この記事はヌーラバー真夏のブログリレー2024の5日目の記事です。
こんにちは。サービス開発部Backlog課の@vvvatanabeです。
プロジェクト管理ツール「Backlog」では、課題管理、Wiki、ガントチャート、ボード、Git、SVN、ファイル共有など、さまざまな機能をオールインワンで提供しています。
本記事では、Backlogのファイル共有機能に焦点を当て、末永くご利用いただくために解決したい技術的な課題や、検討しているサーバーレスな設計ついて詳しくご紹介します。
目次
ファイル共有機能の紹介
はじめに、Backlogのファイル共有機能について簡単にご紹介します。
ファイルを一元管理して多重管理を防止
プロジェクトごとにフォルダが用意されているため、メンバーへのドキュメント共有もBacklogで完結します。

ファイル検索機能
「更新日」や「更新者」で絞り込み、任意の「キーワード」でファイルを検索できます。

簡単にファイルの共有
ボタン一つでファイルの格納先URLを取得し、課題のコメントやWikiから簡単にメンバーに共有できます。

PCから直接アクセス
WebDAVプロトコルをサポートしており、ExplorerやFinderから直接ファイルやディレクトリにアクセスして操作できます。

ファイル共有機能を支える技術
Backlogのファイル共有機能がどのような技術を使って提供されているか、簡単に説明します。
現行のアーキテクチャ
Backlogのファイル共有機能は、Backlog本体とは別に独立したファイルサーバーを内部的に提供しています。これは、ストレージを本体に持たせると、本体のスケールが困難になるためです。Backlog本体およびユーザーは、WebDAVプロトコルを使用してファイルサーバーに接続します。複数のファイルサーバーは、一定のBacklogスペースのグループごとに割り振られ、グループに応じて適切なファイルサーバーへ接続される仕組みになっています。
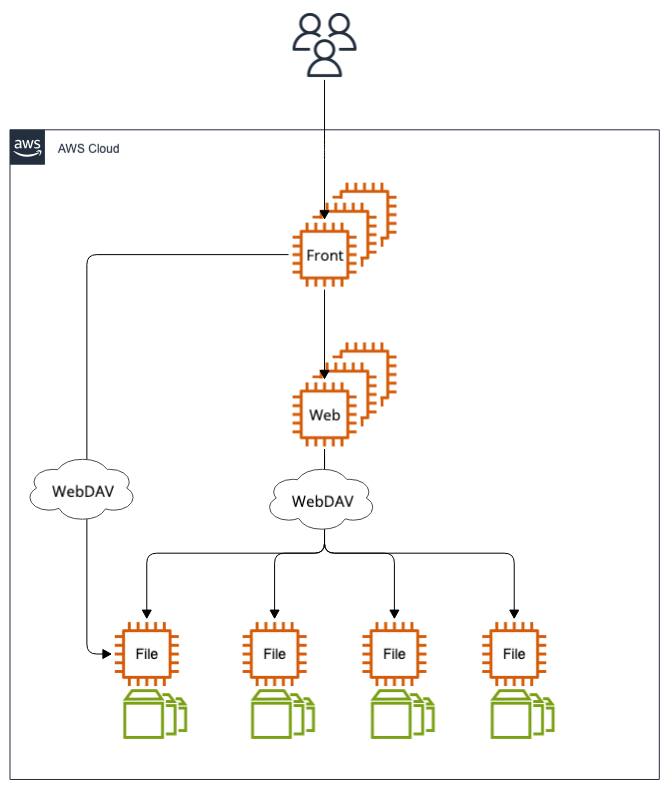
RFC 3744(Web Distributed Authoring and Versioning)
前述のとおり、Backlogのファイル共有機能はRFC 3744(Web Distributed Authoring and Versioning)、通称WebDAVをサポートしています。WebDAVはWebサーバーをファイルサーバーとして利用するためのプロトコルであり、HTTPを拡張して以下の主要な機能を提供します。
- ファイル操作:ファイルの作成、編集、削除、コピー、移動が可能です。
- ディレクトリ操作:ディレクトリの作成、削除、移動が可能です。
- プロパティ操作:ファイルに対してプロパティやメタデータを設定および取得することができます。
- ロック操作:ファイルやディレクトリをロックして、複数のユーザーによる同時編集を防ぐことができます。
Apache HTTP Serverとmod_dav/mod_perl
バックエンドのミドルウェアとしては、Apache HTTP Serverを使用しています。このサーバーは、mod_davモジュールによってWebDAVプロトコルをサポートしています。さらに、mod_perlモジュールを用いて、Backlog特有の処理を拡張しています。
時代の流れとともに、ApacheやPerlはWebアプリケーションの実現手段として選ばれることが少なくなってきていますが、これらの技術は安定した機能を提供する信頼性の高い「歴戦の戦士」であることに変わりはありません。社内でも、これまでの価値提供に対してリスペクトを持ってメンテナンスされています。
Amazon EC2とEBS
ファイルの保存先として、Amazon EBSを使用しています。ファイルサーバーとしてはAmazon EC2を利用しています。ファイルサーバーは複数のEBSをマウントすることでディスク容量を拡張し、ファイルは一定のグループごとに分けて特定のEBSに保存されています。
ファイル共有機能の課題
ファイル共有機能は運用面においていくつかの課題があります。
オペレーションのコスト
ファイル共有機能の運用において、定期的にEC2のセキュリティアップデートやディスクの拡張、さらにはOSのサポート終了(EOL)に伴うEC2の入れ替えが必要となり、これが運用コストに大きく影響しています。
ストレージのコスト
