こんにちは。ヌーラボでソフトウェアエンジニアとして働いている@vvvatanabeです
先日、AWS re:Invent 2024に現地参加しました。ストレージに関わる業務に携わることが多いので、気づくと聴講したチョークトークの大半がストレージ系のものになっていました。
以下、S3やEFS、FSxのレジリエンスを高める勘所・技術をまとめたレポートを公開していますので、もしご興味がございましたら、ぜひご覧ください。
さて、本レポートも例外なくストレージ系のチョークトーク「STG335-R | Find the perfect file storage to optimize your workload’s performance」のレポートになります。
セッションの概要としては、ワークロード毎に最適なファイルストレージを選択する勘所といった内容でしたが、FSx for Lustreの活用術の紹介が大半を締めていたので、レポートとしてもそのあたりに焦点を当ててまとめました。

目次
FSx for Lustreの特長と強み
FSx for Lustreは、ハイパフォーマンスコンピューティング(HPC)領域で特に人気のあるファイルシステムです。実際、世界のトップクラスのスーパーコンピュータのうち6割程度がLustreファイルシステムを利用しているようです。AWS環境で大規模なモデル学習やHPC向けの処理を行う場合、FSx for Lustreなら数分で構築できます。
オンプレミスでLustreクラスターを用意しようとすると、環境構築に数週間から数か月を要することもありますが、AWSなら短時間で準備が完了します。
公式ドキュメント:Amazon FSx for Lustre の特徴
スケールアウトによる高いスループット
たとえば、EKSやDockerなどを使って分散処理を行う場合、データが地理的に離れていると遅延が生じやすくなります。そこで、FSx for Lustreのようなスケールアウト型ファイルシステムを活用し、必要なデータを1つのアベイラビリティゾーン(AZ)内に集約することで、低レイテンシかつ高いスループットを確保しやすくなります。
