ヌーラボの@vvatanabeです。本記事では「BacklogのGitを支えるGitチームの紹介2022」ということで、Gitチームがどのようなシステムを開発・運用しているのか、どんなことを大切にして仕事をしているのか、具体的な日々の業務プロセスを例に挙げてご紹介します。
※ 本記事は JBUG福岡 #14 で発表した内容をブログ化したものです。
スライド:
https://speakerdeck.com/nulabinc/introduction-for-git-team-supporting-backlog-git-2022
目次
立ち位置とScope of Work
GitチームはBacklogのGitホスティング機能を全面的に担当しています。フロントエンド・バックエンド開発、インフラ構築、運用、QAまで責任を持ちます。所謂フルサイクルに近いエンジニアリングチームです。メンバーの数は2022年12月時点で3名です。「Git初心者でも安心して安全に利用できるGitホスティングを提供しよう」という目標のもと日々の業務に取り組んでいます。
具体的な業務の例
具体的には、Gitホスティング機能に関する次のような業務に携わっています。
開発:
不具合修正、既存機能の改善、新機能の開発等が挙げられます。
運用:
各種サーバー(EC2、ECS)、リポジトリを保持するストレージ(EBS)のメンテナンス、AWSリソースのランニングコストの削減等が挙げられます。
その他:
自分達が管理するアプリケーションのデプロイメントパイプラインの整備、サポートチームからエスカレーションされた問い合わせの二次調査なども定常的な業務の一つです。
大切にしている流儀
Gitチームがチームとして円滑に働くために合意の上で大切にしていることを紹介します。次の項目はその一部です。
- タスクの属人化を減らそう。
- 近い未来を当てにいこう。
- 心理的安全性を高めよう。
- 業務で得た技術や知見を積極的に社外発信しよう。
タスクの属人化を減らそう
フロントエンド、バックエンド、インフラ等、メンバー毎に得意・不得意な領域があり、タスクに種類によっては誰が速くできるのか変わってきます。しかし、チーム内でタスクを属人化させたくありません。例えば、Gitホスティングのあるリクエストのパフォーマンスを改善したい時や、新しい機能を実装する時に、各メンバーがフロントエンド、バックエンド、インフラの何処を改修するのが最適なのかシステム全体を俯瞰して調査できれば、メンバー個々の技術的な理由が改修作業のボトルネックにならずに済みます。また、特定のメンバーだけに依存した緊急時のオペレーションを減らせば、突発的に休暇が必要になっても他のメンバーがカバーできるため安心して休暇を取れます。タスクの属人化を減らすためには、少しずつでも得意な領域以外の部分に触れていくしかありません。Gitチームでは、得意な人から積極的にペアプログラミング・ペアオペレーションを提案したり、効率的なオンボーディングを実施するためにドキュメントを定期的にアップデートするといったことを心掛けています。
近い未来を当てにいこう