現在使用しているEBSは汎用SSD(gp3)タイプであり、その料金はプロビジョニングした容量に基づいて決まります。アジアパシフィック(東京)リージョンでは、1GBあたり月額0.096USDがかかります。例えば、100TBのストレージを使用すると月額9600USDとなり、円安の影響がさらにコスト負担を増大させています。
スケールアウトの難しさ
サーバーが状態(ストレージ)を持つため、状態を持たないコンテナと比べてスケールアウトが難しいという課題も存在します。
これらの課題を解決することで、運用コストが軽減され、持続可能なシステムへと成長させることができると考えています。
サーバーレスなストレージの選択肢
AWSのサービスの中でも、オペレーションコストを抑えられるサーバーレスなストレージとして、Amazon S3、Amazon DynamoDB、Amazon EFS、Amazon FSxを検討しました。本記事では、Amazon S3、Amazon DynamoDBの検討について紹介します。その他のストレージサービスは別途紹介できればと思います。
※ Amazon AuroraはMySQL・PostgreSQLバージョンのEOLに伴うアップデートオペレーションを考慮して対象から除外しています。
Amazon S3
Amazon S3はサーバーレスのオブジェクトストレージサービスです。複数のAZで冗長化されていて、コスト面でも非常に優れています。
圧倒的なコスト削減
アジアパシフィック(東京)リージョンのS3スタンダードでは、最初の50TBに対して月額0.025USD/GB、450TBまでは月額0.024USD/GB、500TB以上は月額0.023USD/GBという低コストで利用できます。例えば、100TBのストレージを使用すると、月額2450USDとなり、Amazon EBSと比較して約75%のコスト削減が可能です。
高レベルな可用性と耐久性を備えたストレージを低コストで利用できるのは大変魅力的です。
ファイルシステムとしての制約
ファイルシステムとして使用するにはMountpoint for Amazon S3などのツールが必要ですが、S3はシンプルなKVS(キー・バリュー・ストア)であるため、一般的なファイルシステムの階層構造特有の操作をサポートしていません。具体的には、既存のファイルを一覧表示して読み取ることや新しいファイルを作成することは可能ですが、既存のディレクトリ・ファイルをアトミックにリネームすることや、削除することはできません。
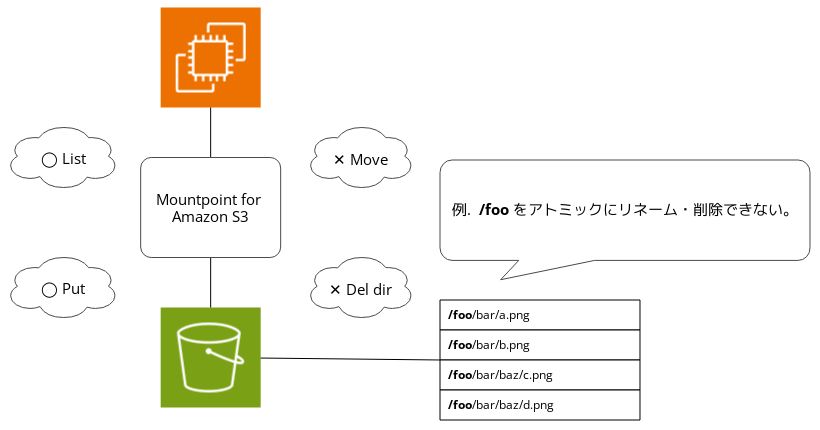
結論として、Mountpoint for Amazon S3ではファイル共有機能の要件を満たすことはできません。
Amazon DynamoDB
Amazon DynamoDBは、サーバーレスのフルマネージドNoSQLデータベースです。複数のAZで冗長化されています。
テーブル設計による階層構造の表現
DynamoDBは、一つのアイテムに複数のプロパティを持たせることができ、ユニークなキー(プライマリキー)を指定してデータを取得します。セカンダリインデックスを使うことでプライマリキー以外を指定してデータをクエリすることも可能です。また、トランザクションもサポートしており、最大100件のアイテムをアトミックに操作できます。テーブルの設計によって階層構造を表現することもできます。
1アイテム最大400KBの壁
DynamoDBの項目の最大サイズは400KBであり、ファイル共有機能のユースケースではファイルが400KBを超えることがよくあります。これではバイナリデータなどサイズが大きくなりやすいデータを保存することはできません。
キャパシティユニット
DynamoDBは、プロビジョニングモードとオンデマンドモードがあります。プロビジョニングモードでは、読み取りと書き込みのキャパシティユニットを設定し、その範囲内でスループットをコントロールします。オンデマンドモードは、リクエスト数に応じてキャパシティユニットがスケールして、使用した分だけ課金されます。各キャパシティユニットは1秒間に1つの読み取り/書き込みオペレーションに対応します。
ストレージコストの比較(USD per GB):

複数のストレージサービスを組み合わせたコスト最適化
前述の「サーバーレスなストレージの選択肢」で述べたように、費用面で最も優れているのはAmazon S3です。しかし、S3だけではファイルシステムの階層構造や複数のプロパティをサポートすることができません。
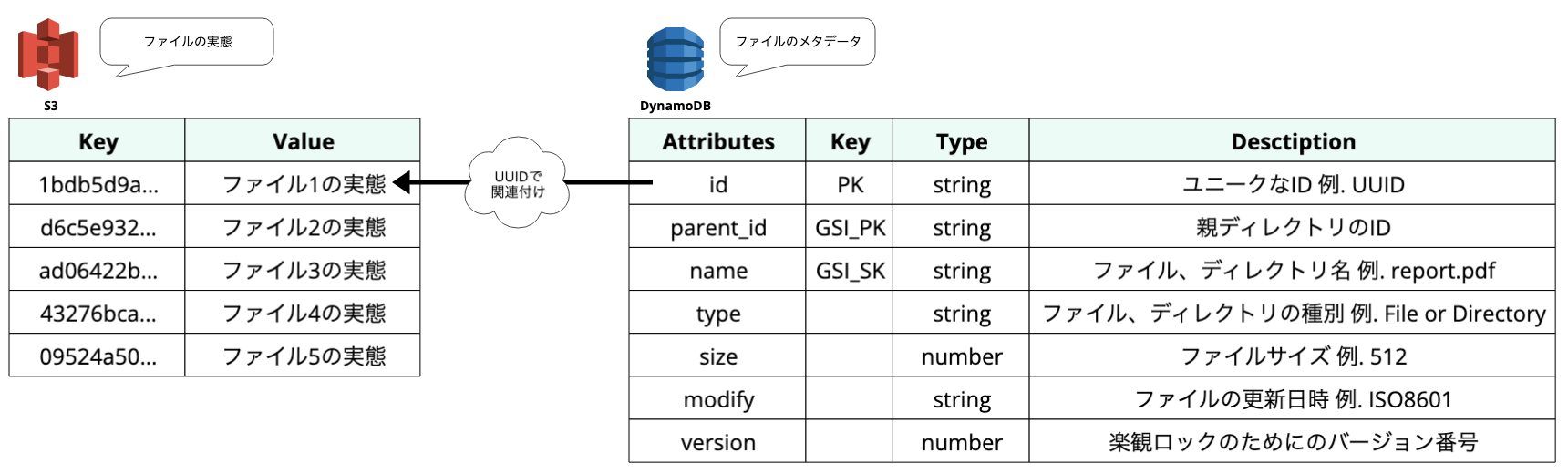
ファイルの実態とメタデータの分離
