この記事はヌーラボブログリレー2025 夏の16日目の記事です。
こんにちはこんばんは。RevOps部データインテグレーション課のonoeです。
皆さん、データ使っていますか?データ活用していますか?
ヌーラボではデータ基盤としてSnowflakeを利用しており、日々データ活用を推進しています。データ活用において個人識別情報(以下、PII)を扱う場合、高い安全性が必要になります。
今回、Snowflake上でPIIを安全に利用するための仕組みを構築したので、その意図と実際の構造について書いてみたいと思います。
目次
データマスキングの必要性と、閲覧可能範囲について
データ基盤には様々な種類のデータが保存されています。
契約に関するデータ、サービスの利用状況に関するデータ、マーケティング活動に関するデータ・・・など。そして、すべてのデータが全社員に関係しているわけではありません。
全社員がすべてのデータにアクセス可能な状態だと、データ基盤で公開できるデータはセキュリティ上の観点から、もっとも機密度が低いデータまでしか公開できず、データ活用に支障が出てしまいます。
そのため、データ基盤においては、各利用者にあわせた閲覧可能範囲の設定が必要で、権限を持たない場合はデータをマスキング処理しておく必要があります。
PII類型に基づくマスキングレベルの定義
一言で「PII」と言っても、色んな種類があり、それぞれ機密度が異なります。
今回、PIIを取り扱う仕組みを構築するにあたり、PIIの種類(PII類型)とマスキングレベルを以下のように整理しました。
|
カテゴリ |
説明 |
マスキングレベル |
|
顧客生成情報 |
プロダクトの利用者が登録した情報 |
Low / Medium / High |
|
お問い合わせ情報 |
お問い合わせを利用した方が登録した情報 |
Low / Medium / High |
|
オンライン識別子 |
ID、パスワード、IPアドレス、プロフィールなど |
High |
|
契約者情報 |
氏名、住所など契約に関する情報 |
Medium / High |
|
個人識別情報 |
氏名、住所、マイナンバー、パスポート番号、公的機関が発行した番号など |
Critical |
|
金融財務情報 |
銀行口座情報、クレジットカード番号、取引履歴など |
Critical |
|
通信の秘密関連情報 |
クローズドチャット・メッセージ機能 |
Critical |
|
行動履歴 |
閲覧履歴、位置情報 |
Medium / High |
|
健康医療関連情報 |
医療記録、健康診断結果、持病 |
Critical |
|
雇用情報 |
従業員に関する情報、労働契約情報、履歴書、勤怠情報 |
Critical |
上記に記載されたものは「一般的にPIIとして取り扱われるもの」を整理したもので、これらすべてがデータ基盤に保存されているわけではありません。
ただ、定義としては網羅しておきたかったので、考えられる種類をすべて書いています。
PIIによって「絶対に見せてはいけない」、「一部マスキングすれば大丈夫」、「集計データならOK」など、ある程度、処理方法にグラデーションがあると考えたので、上記の様に整理をしました。
「顧客生成情報」で「Low / Medium / High」となっているのは、生成される情報によって扱いが異なるためです。
生成される情報すべてを定義すると細かすぎるので、このようにしてあります。
マスキング手法について
今回、マスキング手法として以下2つを採用しています。
- dbtでの静的マスキング
- Snowflakeでの動的マスキング
その上で、実際のマスキング処理としては3種類を使い分けています。
- 一意性を保持しない固定値でのマスキング(アスタリスク8文字、など)
- 一意性を保持したマスキング(ハッシュ化)
- 値の一部のみ固定値でマスキング(先頭5文字をアスタリスク、など)