FSx for Lustreは、1つの大きなファイルを複数のサーバーに分散して保管し、読み込み時にはこれらのサーバーが並列でデータを供給します。その結果、多少のレイテンシ増加はあるものの、圧倒的なスループットを得ることが可能です。HPCの分野では、膨大なデータを並列で高速に処理する必要があるため、こうしたスケールアウト型ファイルシステムが大きな役割を果たします。
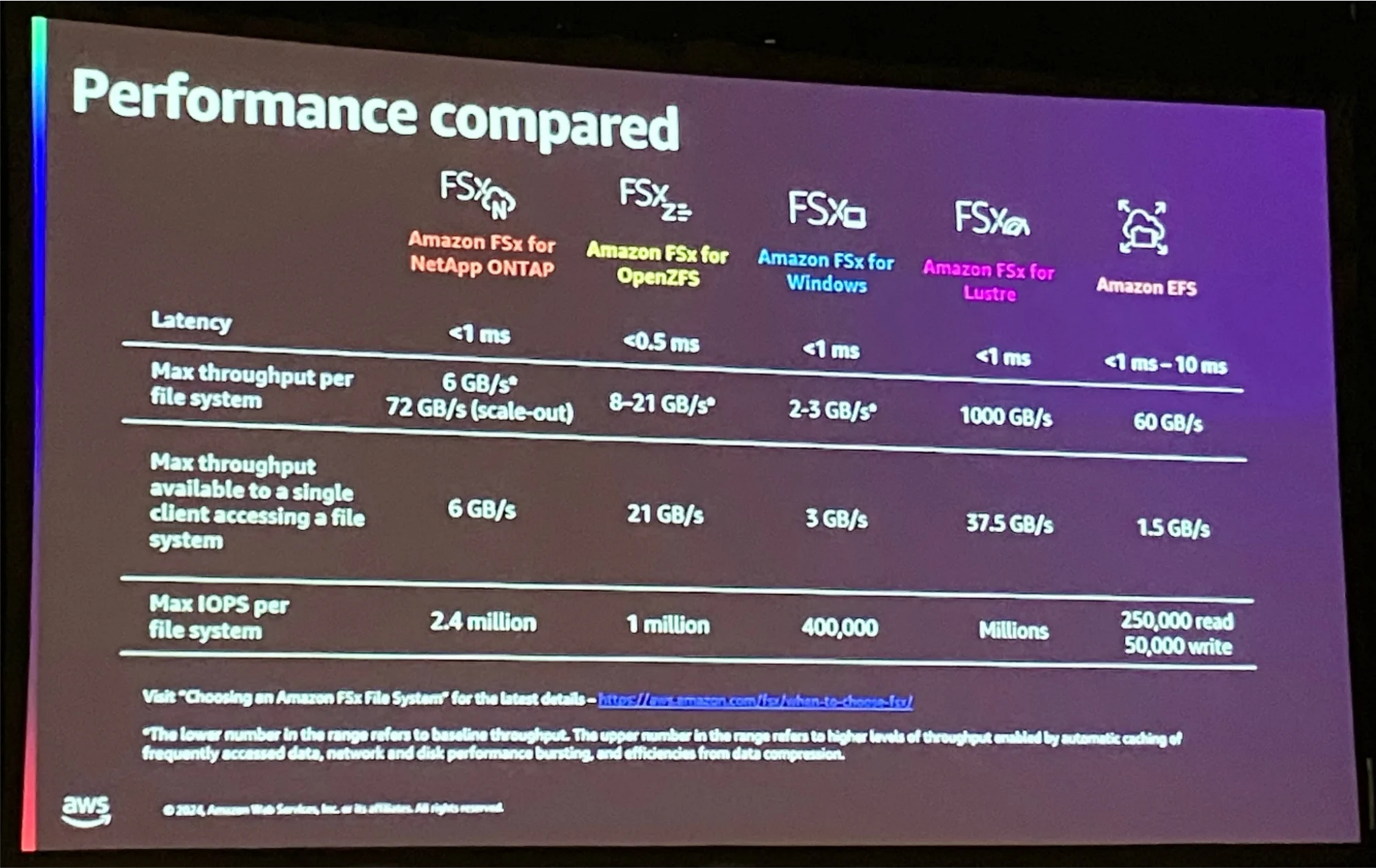
S3とのDRA連携
FSx for Lustreには「データリポジトリアソシエーション(Data Repository Association, DRA)」という機能があり、S3をバックエンドとして統合できます。これにより、S3バケット内の大量のファイルを、FSx for Lustre上であたかも通常のディレクトリ構造の一部のように扱えるようになります。たとえば、S3バケットのルート(”/”)をLustreファイルシステムに関連付けると、そのバケット中のファイルがすべてLustre上で見えるようになります。
ここで重要なのは、最初からすべてのファイルデータをロードするわけではない点です。初めはメタデータのみがロードされ、実際のファイルデータは最初にアクセスした時点でS3から取り込み、ローカルキャッシュに保持します。2回目以降のアクセスはこのキャッシュを利用するため、非常に高速に読み込めます。
また、同じS3バケットを複数のFSx for Lustreファイルシステムと関連付けることも可能です。これにより、異なる計算リソースグループごとに専用のローカルキャッシュ領域を持たせ、同じS3データを効率的に利用できます。最初のアクセスでS3からデータを取得するコストはかかりますが、その後はキャッシュを使って高速アクセスが可能になります。
公式ドキュメント: Amazon S3 バケットにファイルシステムにリンクする
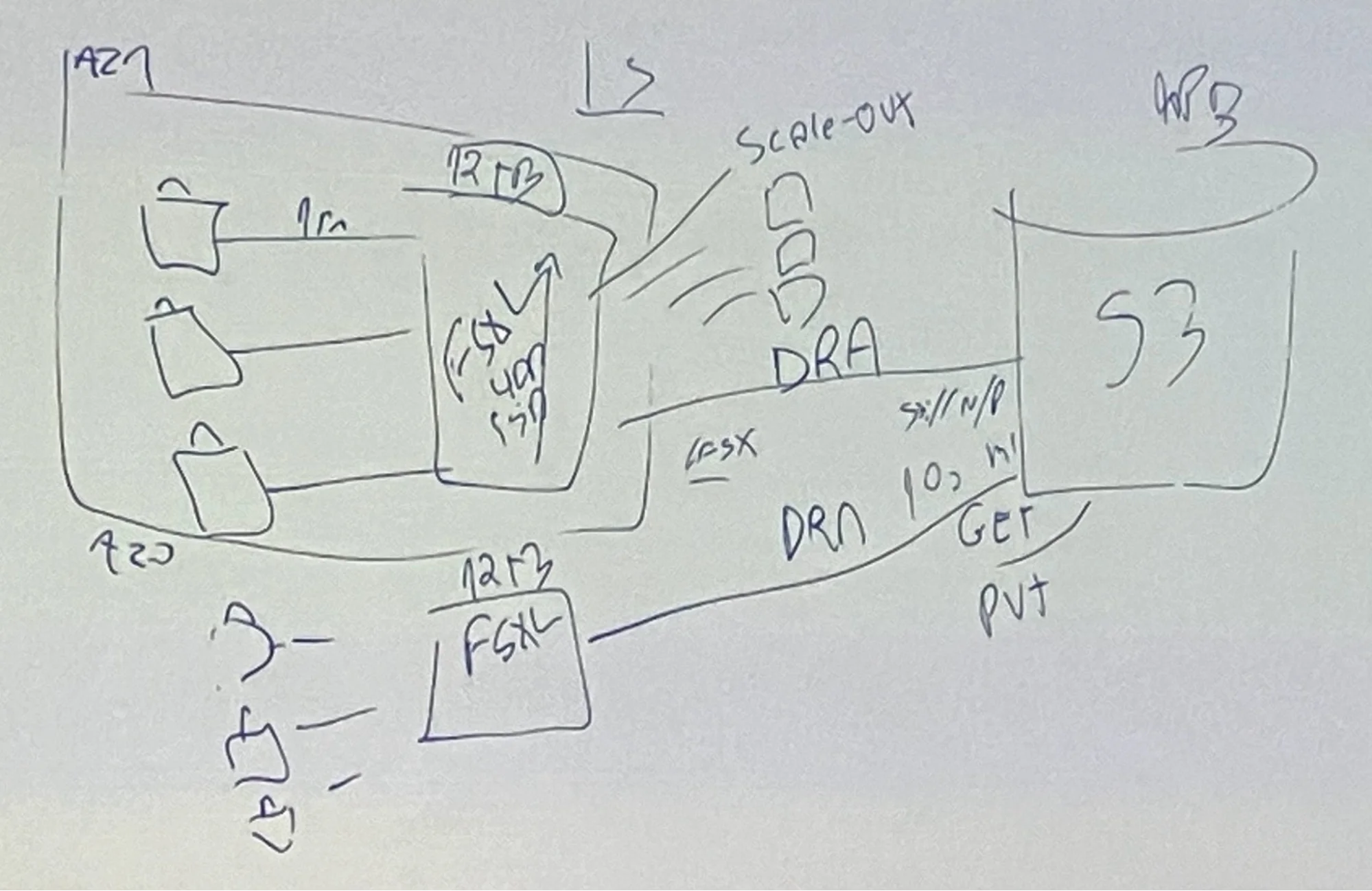 ホワイドボードで描いたS3とのDRA連携の概要図
ホワイドボードで描いたS3とのDRA連携の概要図
Scratchファイルシステムでオンデマンド利用
FSx for Lustre には、ファイルシステムデプロイオプションとしてScratchとPersistentがあります。