そこで、ファイルの実態とメタデータ(階層構造・プロパティなどの情報)を、それぞれ適切なストレージサービスに分ける設計を検討しました。具体的には、ファイルの実態を低コストなS3に保持し、ファイルのメタデータをDynamoDBで管理します。メタデータは大きくても1KB程度なので、高コストなストレージに保持しても実際にかかる料金はかなり抑えられるはずです。例えば、合計100TBのファイルの実態をS3に保持すると、月額2450USD程度になります。メタデータのサイズが最大1KBを前提とし、仮に1億個のファイルやディレクトリがあったとしても、メタデータの合計は100GB弱程度です。月額28.5USD程度に抑えられます。
ストレージコストの比較(100TB):

S3オブジェクトのキーにはUUIDなどのユニークなIDを使用し、メタデータとそのUUIDを関連付けることで一貫性のある管理を実現できると考えています。これにより、DynamoDBの「1アイテム最大400KBの壁」も克服できます。詳細は後述します。
このアプローチのヒントになったのは、Git LFS(Large File Storage)というGitの拡張です。Git LFSは、大容量ファイルを効率的に管理するために設計されています。BacklogのGitホスティングでもこの仕組みを提供しています。通常のGitリポジトリでは、ファイルの実態そのものがバージョン管理システムに含まれるため、大容量ファイルの管理は非常に非効率です。Git LFSでは、大容量のファイルの実態を外部のストレージに保存し、そのメタデータのみをGitリポジトリに保存します。具体的には、Git LFSはファイルの実態を特定のストレージに保存し、そのポインタ(メタデータ)をGitのオブジェクトとして管理します。
WebDAVのバックエンド拡張
現行システムでは、EC2からマウントしたAmazon EBSのファイルシステムに対して、Apache HTTP ServerがWebDAVプロトコルを介して読み書きを行っています。ファイルの実態とメタデータを分離するためには、この読み書きをS3とDynamoDBに対して行う必要があります。独自のApache HTTP Serverモジュールを作成することは避けたい理由は、開発と保守が複雑になるためです。また、Apache HTTP Serverのバージョンアップに伴う互換性の問題や、新たな脆弱性への対応も考慮しなければなりません。
そこで、Goのgolang.org/x/net/webdavパッケージを検討しました。このGoの準標準パッケージはWebDAVプロトコルをサポートしており、ファイルのI/OがFileSystemインターフェースで抽象化されているため、拡張が容易です。さらに、webdav.Handlerがhttp.Handlerに準拠しているため、標準のhttpパッケージを使用してWebDAVサーバーを構築することができます。標準パッケージを使用することで、コードの保守が容易になります。Goの標準ライブラリは広く使用されており、豊富なドキュメントとサポートが存在するため、将来的なメンテナンスもスムーズに行えます。
また、AWSのAPIを利用するためには、github.com/aws/aws-sdk-go-v2を使用します。このアプローチにより、開発と保守の効率を大幅に向上させることができます。
webdavパッケージのFileSystemインターフェイスとHandler:
type FileSystem interface {
Mkdir(ctx context.Context, name string, perm os.FileMode) error
OpenFile(ctx context.Context, name string, flag int, perm os.FileMode) (File, error)
RemoveAll(ctx context.Context, name string) error
Rename(ctx context.Context, oldName, newName string) error
Stat(ctx context.Context, name string) (os.FileInfo, error)
}
type File interface {
http.File
io.Writer
}
type Handler struct {
// Prefix is the URL path prefix to strip from WebDAV resource paths.