これらの内容を先に定義したマスキングレベルに対して、以下の様に紐づけました。
|
マスキングレベル |
手法 |
マスキング処理 |
|
Critical |
dbtでの静的マスキング |
一意性を保持しない固定値でのマスキング(アスタリスク8文字など) |
|
High |
Snowflakeでの動的マスキング |
一意性を保持しない固定値でのマスキング(アスタリスク8文字など) |
|
Medium |
Snowflakeでの動的マスキング |
一意性を保持したマスキング |
|
Low |
Snowflakeでの動的マスキング |
値の一部のみ固定値でマスキング |
Criticalなものについては、dbtで静的マスキングを実施しており、Snowflake内に完全に入らないようにしています。
これは、Snowflakeでの何らかの設定変更や作業ミスによってマスキングが外れてしまうリスクを懸念したためです。
マスキング処理は他にも「データを統計化する」(たとえば実年齢を20代といったものにするなど)といった処理方法もありますが、ヌーラボでは統計化処理はデータモデリングのときに実施しているため、今回のマスキング処理では採用しませんでした。
dbt上での静的マスキング手法
dbt上でのマスキングはdbt_privacyというdbtのパッケージを利用しています。
マスキングレベルが「Critical」のものだけをdbtで制御しているので、利用しているのはsafe_maskのみで、以下のように使用しています。
SELECT
{{dbt_privacy.safe_mask("val") }} as masked_val
FROM {{ ref("hoge_table") }}
dbt_privacyのsafe_maskは、マスキング後の文字列なども指定できますが、上記のように指定はしていないためデフォルトのままです。
safe_maskのデフォルトは、
- アスタリスク8文字でマスク
- NullはNullのまま出力する
となっています。
その他の細かい処理については、パッケージのドキュメントを参照ください。
Snowflake上での動的マスキング手法
マスキングレベルがHigh以下のものはSnowflakeの動的マスキング処理をしています。通常、Snowflakeでは以下のような手順で動的マスキングを設定します。
- マスキングポリシーを作成する
マスキングポリシーは文字列型ごとに必要なので、文字列型と数値型それぞれのポリシーが必要です。
このマスキングポリシー内で、閲覧を許可するロールを設定していきます。
-- 文字列型のマスキング
CREATE OR REPLACE MASKING POLICY mask_pii_str_high AS (val STRING)
RETURNS STRING ->
CASE
WHEN val IS NULL THEN NULL
WHEN val = '' THEN ''
WHEN CURRENT_ROLE() IN ('ACCOUNTADMIN','SYSADMIN','READER_PII') THEN val -- アクセス許可するロール
ELSE '********'
END;
-- 数値型のマスキング
CREATE OR REPLACE MASKING POLICY mask_pii_num_high AS (val NUMBER)
RETURNS NUMBER ->
CASE
WHEN val IS NULL THEN NULL
WHEN val = '' THEN ''
WHEN CURRENT_ROLE() IN ('ACCOUNTADMIN','SYSADMIN','READER_PII') THEN val
ELSE 0
END;
- 対象カラムにマスキングポリシーをアタッチする
ALTER TABLE user_info ALTER COLUMN address SET MASKING POLICY mask_pii_str_high;