ScratchタイプのFSx for Lustreを利用すれば、必要な期間だけファイルシステムを用意し、ジョブが終われば削除するといった柔軟な運用が可能です。たとえば、月に2回、1回あたり6時間程度の処理が必要な場合、その期間だけファイルシステムを用意して処理を行い、完了後は削除することでコストを最小限に抑えられます。
このように、FSx for LustreとS3を組み合わせることで、データアクセスにおける柔軟性とコスト効率を同時に実現できます。用途やニーズに応じて、高性能かつリーズナブルなファイルアクセス環境を簡便に構築することが可能です。
公式ドキュメント:FSx for Lustre ファイルシステムのデプロイオプション
実際の活用事例とベストプラクティス
メディア制作現場でのデータ同期とScratchファイルシステムの活用
通常のファイルシステムは、運用中に完全に停止するのが難しく、利用が少ない時間帯でもコストが発生しがちです。一方、FSx for Lustreは前述のScratchファイルシステムを活用することで、必要なときだけファイルシステムを立ち上げ、使わないときは止めてしまうことができます。これにより、余計なコストをかけずに高性能を利用する、いわゆる「オンデマンド」な使い方が可能になります。
とあるメディア制作会社では、朝6時に必要なデータをFSx for Lustre上にあらかじめロードしておくことで、アーティストが8時に出社した直後から高速なアクセスで制作を開始できます。日中の制作作業が終わる夕方6時には、更新されたデータをS3へ書き戻し、FSx for Lustreを停止します。
これにより必要な時間帯だけ高性能を発揮させ、そのほかの時間はコストを抑えられます。他の多くのファイルシステムでは難しい柔軟な運用が、FSx for Lustreなら実現できるのです。
機械学習トレーニングジョブでのS3 + FSx for Lustre構成
機械学習やHPCのトレーニングワークロードでは、巨大なデータを効率よく扱うことが不可欠です。S3とFSx for Lustreを組み合わせれば、初回アクセス時だけS3からデータを取り込み、その後はローカルキャッシュから高速に読み出せます。これにより、高価なGPUクラスターへデータをスムーズに供給でき、計算リソースを最大限活かすことができます。
