Docker 社のユースケースでもあげられているように、CI/CD で Docker を使うというのは、プロダクションシステム以外で Docker の特性を活用できる良い場所だと考えています。ヌーラボではBacklog でのプルリクエストの提供以降、CI のジョブの実行のために Docker を利用しています。ここではその運用から学んだ5つの Tips を紹介したいと思います。
ヌーラボの CI 環境の全体図
これがヌーラボの CI 環境の全体図です。
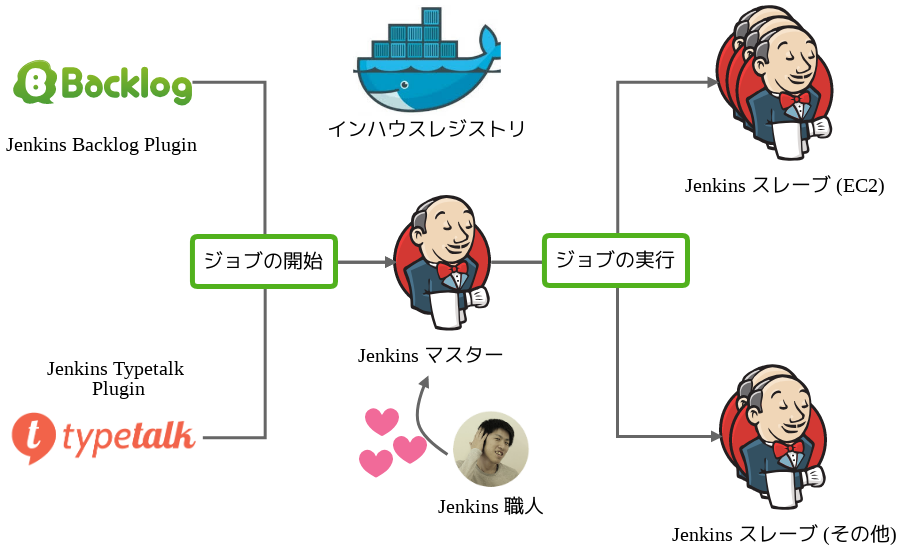
CI には Jenkins を利用しており、Jenkins のジョブのトリガーとなるのは左側の Backlog や Typetalk です。実際には Jenkins Backlog Plugin や Jenkins Typetalk Plugin を利用してジョブを処理しています。これらのプラグインの詳細については本ブログ末に参照先をのせてますので、具体的なワークフローに興味ある方は是非そちらもご覧ください。
ジョブの実行はスレーブ側で行われ、主にテスト用途には EC2 を利用し、モバイルのビルドなど特殊な環境が必要なものについては専用のスレーブを用意しています。現在はマスター含め10台前後のクラスターを構成しており、毎日平均して 250 ビルドを処理しています。
コラム: Jenkins 職人を愛するということ
図中にある「Jenkins 職人」はボット等のプログラムではなく、生身の人間である弊社の中村です。人間である中村が CI 環境に組み込まれているのは、彼の Jenkins への愛がこの環境を支えているから、といっても過言ではなく、先述の二つのプラグインも彼の手によるものです。CI の重要性は理解されていてもなお、その環境の構築やメンテナンスはえてして地道でかつ忍耐のいる作業で、それをコツコツと続けられるエンジニアは私の知る限り多くはありません。ですので彼のモニタリングとメンテナンスも非常に重要で、私の場合は定期的に彼のソーシャルメディアをチェックし、弱気になっている場合はそっと「イイね」をしています。チームにこういった作業を地道に続けてくれるメンバーがいる際には、ときおり感謝を伝えると良いかと思います。
横道にそれました。それでは具体的にこの環境の運用で気をつけているポイントを紹介していきましょう。
Docker を CI で使う上での5つの Tips
1. スレーブの構築方法をシンプルにする
一つ目はスレーブの構築方法をシンプルに保つことです。私たちは Jenkins AWS EC2 Plugin を利用して
- AMI は Amazon Linux の最新版をそのまま
- 起動時に Docker (と Docker Compose) をインストールするだけ
というルールでスレーブを構築しています。
こうすることでスレーブの起動時間を短縮できることと、さらに CI 環境を Docker さえ動いていれば AWS に限らずどこでも動かせる、という状態を保つことができます。
2. Dockerfile 一つでテストする
データベースなどのミドルウェアと接続したテストを行うことは珍しいことではありません。プロダクション環境であれば複数の Docker コンテナを利用し、一コンテナあたり一プロセスが起動する形が好ましいと思いますが、ことテストに限っていえば一つのコンテナ内で複数のプロセスを起動して実行することもよしとしています。
以下の例では redis を Docker コンテナにインストールし、テスト時には redis と Java のプロセスを起動しています。
Dockerfile の例