この方法でもちゃんとマスキングはできるのですが、1カラムずつマスキングポリシーをSQLで設定せねばならず手間です。
なので、Snowflakeのタグを利用してタグにマスキングポリシーをアタッチするようにしました。
-- pii_highのタグ作成 CREATE OR REPLACE TAG pii_high; -- マスキングポリシーとタグの紐づけ ALTER TAG pii_high SET MASKING POLICY mask_pii_str_high,MASKING POLICY mask_pii_num_high; -- 対象カラムにタグ付け ALTER TABLE user_info MODIFY COLUMN address SET TAG pii_high = 'yes';
このようにすることで、カラムにタグを付けるだけでマスキング対象にすることができます。
実運用では、Snowflakeのマスキングポリシーとタグとの紐づけはTerraformで管理されており、タグ付けはdbtで行っています。
dbtのモデルは扱うデータ量に比例して増えていくため、そのたびにTerraformを修正していくのは手間が大きくなってしまいます。
そこで、タグ付けでのマスキングにすることで、dbtとTerraformで処理を分離することができ、運用負荷を減らすことができました。
また、Snowflakeのタグはkey-value形式なので、「pii_high=’yes’」のように設定していますが、この「yes」は実際のマスキング処理には影響しません。
「pii_high」というタグがついているだけでマスキング対象になります。
dbtでのSnowflakeへのタグ付け
先に書いたとおり、対象カラムへのタグ付けはdbtで行っています。
dbtにはタグという機能があるのですが、これはSnowflakeのタグとは実は別物です。
dbtのタグは、dbtが生成するドキュメントやビルド実行時の対象にするなどの用途が主で、設定されているからといってSnowflakeにタグ付けされるわけではありません。
dbtからSnowflakeへのタグ付けをするには、自前で処理を作るか、パッケージを使う必要があります。
ヌーラボではdbt-tagsというパッケージを利用しました。
dbt-tagsでは、dbtモデルのyamlに以下のように書くだけでSnowflakeへのタグ付けがされます
version: 2 models: - name: user_info columns: - name: ID data_type: NUMBER - name: ADDRESS data_type: VARCHAR tags: - pii_high~yes
少し分かりづらいですが、「~」で区切られた前がタグ名、後がそのタグの値として登録されます。
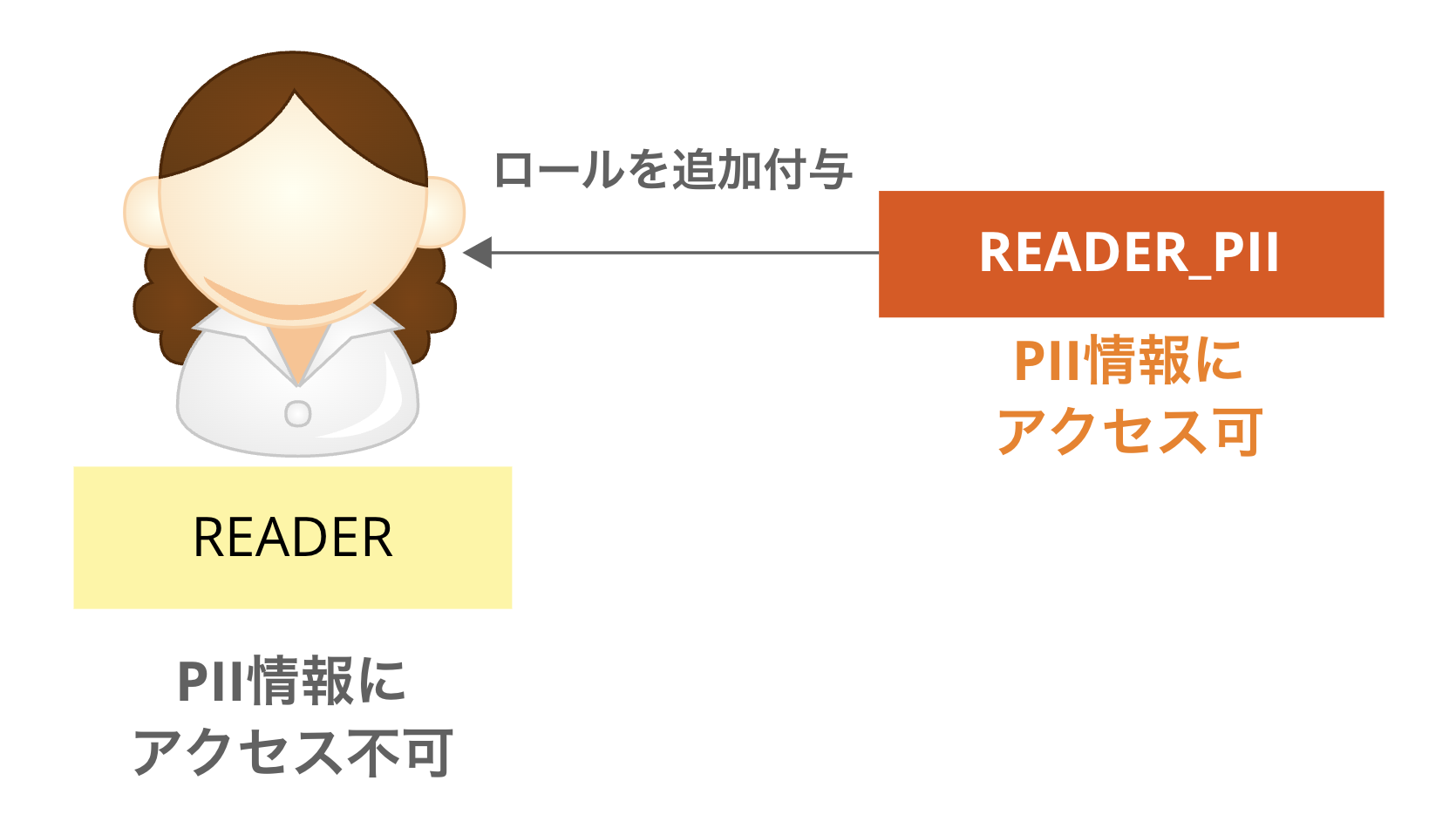
PIIアクセス可能なロールの管理方法
運用では、DBにアクセス可能なロールとPIIにアクセスできるロールの2つを用意しており、利用者がPIIへアクセスする場合は、
2つのロールを付与する形にしています。
以下画像の「READER」と「READER_PII」はそれぞれSnowflakeのロールです。
これはセキュリティにおける「最小権限の原則」に基づいており、操作ごとにロールを分けて設計しているためです。
仮に今後、PIIの閲覧範囲を細分化する必要があった場合でも、ロールを増やして追加付与するだけで、利用者の操作権限を細かく制御できます。
また、Snowflakeの権限機能もRBAC(Role Base Access Control)モデルが採用されているので、サービスの思想とも合致しており、無理なく運用できます。
さて、ここまで書いた通りPIIを閲覧できる仕組みを構築して、ロールを用意しましたが、実際にはどのような基準で利用者にロールを付与すればよいのでしょう?