Prefix string
// FileSystem is the virtual file system.
FileSystem FileSystem
// LockSystem is the lock management system.
LockSystem LockSystem
// Logger is an optional error logger. If non-nil, it will be called
// for all HTTP requests.
Logger func(*http.Request, error)
}
余談ですが、GoのwebdavパッケージやRFC 3744を読んで知識を補填していたところ、webdavパッケージの挙動でRFC3744準拠していない箇所を見つけたので、ちょっとした修正を送ったらマージされました。Goのwebdavパッケージは未だに様々なOSSで活用されているようなので、今後も機会があれば積極的に貢献して行きたいと思います。
S3とDynamoDBを用いたアーキテクチャの考察
前述の「複数のストレージサービスを組み合わせたコスト最適化」では、ファイルの実態とメタデータ(階層構造・プロパティ)を分けて考えました。
まず、1つのパターンとして、ファイルの実態をS3で、メタデータをDynamoDBで管理するアーキテクチャを考察します。
階層構造を表現するデータ設計
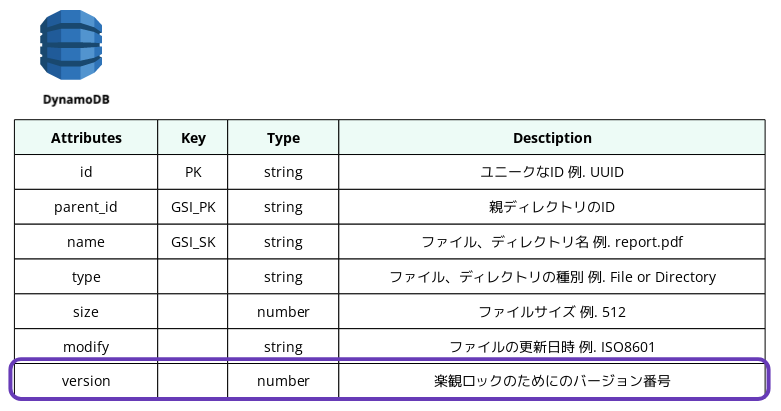
以下に、DynamoDBのテーブルでメタデータを表現するための各種属性を説明します。
id (プライマリキー):
ファイルやディレクトリのユニークなIDです。(例:UUID)UUIDなどのユニークなIDを使用して、S3オブジェクトのキーとDynamoDBのアイテムのプライマリキーとして指定し、関連付けます。これにより、S3とDynamoDBの間で一貫性のある管理を実現します。
parent_id (グローバルセカンダリインデックスのプライマリキー):
親ディレクトリのIDを格納します。これにより、階層構造を表現します。
name(グローバルセカンダリインデックスのソートキー):
ファイルやディレクトリの名前です。(例:report.pdf)