FROM java:openjdk-8 # ミドルウェアをインストール RUN apt-get install –y redis-server
テストジョブの例
docker run ${TEST_IMAE} bach –c "service redis-server start ; ./gradlew clean test"
この方法は Dockerfile 一つで簡単にテストを実行できること、またコンテナ内で完結するためミドルウェアのポートなどをローカルの開発環境と同じ設定でテストが出来る点がメリットです。
別のアプローチとして Docker Compose を思い浮かべる方もいるかと思いますが (実際私たちも一部のプロジェクトでは使っていますが)、Dockerfile をテスト以外の用途でも使いたい場合をのぞいては、多くの場合はこちらの方法で今のところは十分か考えています。
3. キャッシュを有効に使う
ビルド時間を短く保つにはキャッシュを有効に利用することは重要なポイントです。ここでは Docker イメージと、依存ライブラリの二つの観点からキャッシュの使いかたを見ていきたいと思います。
インハウスレジストリの Docker イメージを使う
まず Docker イメージですが、以下のようにインハウスレジストリを構築し、そこにベースとなるカスタムイメージを保存します。カスタムイメージは、パブリックイメージを元にビルド実行時に必要なランタイムのインストール (JDK、Perl や Python など) などのベースのセットアップをしています。
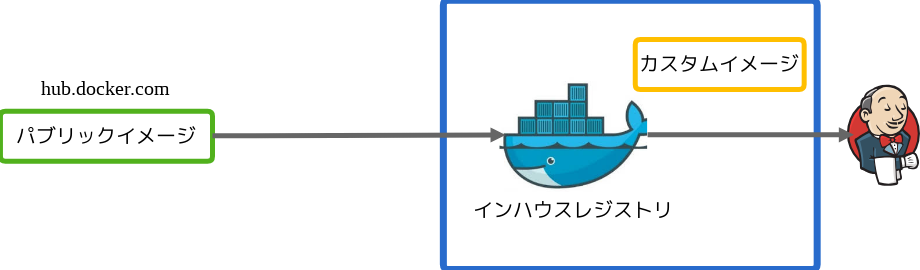
またインハウスレジストリはスレーブにネットワーク的に近い場所に配置し、素早くイメージのダウンロードが出来るようにしています。私たちの場合スレーブは AWS の東京リージョンにあるため、インハウスレジストリも東京に配置しています。
パブリックイメージをそのまま利用することに比べ、スレーブの初期起動時でもより早くダウンロード出来ますし、また必要なものがカスタムイメージに含まれているため、ビルドまでの時間も短縮できます。
依存ライブラリをキャッシュする
次に依存ライブラリのキャッシュです。Java のプロジェクトのビルドにとってはここは最も重要なポイントです。私たちは以下にあげる三つのパターンで依存ライブラリのキャッシュを行ってます。
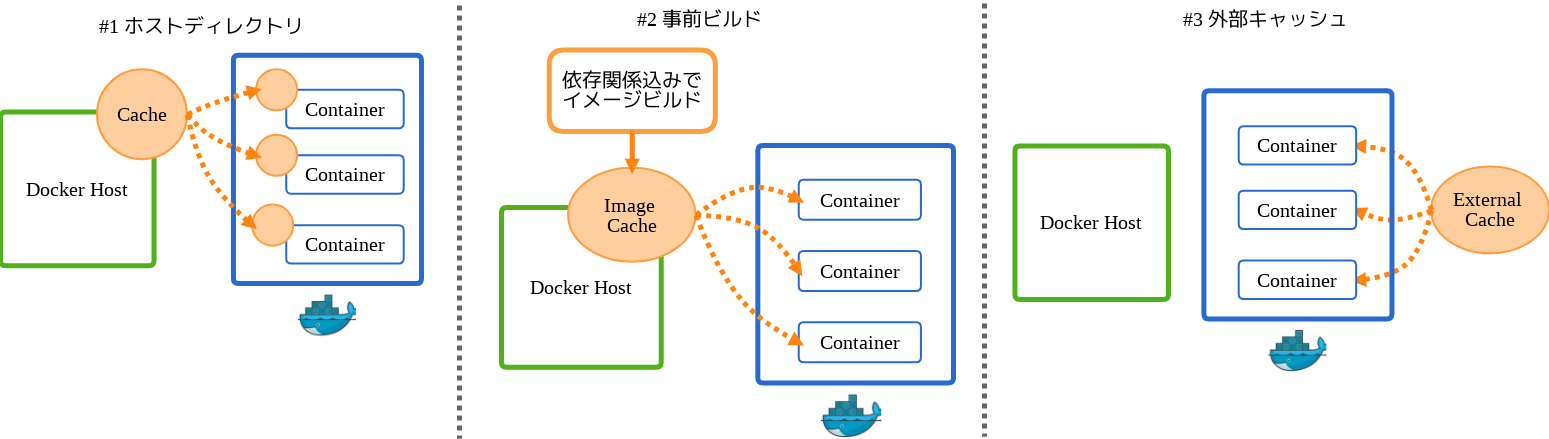
ホストディレクトリパターン
一つ目はホストディレクトリをキャッシュに用いるパターンです。実行時に以下のようにホスト側のディレクトリを依存ライブラリが保存されるコンテナ側のディレクトリにマウントします。ホストディレクトリ側に何もライブラリがない場合は依存関係の解決とダウンロードが走りますが、二回目以降はホストディレクトリ側に依存ライブラリが残っているので、それをキャッシュとして利用出来ます。Java の場合、プロジェクトをまたいでも共通で利用するようなライブラリも多いため、異なるプロジェクト間のキャッシュとしても有用です。ただし、デメリットとしてホストディレクトリに起因するパーミッションの問題が発生する可能性があります。この問題については「ビルド後にコンテナを削除する」で後述します。
docker run –v ${HOME}/.gradle:/root/.gradle ${TEST_IMAGE} ./gradlew clean test
事前ビルドパターン
二つ目の事前ビルドは、事前に依存ライブラリをインストールした Docker イメージをビルドし、それをキャッシュとして利用する方法です。
まず以下のように Dockerfile を作成し、
