ、未処理)は Egress に送信されます。
4. Egress
Egress は、Core Matching から送信された取引メッセージを受信し、次の処理を行います。
処理内容:
- メッセージを正規化して保存します。
- 処理済みメッセージを Outbound Gateway に送信します。
5. Outbound Gateway
Outbound Gateway は、外部システムとの通信を担当します。
処理内容:
- 処理済みのメッセージを外部システムに送信します。
- 様々なプロトコル(Queue、Stream、SFTP、HTTPなど)で取引メッセージを受信することを想定しています。
- 本システムではAmazon MQのキューを使用しています。
以上、これらの5つのマイクロサービスが各ステージでの処理結果を安全に保存し、次のステージに伝播させる設計がデータの整合性を高めています。
分散システムにおけるデータ処理上の課題
トレードマッチングシステムでは、取引処理のトランザクションが複数のマイクロサービスに分散されることで、スケーラビリティや柔軟性が実現されています。しかし、この分散アーキテクチャには特有の課題も伴います。各マイクロサービスが独立して動作するため、データの整合性や信頼性を維持することが難しくなる場合があります。ここでは、分散システムにおける主なデータ処理の課題について具体例を交えて説明します。
データ損失のリスク
分散システムでは、障害やシステム設計上の問題により、データが途中で失われるリスクがあります。
- 障害発生時: サーバークラッシュやネットワークの切断によって、データが未処理のまま消失する場合があります。
- バッファのクリア: Kinesisストリーム内のデータが処理される前にクリアされることがあります。
具体例として、外部からデータを受信する Inbound Gateway が突然停止すると、一部のデータが次のステージ(Ingress)に渡らず、処理漏れが発生する可能性があります。
重複処理のリスク
分散システムでは、同じデータが複数回処理されるリスクも存在します。
- 再試行(リトライ): ネットワーク遅延や障害復旧後に、同じメッセージが複数回送信される可能性があります。
- メッセージの複製: Kinesisストリームなどのデータ配信時に、重複が発生することがあります。