「PII見たいです〜」と言われたから、はいどうぞ、という訳にはいきません。
「業務上、PIIを閲覧する必要がある」人にだけ権限を付与するべきです。
ロール付与基準として考えること
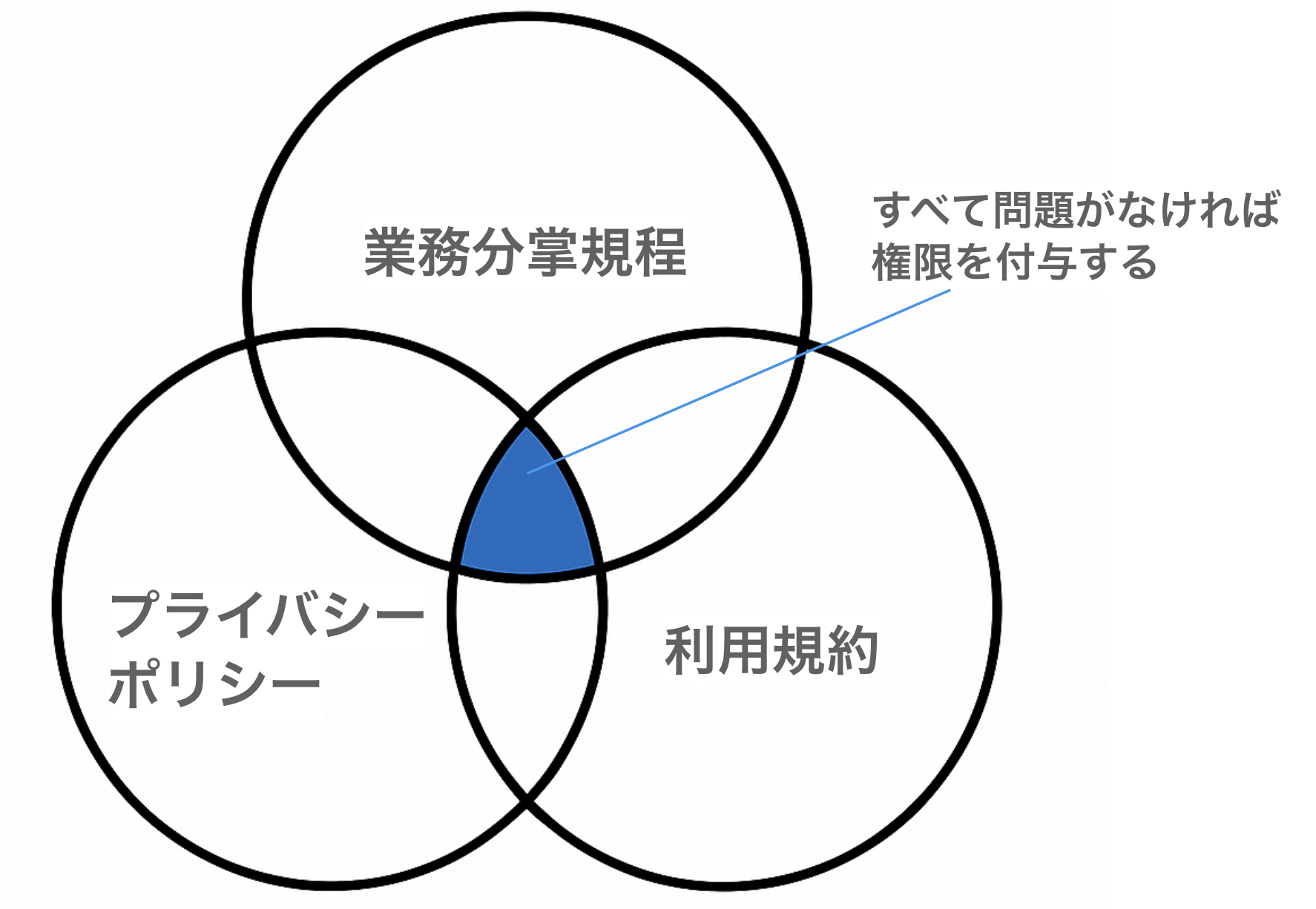
そこで基準となるドキュメントが3つあります。
- プライバシーポリシー
- 利用規約
- 業務分掌規程
まず、考慮するべきはプライバシーポリシーと利用規約です。
プライバシーポリシーと利用規約には、データの取り扱いに関する記述があるので、規約に書かれた内容での利用を想定しているかを確認する必要があります。
これはデータ利用する上で基本的なこととなりますので、規約から逸脱した利用を目的にPIIへアクセスしようとしている場合、許可することはできません。
次に確認するのは「業務分掌規程」です。
「業務分掌規程」とは、組織内の部署ごとに業務や権限が明確化された資料で、ここには「その部署では、どのような業務を行うか」が書かれています。
業務分掌規程にかかれている業務内容が、PIIを閲覧する必要がある業務であれば、許可することができます。
その部署内で全員がその業務を行うわけではなく、一部担当者のみPIIを使用する、というケースもありますが、そういうときは、権限を要求している人が該当の業務に従事しているかどうかを、所属長が判断することになります。
ヌーラボでは、これらのドキュメントを判断材料として、利用者へのPIIアクセスを許可しています。
また、会社によっては「業務分掌規程なんか作ってないよ!」という会社さんもあるかもしれません。その場合でも、最低限プライバシーポリシーと利用規約にそったデータ利用かどうかは、必ず確認しておくことをおすすめします。
