<この記事はヌーラボブログリレー2025 冬 Tech の6日目として投稿しています。>
サービス開発部の伊藤です。
ビジネスチャットツール Typetalk は、2025年12月1日をもちましてサービスを終了いたしました。長らくのご愛顧、誠にありがとうございました。
https://nulab.com/ja/blog/typetalk/announcement-close-of-typetalk/
https://x.com/nulabjp/status/1995402498333720980
サービス終了に際し、2024年2月に「エクスポート機能」をリリースしました。これまでの皆様のやり取りを資産として取り出し保管できるよう開発した機能ですが、ご活用いただけましたでしょうか。
「念のためデータは出してみたけれど、zipファイルのままストレージに眠っている……」という方も多いかもしれません。
目次
過去の会話、どうやって探していますか?
Typetalk の過去のやりとりを確認したい場合、どうしていますか?
エクスポートしたデータから特定の話題を探す際、単純な「単語検索」だけでは限界があります。ヒットはしても「結局どういう文脈でその話になったのか」を理解するには、大量のCSVデータを読み解く苦労が伴うからです。
そこで提案したいのが、GoogleのAIノートブック「NotebookLM」にTypetalkのデータを読み込ませる方法です。
NotebookLMに会話データを学習させると、「◯◯について、過去にどんな議論があった?」といった曖昧な問いかけに対して、文脈を汲み取った回答をくれるようになります。今回はその具体的なセットアップ手順と活用例をご紹介します。
活用例
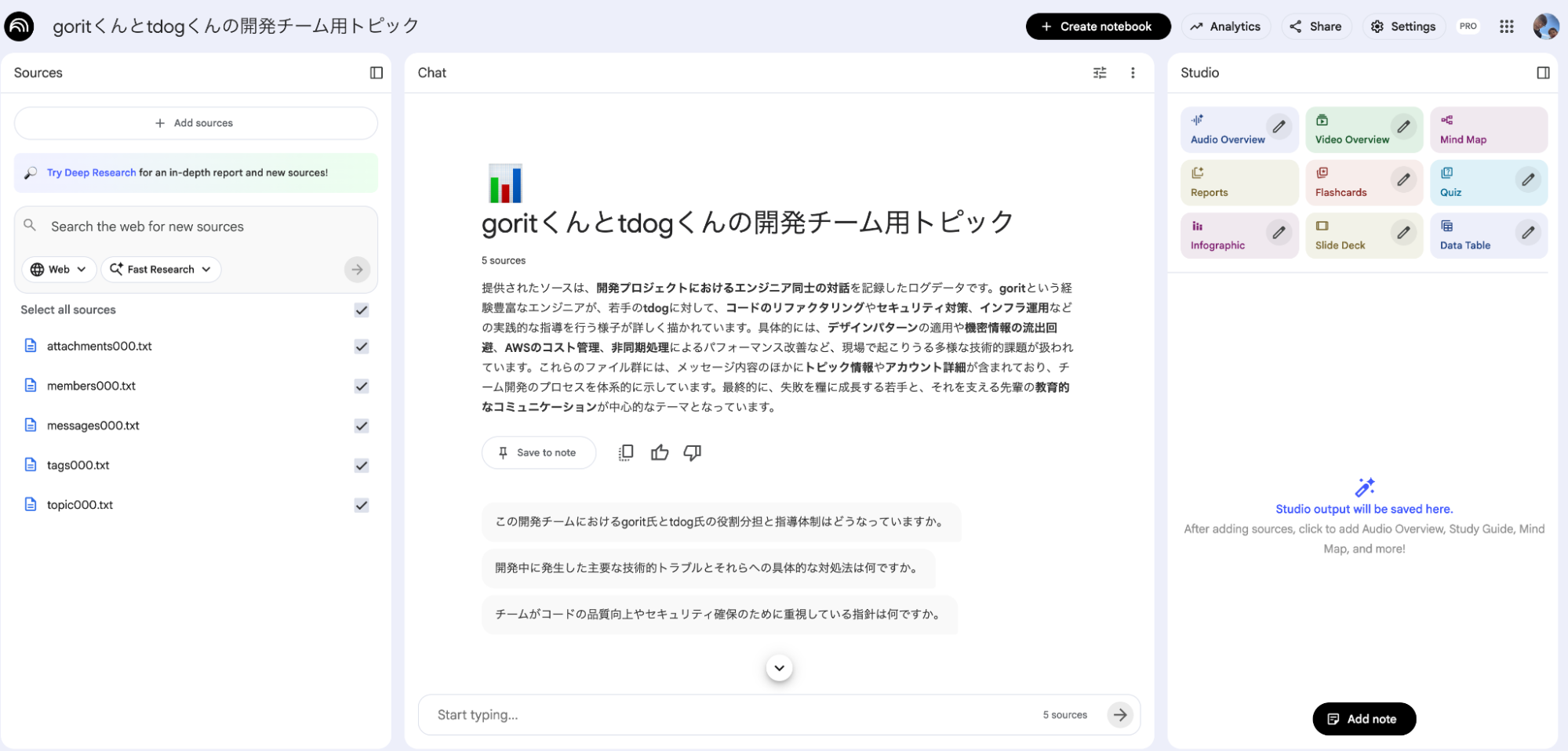
具体的にどんな体験になるのか、架空の開発チームの会話データ(登場人物:goritくん、tdogくん)を読み込ませた例を見てみましょう。
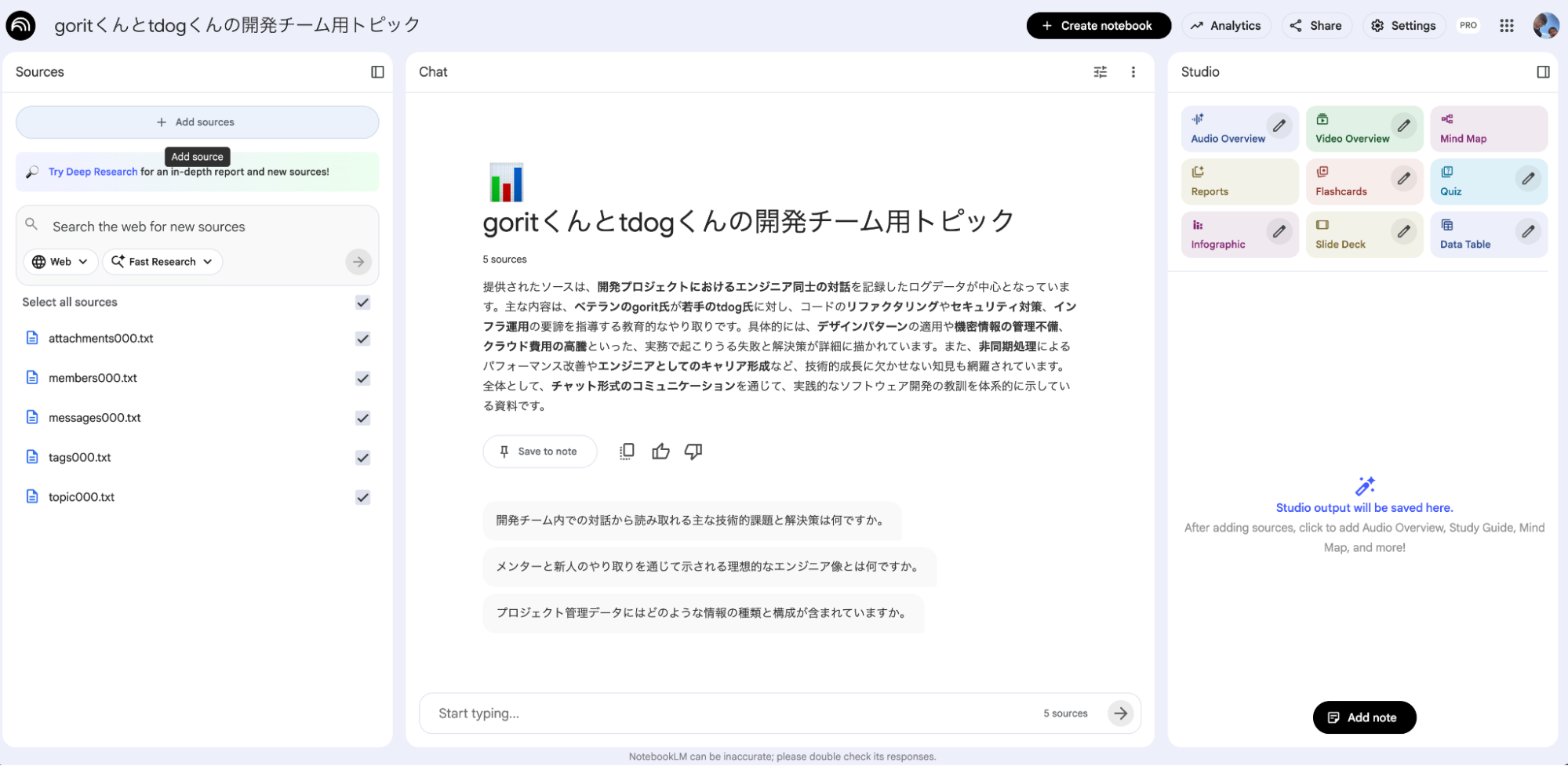
質問:これまでの技術的課題と解決策を教えて
質問すると、NotebookLMが登録された会話データを解析し、箇条書きで回答を生成します。ファジーな問いかけに対しても、文脈をとらえて回答をくれます。
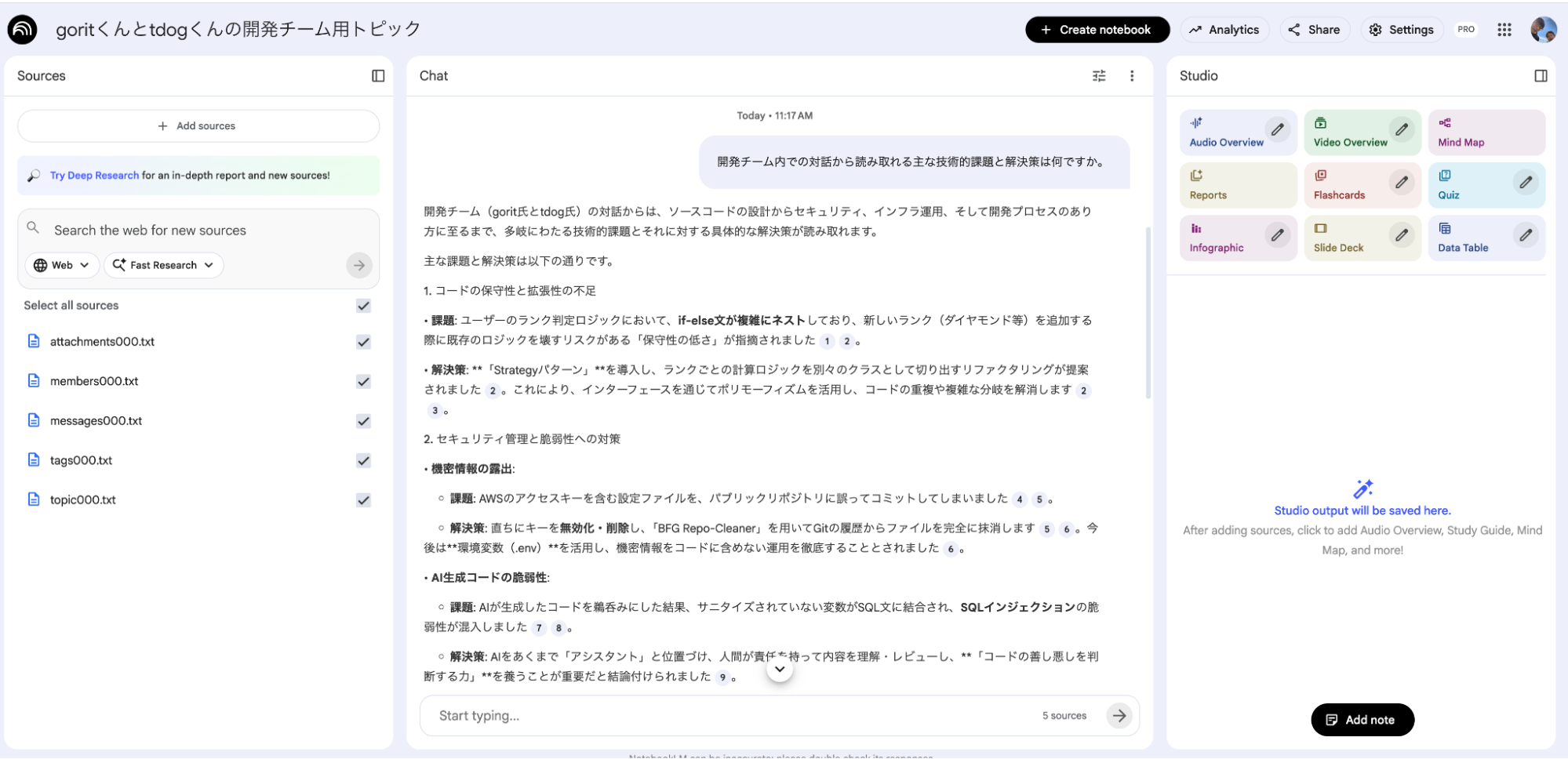