type:
ファイルの種類です。(例:FileまたはDirectory)
size:
ファイルのサイズです。(例:512)
modify:
ファイルの更新日時です。(例:ISO8601形式)
version:
楽観ロックのためのバージョン番号です。詳細は後述します。
ファイルのダウンロードシーケンス
例として、/root/foo/apple.png をダウンロードするケースを考えます。
パスの階層数に比例して増加するクエリ数
この場合の手順を以下のように考えます。
- まず、name=rootを指定して、rootディレクトリのメタデータを取得します。
- 次に、グローバルセカンダリインデックスのプライマリキーとしてparent_id=root.idと、グローバルセカンダリインデックスのソートキーとしてname=fooを指定してfooディレクトリのメタデータを取得します。
- 次に、グローバルセカンダリインデックスのプライマリキーとしてparent_id=foo.idと、グローバルセカンダリインデックスのソートキーとしてname=apple.pngを指定してapple.pngファイルのメタデータを取得します。
- 最後に、apple.pngのIDをS3オブジェクトキーに指定してファイルの実態をダウンロードします。
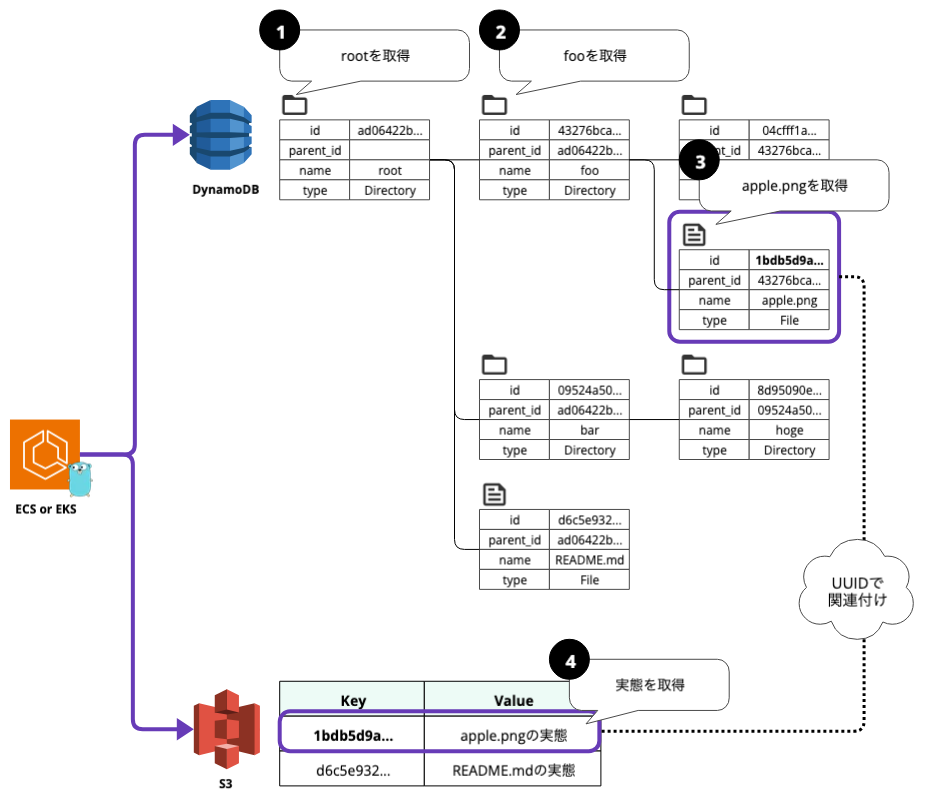
この手順には、ファイルパスの階層が増えるほどクエリの数が増えるという課題があります。各メタデータにファイルのフルパスを持たせる方法も考えられますが、リネームや削除の際に関連する全アイテムをアトミックに更新する必要があり、DynamoDBのトランザクションの制限(最大100件)に引っかかる可能性があります。
フルパスをツリー構造でキャッシュする
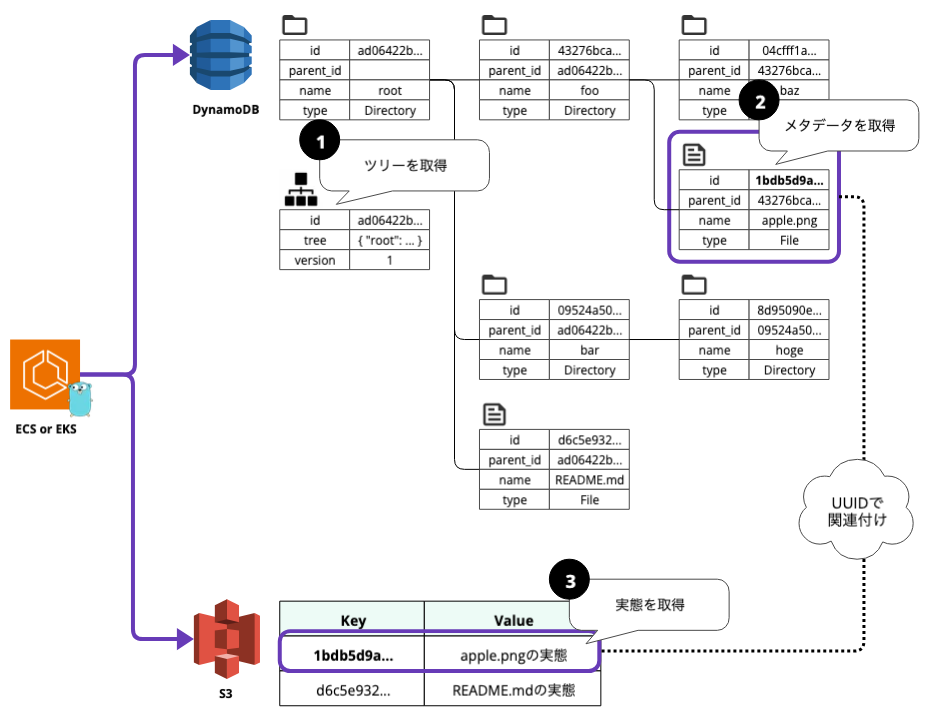
解決策としては、ファイルのフルパスをツリー構造でキャッシュする方法が挙げられます。
まず、リクエストのコンテキスト(プロジェクト)ごとにファイルのフルパスをツリー構造でDynamoDBにキャッシュしておきます。対象のパスを解決する際には、その境界のツリーを取得し、メモリ内でツリーをもとに対象(例:/root/foo/apple.png)のIDを解決します。これにより、パスの階層数が増えても1クエリで対象のファイルを特定できます。