もちろん、Amazon EFSでも類似の構成は可能ですが、圧倒的なI/O性能が求められる状況ではFSx for Lustreが有利です。EFSは構築がシンプルで手軽に始められますが、大規模で超高速なI/Oには限界があります。FSx for Lustreなら、必要な場面で高スループットを確保し、高価な計算リソースをフルに活用することが可能です。
Q&A
Scratchファイルシステムで、大容量(12TB以上)が必要な場合はどうするのか?
FSx for Lustreは後から容量を拡張できます。最小構成は1.2TB単位で、必要に応じて積み増せます。オンラインで容量アップが可能なので、データアクセスを止めずに対応できます。ただし、容量を増やすとその分コストは上がる点には注意しましょう。
スループット(帯域幅)を増やしたいときはどうすればいいですか?
FSx for Lustreは容量を増やすと自動的にスループットも向上します。1.2TBあたり125MB/s程度のスループットが期待でき、必要に応じて大規模なスループット(1GB/sレベル)を得ることもできます。たとえば、特定の日だけ高いスループットが必要な場合、その期間だけ容量(=スループット)を増やし、後で元に戻せばコストを最適化できます。
DRAのデータの同期・複製で注意すべきポイントはありますか?
DRA(Data Repository Association)では、S3が最終的なデータの基準点になります。つまり、異なる場所から同じファイルを書き換えれば、最後に書き込んだ更新が有効となります。複数のAZ間で完全な同期的整合性を保つことは難しく、同時書き込みを回避する工夫や、書き込みは特定のAZからのみ行うなど、アプリケーション側の運用ルールが必要です。
まとめ
FSx for Lustreは、HPCや機械学習など高スループットが必要なワークロードに最適なファイルストレージサービスです。AWS上でLustre環境を手軽に構築できるうえ、S3とのDRA(Data Repository Association)やScratchファイルシステムを活用することで、コストとパフォーマンスを柔軟に調整できます。これにより、必要な時間帯だけ高速アクセス環境を用意したり、大量データをGPUクラスターへ効率的に供給したりと、ビジネスニーズに合わせた最適な運用が可能になります。
本レポートが、最適なパフォーマンスとコスト効率を実現する指針として、ご参考いただければ幸いです。
公式ドキュメント