回答の「根拠」にすぐ飛べる
回答内の引用番号(1, 2…)をクリックすると、ソースとなった元の発言へ即座にジャンプできます。AIの回答にハルシネーション(もっともらしい嘘)が含まれる可能性はゼロではありませんが、引用機能を使えば即座に一次情報を確認できるため、「その回答をした根拠はなにか」にすぐにアクセスすることで効率と正確性のバランスをうまく取ることができます。
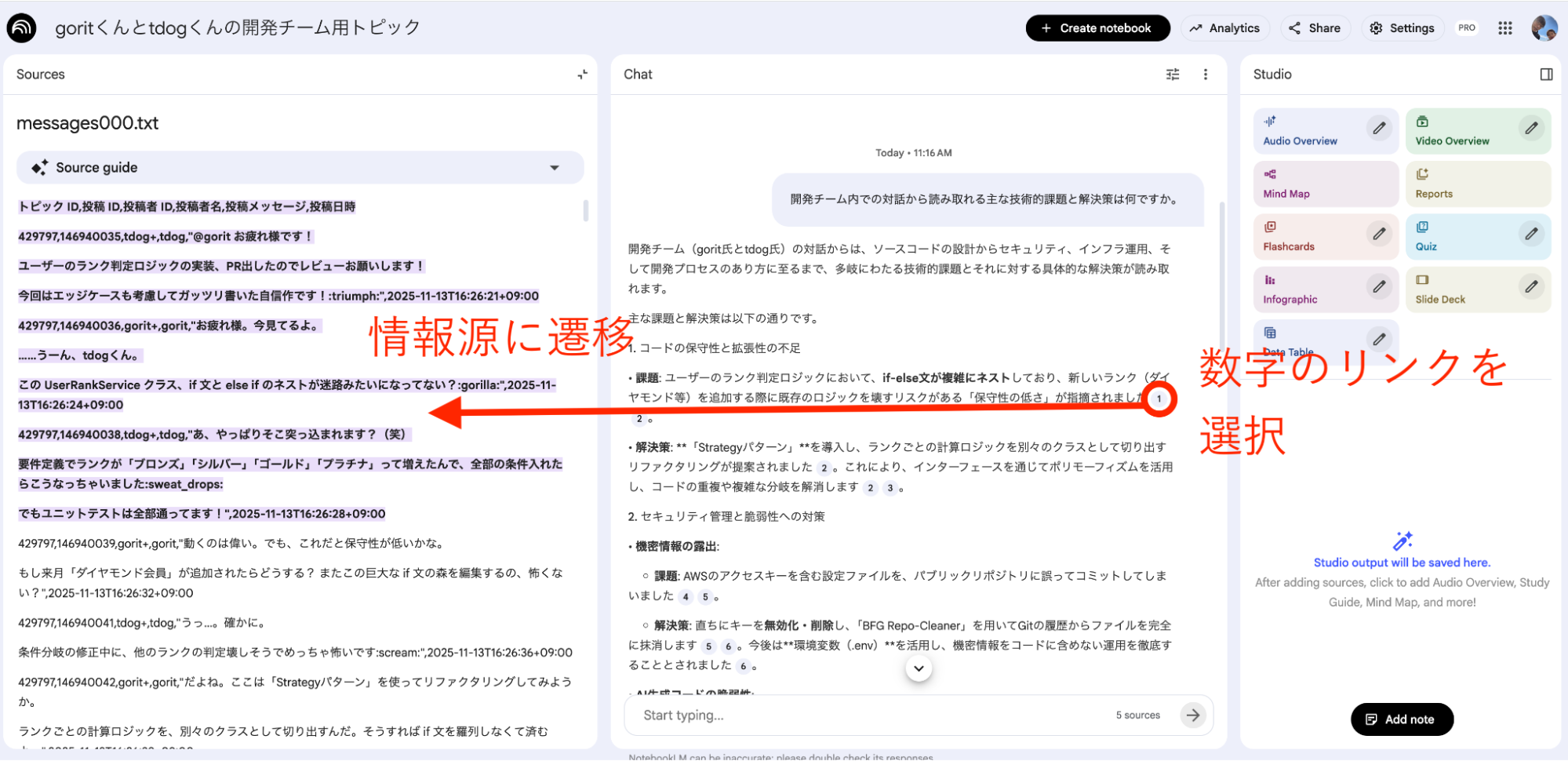
AIの回答が正しいかどうかは注意が必要ですが、自分でいちから会話に目を通して全ての文脈を把握することに比べれば格段に労力が少なく済みます。
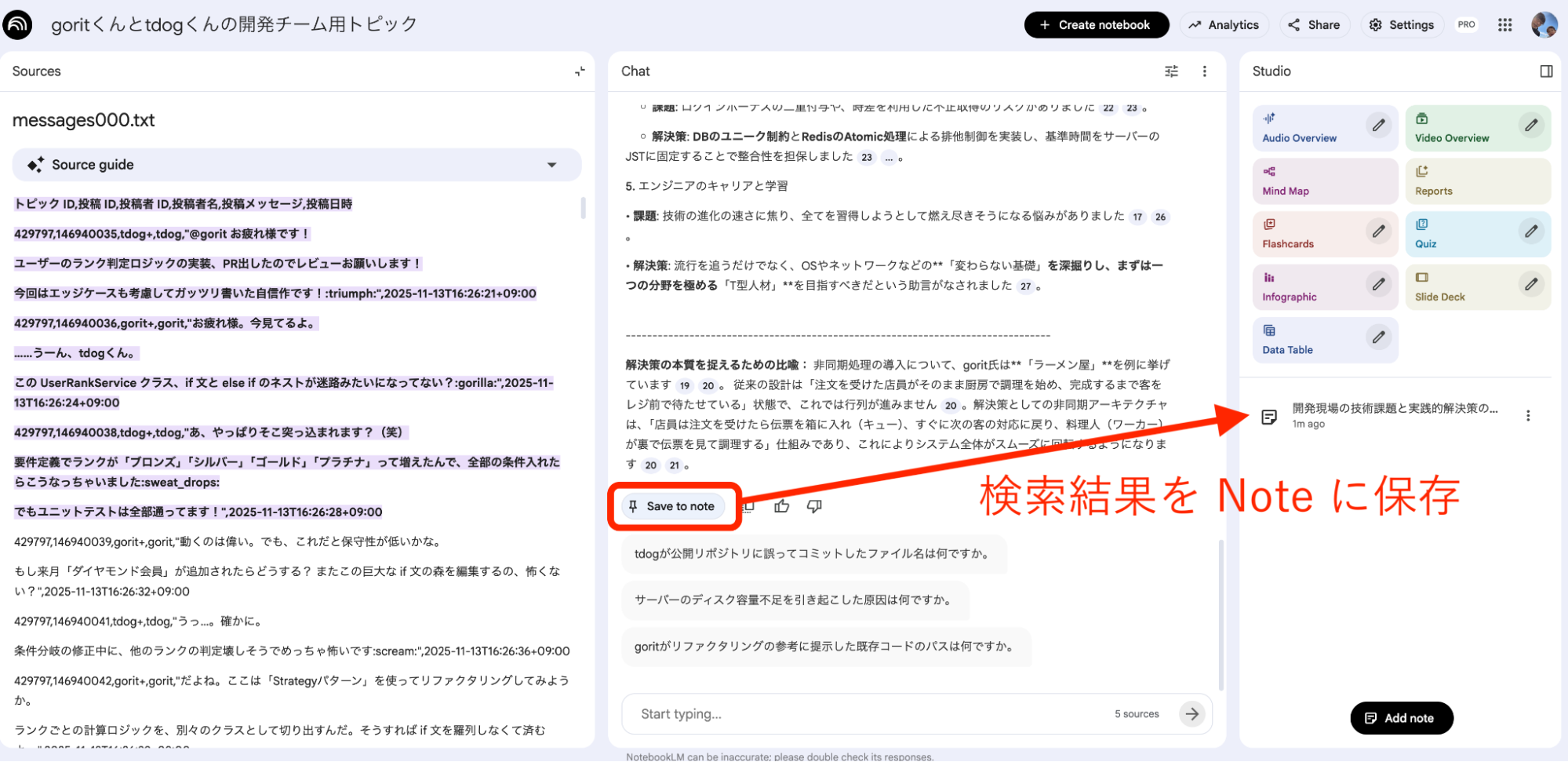
検索結果を「Note」で共有・保存
重要なやり取りは [Save to note] 機能でスナップショットとして残せます。自分用の備忘録としてはもちろん、他のメンバーへの共有も簡単に行えるため、情報の再利用がスムーズになります。