RUN mkdir -p /opt/app COPY requirements.txt /opt/app/ WORKDIR /opt/app RUN pip install -r requirements.txt COPY . /opt/app
ビルドを以下のように実行します。
docker build –t ${TEST_IMAGE} .
docker run ${TEST_IMAGE} py.test tests
この方法は、依存関係(上記では requirements.txt)はそこまで頻繁に変更はないという前提にたち、テスト実行前にその依存関係に関わるファイルだけをコピーして依存関係をインストールし、そこまでのビルド結果を Docker にキャッシュさせるというものです。依存関係全てが Docker コンテナ内に含まれるので先述のパーミッションの問題はありませんが、一つでも依存関係を変更するとキャッシュが全てクリアされるというデメリットがあります。
外部キャッシュパターン
最後は外部キャッシュパターンで、Travis CI のアプローチをヒントにしています。具体的には以下のような Dockerfile を作成します。
RUN mkdir /root/.gradle
RUN cd /root/.gradle; curl -skL https://s3-ap-northeast-1.amazonaws.com/${CACHE_BUCKET}/cache.20151201.tar.gz | tar zxf -
とてもシンプルなアプローチですが、こちらはスレーブ開始直後の初回ビルド実行時でさえ、Gradle や sbt に依存関係を解決させてダウンロードするよりも圧倒的に早いというメリットがあります。デメリットとしては外部キャッシュをメンテナンスしないといけない点です。
各々のアプローチで一長一短ありますが、Java のプロジェクトは root ユーザで実行出来ることがおおく最初のアプローチを採択しています。対して Python や Perl など、依存関係がコンテナ内にあったほうが何かとデバッグしやすい場合にはふたつ目のアプローチをとっています。三つ目については特に Java のプロジェクトでは有用なので、ホストディレクトリとミックスしたようなやり方が出来ないか検討している所です。
4. ビルド後にコンテナを削除する
テスト実行後には不要となったコンテナを削除しないとそのうちスレーブのディスクを枯渇させてしまいます。ただ、CI の場合には、コンテナの削除をする前に適切にビルド結果を取得してからでないと、テスト結果のレポートや、ビルドした war ファイルもコンテナの削除とともにお亡くなりになられます。
ビルド結果を取得した後、コンテナを削除するには以下の二つのアプローチがあります。
Jenkins のワークスペースをマウントする
一つ目は Jenkins のワークスペースをそのままテスト実行時にマウントする方法です。以下の例では /opt/app を WORKDIR で指定しておき、docker を実行します。
docker run --rm –v $(pwd):/opt/app ${TEST_IMAGE} ./gradlew clean test
この方法のメリットは、通常のビルドツールは実行ディレクトリ配下にビルド結果を保存する事が多く、明示的にビルド結果を取得せずとも、実行後に結果がそのまま Jenkins のワークスペース側に残ります。