たとえば、Core Matching ステージが1つのトランザクションを2回処理してしまうと、同じ取引データが複製され、清算データが重複して生成される恐れがあります。
データの不整合
複数のステージで処理されたデータの状態が一致しない「データ不整合」が発生する場合もあります。
- 障害復旧後の不整合: 再起動時に中途半端な処理で終了したデータが存在すると、データの整合性が損なわれます。
たとえば、Egress ステージで清算データが生成されても、Outbound Gateway にデータが渡されなければ、不完全な処理結果が残ることになります。
Reconciliation(再調整)とReplay(再実行)の仕組み
前述の分散システムにおけるデータ処理上の課題を解決するためには、障害や遅延、再試行(リトライ)など、さまざまな状況を考慮しながらデータの整合性を保つ必要があります。そのための重要な概念として、以下の3つが挙げられます。
- Reconciliation(再調整)
- Replay(再実行)
- Exactly Once Processing(厳密な1回限りの処理)
基本コンセプト
トレードマッチングシステムでは、各マイクロサービスが処理したメッセージを Amazon DynamoDB や Amazon Aurora PostgreSQL に記録しています。障害が発生した場合、セカンダリリージョンへフェイルオーバーし、隣接するマイクロサービスのデータベースを比較することで未処理のデータを特定します。その後、再実行(Replay)を行うことで、データの整合性を復旧します。
障害発生から復旧までの流れ(具体例)
以下は、障害発生時のデータ処理の流れです。
1. メッセージの発行:
100件の取引メッセージが Amazon MQ に送信されます。
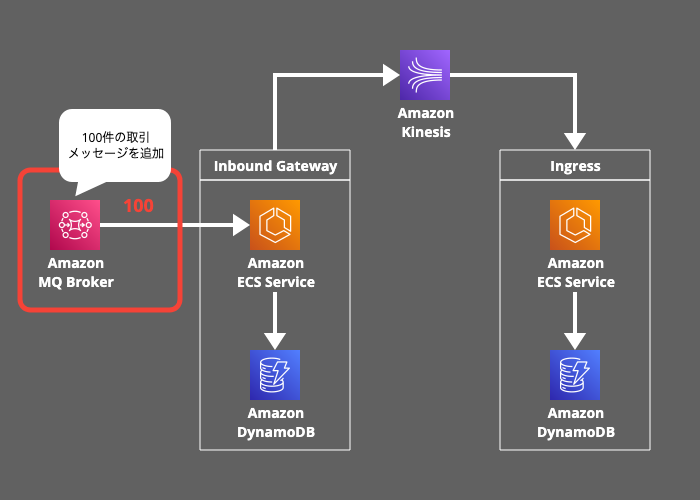
2. インバウンド処理:
Inbound Gateway が100件のメッセージを処理し、DynamoDB に保存後、Kinesisストリーム に転送します。
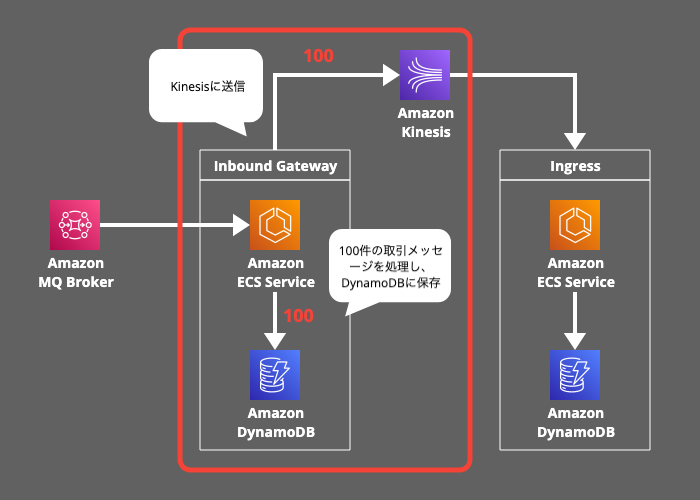
3. イングレス処理:
Ingress が50件のメッセージを処理し、残り50件は Kinesisストリーム に残ります。
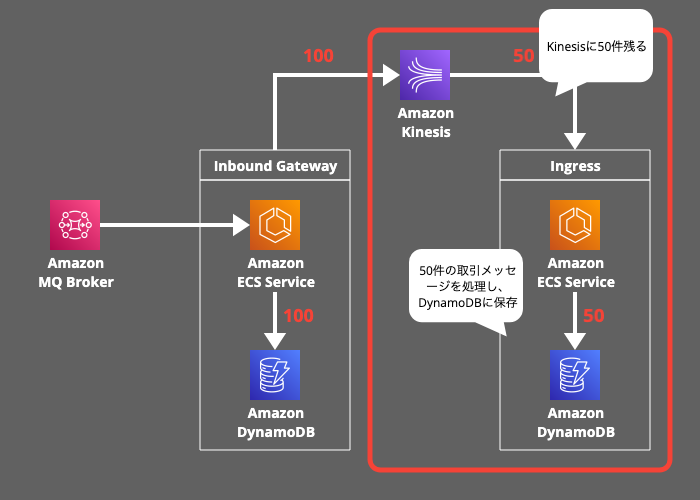
4. 障害発生:
障害が発生して、Kinesisストリームに50件が未処理の状態でアプリケーションが停止します。
5. フェイルオーバー:
Route53 ARCが障害を検知してトラフィックをセカンダリリージョンへ切り替えます。
6. Reconciliation(再調整):
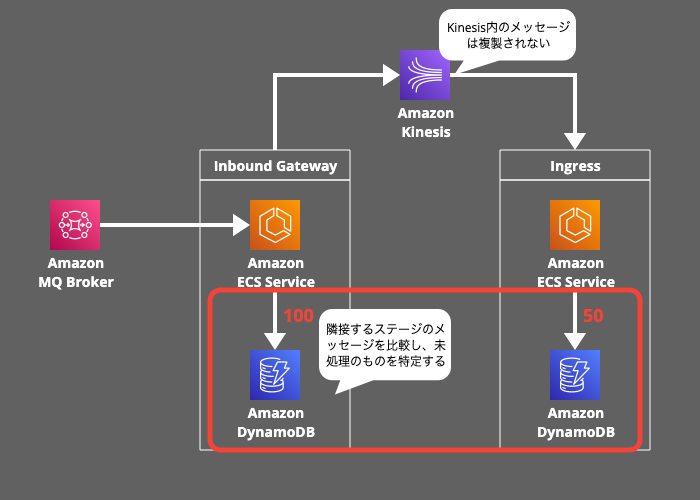
Reconciliationの目的はデータの整合性を確認し、処理漏れを特定することです。Inbound Gateway から Ingress にメッセージを送信する際、100件の取引メッセージが送信されるはずが、50件しか処理されていないので、その差分を特定する必要があります。
各マイクロサービス間の連携を疎結合にするためにAmazon Kinesisを使用していますが、クロスリージョンのレプリケーション機能は直接提供されていないので、プライマリリージョンのKinesisストリームは、セカンダリリージョンのKinesisストリームに複製されません。
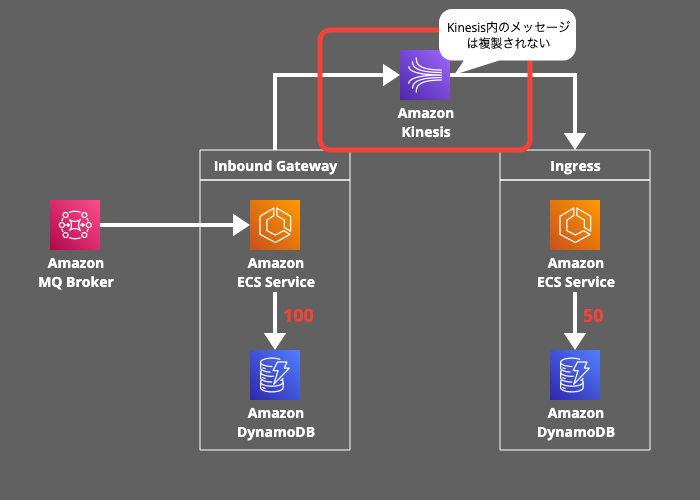
そのため、隣接するステージのメッセージを比較し、未処理のものを特定して、Kinesisストリームに再投入します。例えば、Inbound GatewayのDynamoDBテーブルに存在して、IngressのDynamoDBテーブルに存在しないメッセージが未処理ということになります。
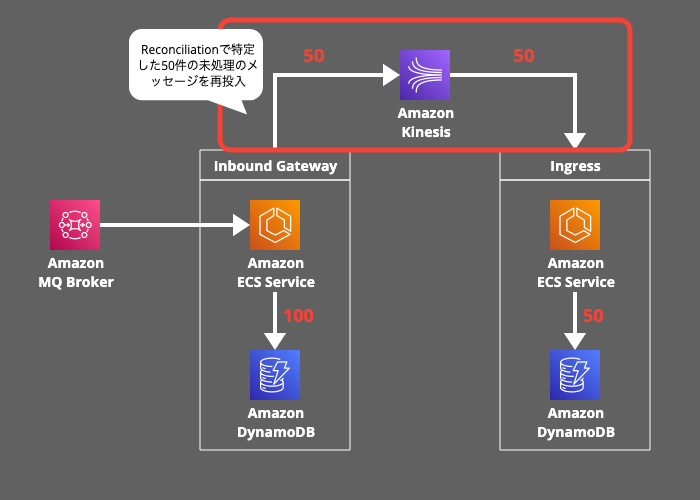
7. Replay(再実行):
最後に、Reconciliationで特定した50件の未処理のメッセージをKinesisストリームに再投入します。
Exactly Once Processing を実現するための工夫
以下の2つの仕組みにより、データの重複処理を防いでいます。
リージョン間の状態管理
AmazonMQに接続して取引メッセージを最初に受け付けるInbound Gatewayでは、Region State Managerと呼ばれるコンポーネントを使用してマルチリージョン構成における重複処理を制御します。
Region State Managerの仕組み:
- RegionStateManagerは、ARC(Route 53 Application Recovery Controller)の状態を監視して、アクティブ・スタンバイを動的にに切り替える役割を果たします。