他にも、NotebookLMには要約機能やレポーティング機能など、データを扱いやすく加工できる機能があります。これらと組み合わせることで、Typetalk上でおこなった過去のやりとりを情報資産として活用しやすくなるのではないでしょうか。ぜひお試しください。
NotebookLMのセットアップ手順
Typetalk からエクスポートしたデータを、NotebookLM にインポート可能な形式へ加工する手順を解説します。ここからは、Mac環境前提でのセットアップ手順になります。
1. データの準備
エクスポートしたzipファイルを解凍します。 (例:429797-sample project-20251118_070311.zip)
解凍すると、以下のような構成になっています。
├── attachments.csv ├── members.csv ├── messages.csv ├── tags.csv └── topic.csv
2. ディレクトリへ移動
ターミナルを開き、解凍したディレクトリへ移動します。
cd ~/Downloads/429797-sample project-20251118_070311
3. NotebookLM用にデータを変換・分割
以下のコマンドを実行し、ファイルを加工します。
mkdir -p sources && for f in *.csv; do gsplit -l 5000 -d -a 3 "$f" "sources/${f%.*}" --additional-suffix=.txt; done
加工のポイント
- ファイル分割: NotebookLMの1ファイルあたりの容量制限を考慮し、5000行ごとに分割しています。
- 拡張子の変更:
.csvだと拡張子が対応しておらずインポートできないため、.txtに変換しています。 - gsplitの利用: Mac標準の
splitコマンドでは細かい指定が難しいため、gsplitコマンドを使用します。未導入の方はbrew install coreutilsでインストール可能です。 - ファイル出力先: sources というディレクトリを生成し、加工済みファイルはそこへ格納されます。後の手順で、これらのファイルを NotebookLM へ登録します。
4. NotebookLMへインポート
- NotebookLM を開き、[Create notebook] を選択。
- [Add sources] から、先ほど作成した
sourcesフォルダ内のファイルをすべてアップロードします。
以上で、あなただけの「TypetalkアーカイブAI」の完成です。
チームで使ってみて感じたこと
正直、最初は「わざわざAIに入れる必要はあるかな?」と思っていましたが、結果としてNotebookLM をセットアップしておいて良かったと感じる場面はしばしばありました。
本来、重要な決定事項は Backlog 等のプロジェクト管理ツールにタスクやドキュメントとして集約されるべきです。チャットというのはデータが流れる場であり、データを貯める場所ではないからです。しかし、どれだけ整理を心がけても「あの時の具体的なやりとりを確認したい」という場面は発生します。
リアルタイムで非定型なチャットのやり取りの中にこそ、チーム活動の「熱量」や「文脈」が刻まれているのもまた事実。それら一つ一つがチームがコラボレーションした軌跡でもあります。いつ必要になるかはわからなくとも、それらを目に見える資産として「いつでも取り出せる」状態にしておくことは、チームにとって大きな安心感に繋がると実感しました。
Typetalk のデータが手元にある方は、ぜひこの「情報資産化」を試してみてください。
