本の中の似顔絵が似ているので、社内チャットのアイコンもこれにしたらどう?と言われた中村です、こんにちは。
「現場のインフラ屋が教える インフラエンジニアになるための教科書」という本を執筆してて、つい先日(2016年6月24日)発売となったので、簡単にその内容と執筆環境の裏側を紹介します。

書籍の紹介
メインターゲットは、2〜3年目のインフラエンジニアです。仕事にもちょっと慣れてきて余裕も出てきた頃に、今後生き残るために何をどうしていくかの指針となるような本です。
その中で、私は「第6章 DevOps時代に求められるスキル」を担当しました。
- 6.1 インフラエンジニアを取り巻く環境
- 6.2 Infrastructure as Code(コードとしてのインフラ)
- 6.3 システム開発における3つのプラクティス
- 6.4 DevOpsを支えるプラクティス・ツール
私はもともとアプリエンジニアなので、アプリエンジニアから見たインフラという文脈で執筆させていただきました。書籍中でも紹介していますが、「Infrastructure as Code」などはアプリエンジニアが得意としていた分野です。そのため、インフラエンジニアの方の中には、このような考え方にあまり馴染みがない方もいるかもしれません。そういった方が本章を読んで、少しでも参考になればと思います。
執筆環境
と、これだけだと単なる宣伝に終わっちゃうので、本の執筆環境について紹介したいと思います。執筆作業にかぎらず、もともとこういう環境整備系は好きなので、共著者の中で一番最後に参加したにもかかわらず、半分無理を言って環境整備させてもらって共著者の皆さんに協力してもらいました。
なお、今回の執筆環境を少し手直ししてサンプルも載せたものを、下記のGitHubリポジトリにあげています。実際に皆さんの手元でPDF生成なども可能ですので、興味がある方は見てもらえれば。
- nulab/book-template
- サンプルPDF:book.pdf
- サンプル文字数カウントグラフ:book-count.png
全体概要
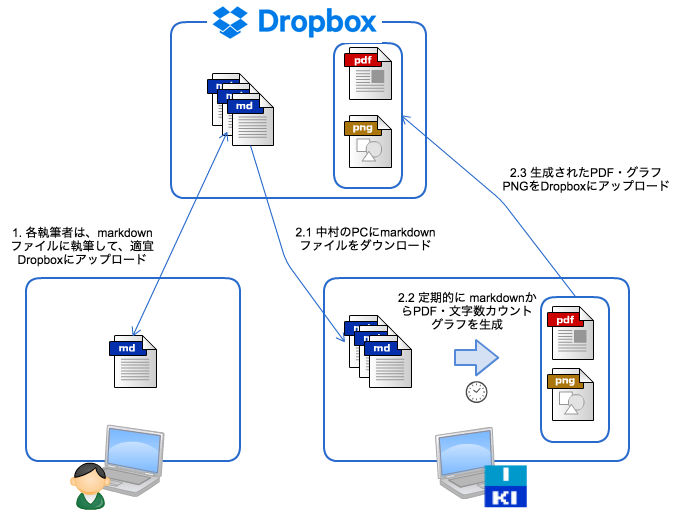
執筆段階の原稿は、Dropboxで管理していました。作業は、大きく2段階に分かれています。
- 各執筆者:markdown ファイルに執筆
- 中村:データ作成
- markdownファイルをダウンロード
- PDF・文字数カウントグラフの生成
- 生成したデータを再度アップロード
以降、図の右下、2で中村がやってたことを説明します。
markdownからPDF生成
今回は原稿をmarkdownで管理しました。大抵のmarkdownエディタにはHTMLでのプレビューがついてるので、ある程度の文書構造はHTMLで把握できます。それでも、今回PDFを原稿確認用に用いたのですが、HTMLに比較したPDFのメリットは、以下のとおりです。
- 目次を出せる
- ページ単位で確認できる
- 見出し・図表番号を自動採番できる
各章や節を目次として出せるのは、やはり分かりやすいですね。私はアウトラインレベルで構造を把握していくタイプなので、まず目次見てから構造的につながりがおかしいところがないかを把握していました。