- リージョンがアクティブに切り替わった場合、メッセージキューのリスナー(JMSリスナー)を初期化してキューのメッセージを受信開始します。
- リージョンがスタンバイに切り替わった場合、メッセージキューのリスナー(JMSリスナー)を停止し、シャットダウンしてメッセージ受信を無効化します。
この仕組みにより、プライマリリージョンとセカンダリリージョンで取引メッセージの重複して掴まないないように制御しています。
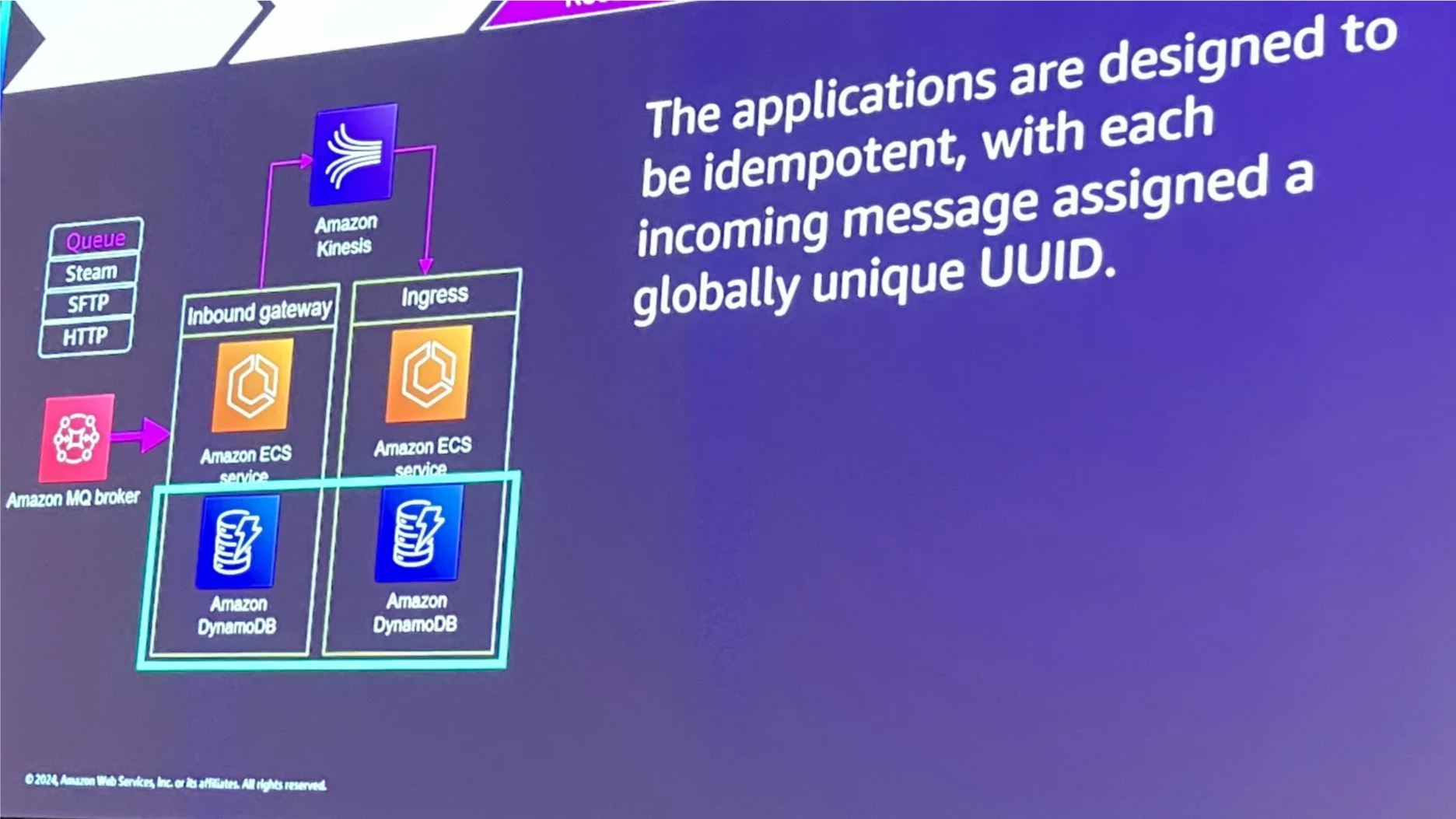
UUIDによる重複メッセージ排除
Kinesisストリームに接続するプロデューサーやコンシューマーのエラーが原因で意図しない再試行が発生することで、メッセージが重複して配信される可能性があります。そのため、メッセージが複数回送られることを前提に、重複処理を防ぐ仕組みが必要です。
グローバルでユニークなIDを活用した仕組み:
- 各メッセージにグローバルに一意なUUIDを割り当てます。
- 各マイクロサービスがDynamoDBテーブルを照合し、すでに処理済みのUUIDを検出した場合、そのメッセージの再処理をスキップします。
これらの仕組みにより、再調整で未処理のメッセージを特定し、再実行で復旧を行いながら、重複処理を防ぐことで厳密な1回限りの処理を実現しています。
まとめ
本レポートでは、DR環境におけるデータ整合性を維持するための重要なポイントを解説しました。特に以下の3つの仕組みが鍵となります。
5つのマイクロサービスによる処理結果の保存と伝播
各ステージでの処理結果を安全に保存し、次のステージへデータを引き渡す設計が、データの整合性を高めています。
Reconciliation(再調整)と Replay(再実行)
障害発生時に未処理データを特定し再実行することで整合性を復元します。
Exactly Once Processing(厳密な1回限りの処理)
UUIDやリージョン状態管理を活用し、重複処理を防止します。
これらの仕組みは、Route 53 ARC、Amazon MQ、DynamoDB、Aurora PostgreSQL、Amazon Kinesis などのAWSサービスと組み合わせることで実現され、高可用性が求められるシステムに応用できます。障害を前提とした堅牢な設計が、DR・分散システムの信頼性を高める鍵です。本レポートが皆様の設計の一助となれば幸いです。