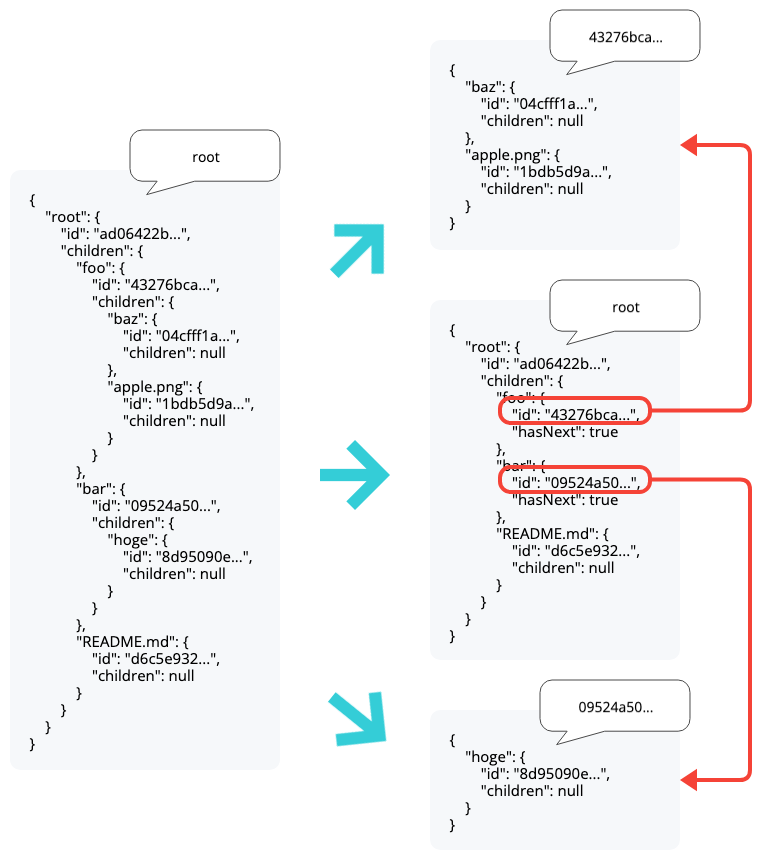
ファイルシステムのツリー構造:
{
"root": {
"id": "ad06422b...",
"children": {
"foo": {
"id": "43276bca...",
"children": {
"baz": {
"id": "04cfff1a...",
"children": null
},
"apple.png": {
"id": "1bdb5d9a...",
"children": null
}
}
},
"bar": {
"id": "09524a50...",
"children": {
"hoge": {
"id": "8d95090e...",
"children": null
}
}
},
"README.md": {
"id": "d6c5e932...",
"children": null
}
}
}
}
さらに、DynamoDBの400KB制限を考慮して、ツリーのサイズに適切な閾値を設け、ツリーを更新するタイミングで分割・結合を繰り返すことで肥大化を防ぎます。
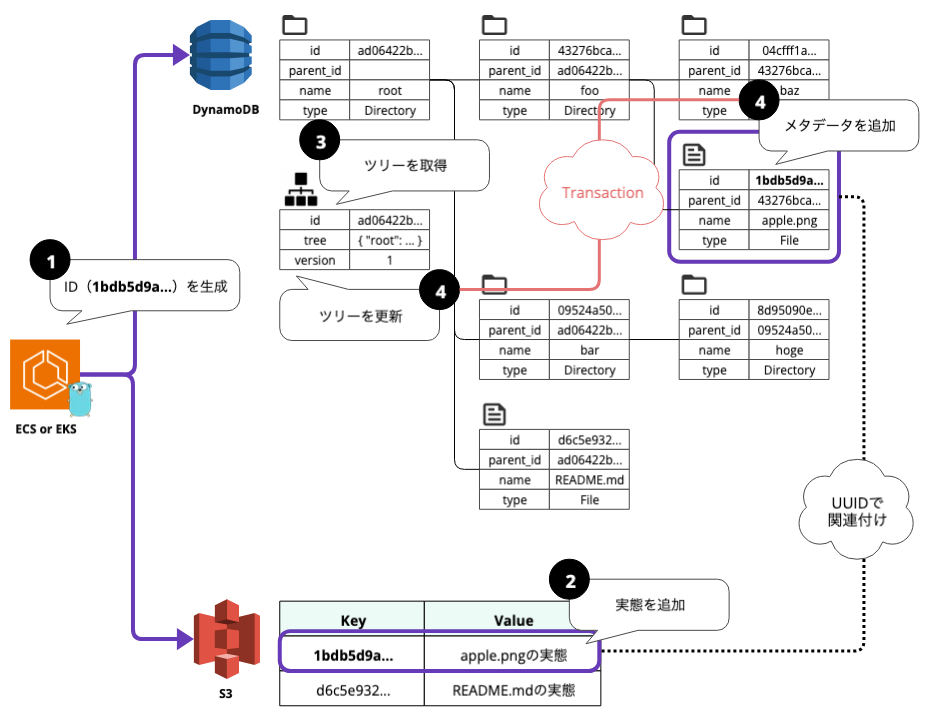
ファイルのアップロードシーケンス
例として、/root/foo/apple.png をアップロードするケースを考えます。
前提として、WebDAVプロトコルは単一のファイルパスを指定してファイルの読み書きを行います。つまり、1リクエストにつき1リソースを処理するということです。
実態とメタデータの整合性
異なるストレージへデータを追加するため、トランザクションが分離されることになります。そのため、エラー時に双方の整合性を崩さないように工夫しなければなりません。
整合性を保つためのフロー
- まず、アプリケーションでファイルに付与するユニークなid(UUIDなど)を生成します。
- このIDをキーとして、ファイルの実態をS3に追加します。ここで失敗した場合は、処理はエラーとなり終了します。
- 次に、前述のツリーから/root/foo/apple.pngの親ディレクトリのidを取得します。