仮に、意図せずプライバシーポリシー・利用規約から逸脱した利用をしていてそれが発覚した場合、企業価値を大きく毀損し、最悪のケースにいたる可能性も考えられます。
さいごに
さて、本記事でお伝えしたかったことをまとめます。
- 安全にデータ活用をしてもらうために、利用者ごとに閲覧可能範囲を制御する必要がある
- 利用者が見る必要がないデータはマスキングする
- データの種類を整理して、それぞれに対してマスキングのレベルを定義する
- マスキングのレベルにあわせたマスキング処理を採用する
- ロールは操作権限ごとに細かく作成しておく
- 権限付与は、プライバシーポリシー・利用規約・業務分掌規程の3つの観点から判断する
データ基盤を構築・活用する上でセキュリティはとても重要な要素です。
何か事故があった場合、自社はもちろんのこと、社会に対しても大きな損害を出す可能性があります。
データを安全に利用する、ということを実現するのは、動的マスキングなどの技術的なことだけではありません。
データ基盤を運用していく中で、安全性を担保していかないといけません。
運用が進めば扱うデータも増えていくので、その時に迅速かつ柔軟に対応できるようにしておく必要があります。
また、権限付与の基準も整備しておかないと、各部署の管理者がアクセス可否を判断することができないでしょう。
データを安全に使う、と一言で簡単に言ってみても、考えることは山ほどありますし、はっきり言って大変です。
また時間が経てば事業環境も、組織規模も変わっていくので、「安全なデータ利用とは」はずっと考え続けるテーマになります。
しかし、強いデータ基盤を構築する中で、これは絶対に避けては通れない道だと思っています。
データ基盤運用の道、果てしないですが楽しくもありますね。
本記事が、少しでもデータを扱う皆様のお力になれたなら幸いです。
それでは。