ページ単位で確認できるのは、実際にやってみてメリットが分かりました。HTMLだと、どこで途切れるか分からない、一枚続きの文書になります。これと比べて、PDFのようにページごとに区切られていると、読む方としてもやりやすいです。
見出しや図表番号の自動採番も、大きなメリットです。自動採番機能がなければ手動で採番していくと思いますが、章や節の順番入れ替えが発生した場合、間違いなく漏れる箇所です。自動採番するための記法にちょっとだけ慣れが必要ですが、あると便利な機能ですね。下記の図の、節タイトルの”3.3″や、”図3-10″が自動採番されたものです。

なお、PDF化にはPandocの機能を用いています。Pandocの内部では、markdownをいったんTeXに落として、その上でPDFを生成しています。ですので、PDF生成のカスタマイズはTeXレベルで行う必要があります。こちらもGitHub上にTeXファイルとしてあげていますので、参考までに。大学の卒論以来に、TeXを触りました。
文書の文字数カウント
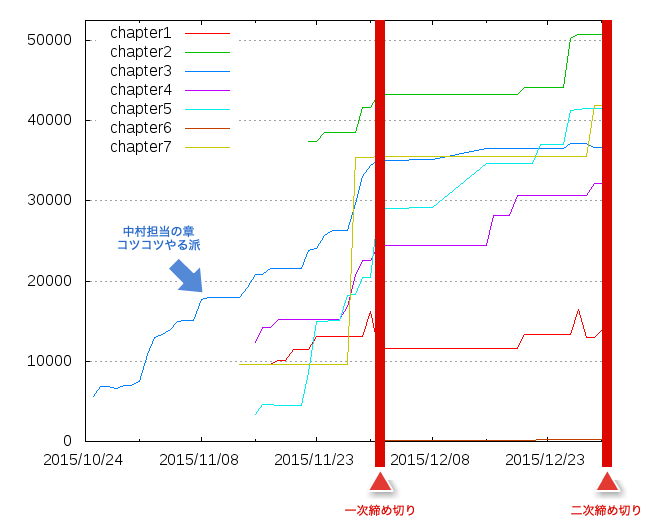
以前も似たようなことはやったのですが、各章ごとに執筆した文字数をカウントして、グラフ化しました。前回と違って、今回は自分一人だけではなく共著なので、他の著者の進捗具合を測るのにもよかったと思います。モチベーションの維持にも使えたかなと思いますが、逆にモチベーション下がってたかも?
ちなみに、私は一番左から記録されてる青い線。平日と土日でちょいちょいばらつきはありますが、割りとコツコツやる派でした。他のみなさんは、特定のタイミングでがつっと上がる方もいますね。
グラフ化の実装方法としては、このような感じです。下記の流れを、毎日午前5時に実行するよう、PCのcronに仕込んでいました。
- wcコマンドで、各章ごとのmarkdownファイルの文字数をカウント
- カウントした文字数を、CSVファイルに出力(サンプル:count_chapter1.dat)
- CSVファイルをもとに、gnuplotでグラフ化(gnuplot設定ファイル:count.plt)
もうちょっと工夫できたかもしれない点
- Dropbox以外の、バージョン管理システムの導入
- textlintによる文書チェック
完全に結果論ですが、バージョン管理システムは入れておいたほうがよかったなと実感しました。一番の欠点は、Dropbox管理の文書は、共同編集するのには向いていないという点です。Dropboxにも簡易的なバージョン管理はついてて、元のバージョンを確認することはできます。が、バージョン間の差分の確認はできないので、誰かが修正した際にどう修正されたかが分からないという欠点がありました。
textlintも、余裕があれば試してみてもいいかとは思っています。textlintを知ったのがある程度執筆が佳境に入ってきたタイミングだったので、導入検証する時間は取れませんでした。次執筆する機会をいただければ、検討してみようかなと思っています。
というわけで、本書を読んでいただいた感想や、執筆環境を実際に体験してみた感想などをお待ちしております。
ヌーラボでは、本の執筆や執筆環境など、様々なことに興味があるインフラエンジニアを募集しています。