- 次に、親ディレクトリのIDをparent_id、実態と同じUUIDをidに指定して、ファイルのメタデータをDynamoDBに追加します。この時、階層構造が更新されるので、同一のトランザクションでツリーも更新します。メタデータの追加・ツリーの更新に失敗した場合は、ロールバック後に、S3のファイルの実態も削除します。
これにより、メタデータが存在するのに実態が存在しないといった状態を回避します。
ファイルのリネームシーケンス
例として、/root/foo/apple.pngを/root/foo/orange.pngにリネームするケースを考えます。
以下はリネームの手順です。
- 前述のツリーから/root/foo/apple.pngのidを取得します。
- 次に、idに指定してapple.pngのメタデータのnameをorange.pngに変更します。この時、同一のトランザクションでツリー内のファイル名も変更します。
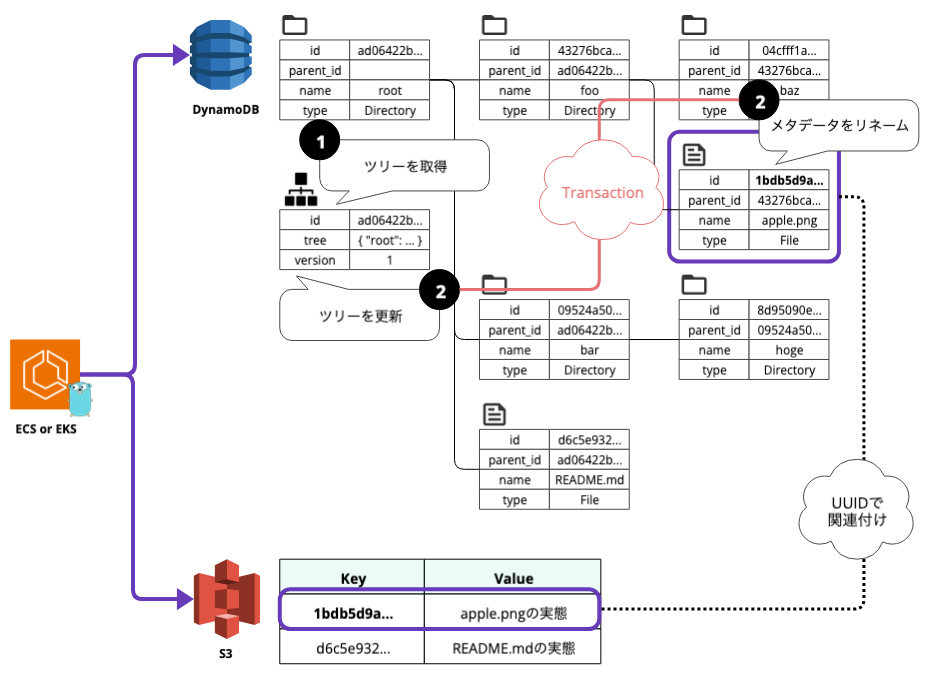
メタデータ更新時の排他制御
前述のとおり、メタデータのプライマリキーであるidを指定してnameを更新します。
しかし、DynamoDBの書き込み操作はデフォルトでは無条件で行われるため、後からの書き込みが意図せずに上書きされる可能性があります。WebDAVプロトコルはロックをサポートしていますが、ストレージレベルでも制御したほうがより堅牢です。
条件付き書き込みを利用した楽観ロック
この課題に対する解決策として、条件付き書き込みを利用して楽観ロックを行います。具体的には、更新対象のアイテムが取得時と同じ状態であることを条件とし、version項目に現在のバージョンを指定します。更新する際にはアトミックにversionをインクリメントし、条件を満たさずに更新できなかった場合はエラーを返すようにします。
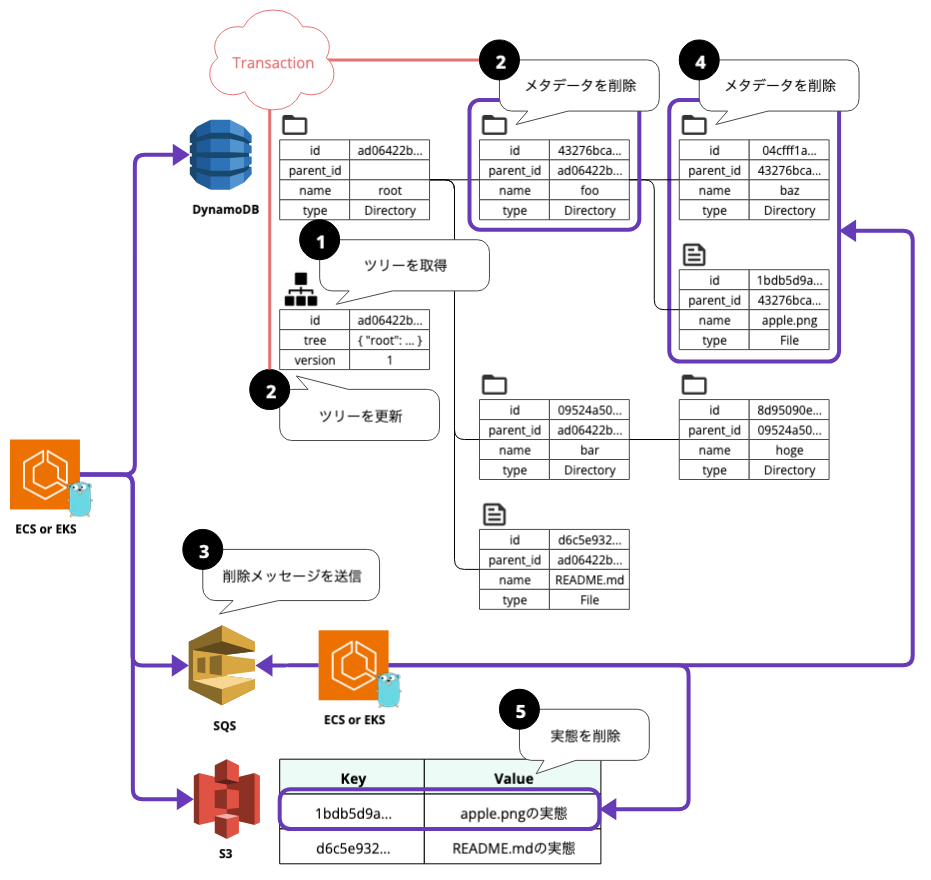
ディレクトリの削除シーケンス
例として、/root/fooを削除するケースを考えます。
非同期で行う到達不能な子孫の削除
以下は削除の手順です。
- まず、前述のツリーから/root/fooのIDを取得します。