ただし、このパターンの注意点として、ビルド実行時に root ユーザ以外での実行が要求される場合に、Docker コンテナ内でのホストディレクトリへの書き込み権限を考慮する必要があります。例えば npm での幾つかのライブラリのインストール時や、testing.postgresql のようなライブラリの利用時に root 以外での実行が求められます。この時にコンテナ内でのビルド実行ユーザの書き込み権限を考慮しないと、ビルド結果が書き込めなかったり次のビルド実行時にビルドが失敗するなどの問題が発生します。このパーミッションの問題には以下の二つのどちらかで解決しています。
一つ目はビルド実行時にはビルド実行しているユーザで書き込みできる場所に結果を書き込み、ビルド後にそのファイルをコピーする、以下のような run.sh というファイルを作り、
su test-user –c "py.test tests –-junit-xml=/var/tmp/results.xml" cp –p /var/tmp/results.xml .
以下のように docker を実行します。
docker run --rm –v $(pwd):/opt/app ${TEST_IMAGE} ./run.sh
二つ目は、ビルド開始時にビルド実行ユーザにオーナーを変更しておき、ビルドが終わったら元に戻す、以下のような run.sh というファイルを作り、
chown test-user . su test-user -c "py.test tests" chown $1 .
以下のように docker を実行します。
docker run --rm –v $(pwd):/opt/app ${TEST_IMAGE} ./run.sh $(id -u)
ここではスクリプトの引数に docker の実行ユーザを渡していますが、スクリプト内でディレクトリのオーナーシップの権限を取得するなど、他にもアプローチはあるかと思います。
テスト実行後に結果を取得して、コンテナを削除する
もう一つのアプローチはビルド実行後にコンテナからファイルを以下のようなステップで取得します。
UNIQUE_NAME=“TEST_${GIT_COMMIT}_$(date +%s)”
docker run --name=${UNIQUE_NAME} ${TEST_IMAGE} ./gradlew clean test
docker cp ${UNIQUE_NAME}:/opt/app/build/test-result/ test-result
docker rm ${UNIQUE_NAME}
こちらの方法は先述のパーミッションの問題には遭遇しませんが、コンテナの削除等のために幾つかステップを踏む必要があります。
どちらの方法にもメリット・デメリットがありますが、今のところ私たちは実行方法が多少複雑になっても、ゴミが残りにくい最初のアプローチを採択しています。
5. ジョブ実行に必要なツールを Dockernize する
私たちはアプリケーションアーカイブ( 主に war や Play!Framework の zip など)を s3 にアップロードするのと同時に、そこに含まれる静的ファイルを CDN 配布用に処理する専用ツールを自作しています。もともとはそのツールをスレーブにインストールした上で、ジョブの設定で
/usr/local/bin/upload-static-s3 ROOT.war -b ${S3_CDN_BUCKET}
のようにしていましたが、現在は以下のようにしています。
まず Dockerfile 内で必要なものをインストール後、以下のような ENTRYPOINT でコマンドを指定したイメージをインハウスレジストリに登録します。
ENTRYPOINT ["/usr/local/bin/upload-static-s3"]
そしてジョブ設定を以下のようにしています。以前のジョブ設定と比較すると、upload-static-s3 コマンドへの引数以降は変わらない形です。