- 次に、そのIDを指定してfooディレクトリのメタデータを削除します。この際、同一のトランザクションでツリー内のfooディレクトリも削除します。しかし、関連する子要素やS3の実態も再帰的に削除する必要があり、DynamoDBのトランザクションは最大100件までしか対応できません。
- この課題を解決するために、非同期で子のファイルやディレクトリを削除する方法を取ります。fooディレクトリのIDを記したメッセージをSQSに送信します。
- SQSを通じてワーカーがメッセージを受け取り、指定されたfooディレクトリのIDをもとに子のファイルやディレクトリを削除します。
- 削除対象がファイルの場合、S3に保存されているファイルの実態も削除します。
この手順により、ディレクトリとその内容を安全かつ効率的に削除することができます。
まとめ
サーバーレスなアーキテクチャのメリットの再確認
コスト効率の面では、Amazon S3やDynamoDBを使用することでストレージコストを大幅に削減できます。スケーラビリティにおいては、ステートレスな設計により、コンテナ化が容易になり、リソースのスケールアウトが簡単になります。また、運用負荷の軽減については、AWSのフルマネージドサービスを利用することで、セキュリティアップデートやディスク拡張などの運用負荷を大幅に軽減することができます。
レガシーなプロトコルを活かしつつ、新技術を導入する重要性
WebDAVプロトコルは古いプロトコルではありますが、実際にはまだ多くの利用者がいます。ユーザーに価値を提供していることに変わりはありません。レガシーなプロトコルであっても、現代の進化した技術を適切に導入することで、システムの安定性と信頼性を維持しながら、背後の技術的な改善を続けることが可能です。
今後の展望
今回の記事の内容は、サーバーレスなストレージによるリアーキテクチャの考察に過ぎません。まだまだ不確実な点も多く、これから実際にPoC(概念実証)を進めていく予定です。その他、Amazon EFS、Amazon FSxなどの検証も進めていますので、あらためて別の記事で紹介できればと思います。
将来的には、AWSの各種サービスを効果的に組み合わせることで、より効率的で高性能なファイル共有サービスを実現し、運用効率の向上とコスト削減を目指していきたいと考えています。