docker run --rm ${IN_HOUSE_REGISTORY_URL}/upload-static-s3 ROOT.war –b ${S3_CDN_BUCKET}
このツールそのものも簡単にスレーブにインストール出来るよう Go 言語で記述していたのですが、さらに Dockernize することでそのインストールすらも不要にすることができ、「テスト – ビルド – S3 へのアップロード」という CI プロセス全体を Docker で走らせることが出来るようになりました。
Docker を CI に導入して良かったこと
Docker を導入して良かったことは以下の三つです。
- 全てのプルリクエストのブランチにテストが出来るようになった
- ビルドのパフォーマンスを改善できた
- CI を Docker が動いている所ではどこでも走らせることが出来るようになった
一つ目は、スレーブ構築が簡単になったこと、およびテストを独立した環境で実行出来るようになった事でプルリクエスト前にテストを自動的に走らせられるようになったことです。
二つ目は、スレーブの変更が手軽になったことで、パフォーマンスが思わしくない場合には上位のインスタンスタイプにあげたり、もしくはスレーブを増やしたり、といった対応が簡単にできるようになりました。その結果、以下のあるプロジェクトにおけるビルド時間の推移が示すように、Docker 導入後にインスタンスタイプの変更も加えることで以前の概ね半分のレベルまで実行時間を落とす事ができました。
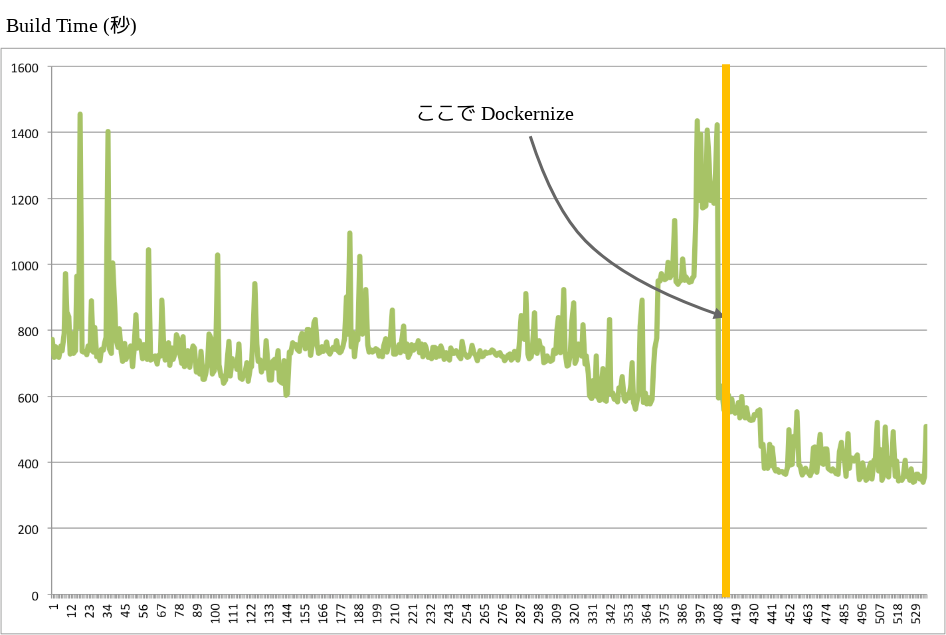
三つ目は、CI プロセス全体を Docker で走らせられるようになったことで、たとえば AWS だけでなく他のクラウド環境でも動かせるようになりました。CI/CD 環境は今ではサービスの運用になくてはならないものです。それを簡便な手段で別の場所に再構築可能にしておくことは、サービスの可用性を考える上でも重要なことだと考えています。
反対に Docker 導入で課題になったことは、全てのアプリケーション開発者が Docker に慣れ親しんでいるわけではなく、各ジョブのメンテナンスに Docker の知識が必要になったことで、一層 Jenkins 職人への依存度が高まったことです。この点については CI 以外でも Docker の便利な点を見出し開発プロセスに導入していくことで、Docker そのものの普及をチームにはかっていくことが必要だと考えています。
今年に入って Docker をプロダクションに利用している例を見聞きする機会が増えてきました。ただ、やはりサービス各々の要件や特性にあわせて個別に考慮しないといけない部分も多く、その知見をそのまま自社の環境で適用するのは簡単ではないのも事実かと思います。その点、CI 環境では Docker そのものの導入もしやすく、他の事例での知見も参考にしやすい領域だと思います。また上記にあげた明確なメリットもありますので、Docker を実際のワークフローで試して、その知見を社内に貯めていく場としては CI/CD は良いのではないかと考えています。
ヌーラボでは Docker をどっかどっか立ち上げたいインフラエンジニアの方を募集しています。
あわせて読みたい:ヌーラボでの CI/CD の取り組み
- 継続的インテグレーションの過去・現在・そして未来 〜ヌーラボの事例と共に考える〜
- Jenkins Backlog Pluginで、ビルド結果をプルリクエストに通知!
- プログラミングいらずのChatOpsがあなたの元に。そう、Typetalkならね
- ヌーラボにおける継続的デリバリ