プロジェクトの規模が大きくなり、計画上のゴールが1年先になるような遠い未来の計画を当てるのはとても困難です。しかし、近い未来、1スプリント(Gitチームでは一週間)の計画くらいは、工夫次第で確実に当てに行けるはずです。近い未来の計画を当て続けることによって、結果的に遠い未来の計画のズレを抑えることができます。例えば、なにかしら大きな機能開発があり、全ての要求仕様が満たせるまで2、3ヶ月掛かりそうな場合、それ単体で価値の在る小さな機能(ユーザーストーリー)としてタスクを分割します。そのタスクは1プリントで終わる程度の分量です。この小さな機能単位でPdMのレビューを受けます。また、ベロシティを過大評価しないように注意しています。実際に、前回のスプリントのベロシティが高くても、次回のスプリントは同様に速く進めなかったことはよくありました。現実的な計画を立てる上で自分達のチーム・プロジェクトのリズムを掴むことを重要視しています。
心理的安全性を高めよう
リモートワークが普及した昨今、オンライン主体のコミュニケーションが増え、顔が見えないことで相手の感情がわかりにくくて、発言がしにくかったり、うまく自分の言いたいことを伝えられなかったり、といった問題が多くなってきました。チームとして最大のパフォーマンスを発揮するには、気軽に初歩的な質問ができる、反対意見を言える、失敗が許される、といった心理的安全性が大切だと思っています。そのため、 アサーティブ・コミュニケーションと呼ばれる、お互いの立場や主張を大切にした、自己主張・自己表現に注目しています。
業務で得た技術や知見を積極的に社外発信しよう
技術や知見を体系的にまとめることで自信の理解が深まります。さらに、まとまったドキュメントはオンボーディングでも活用できますし、未来の自分達の「あれってどうなってたっけ?」を救います。ニッチな技術でも誰かの救いや参考になることもあります。次のリンクは、Gitチームが1年くらいで書いたブログやスライドです。
- お手軽Gitリポジトリ分析
- ECS Fargate+Mackerelにおける監視費用を削減するまでの話
- インフラのテストに VPC Reachability Analyzer は外せないという話
- 複数のアプリケーションを横断する処理のボトルネックを追跡し改善した話
- 大容量のストレージを持つサーバーの奇妙なメモリ使用量の増加原因を究明した話
- OpenSSHのプロトコル拡張「UpdateHostKeys」の仕組みと実装
- チームでサービスの運用をうまく支えていくための取り組みについて ~SREを添えて~
- 僕たちとECSとデプロイとその改善
- BacklogのGitホスティングにおける冗長化と負荷分散の仕組み
- OpenSSHがSHA-1を使用したRSA署名を廃止、BacklogのGitで発生した問題と解決にいたるまでの道のり
- スモールチームにおけるAutifyを用いた効率的なE2Eテストの自動化
一週間の仕事の流れ
次の図はGitチームの一週間の仕事の流れを表した図です。もともと水曜日にBacklog全体のミーティングが集中する傾向にあったので、あえてScrum Ceremonyを水曜日に設定して、他の曜日はタスクに集中できるように工夫しています。次に各ミーティングの詳細を解説します。
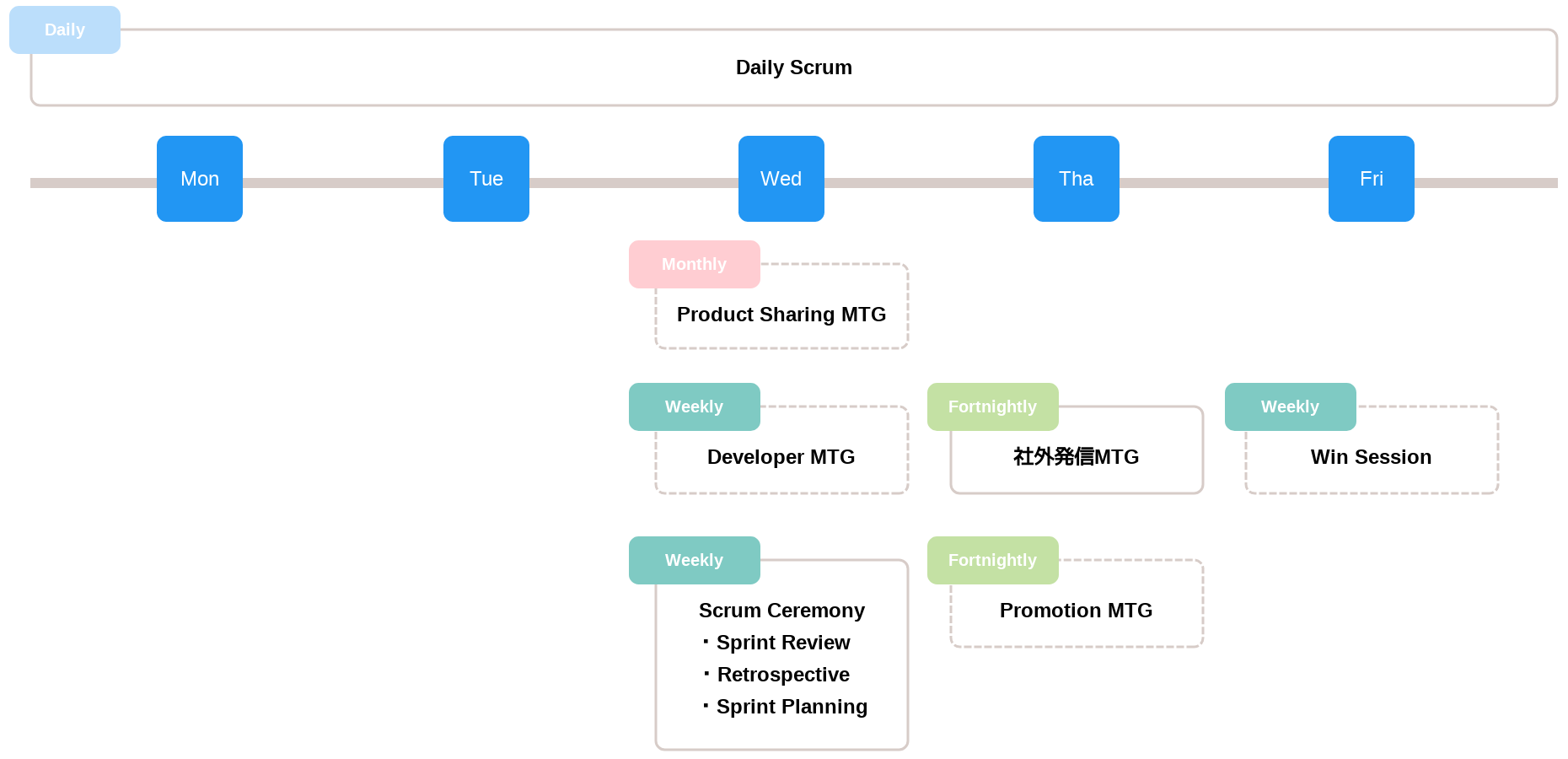
Daily Scrum(30min)
毎朝、Gitチーム全員で行います。Sprint Planningで立てた計画をもとに、今日やること、進捗状況を確認します。業務のちょっとした相談であれば、Daily Scrum内で話すこともありますが、基本的に困ったときは日中いつもで相談できるように心掛けています。また、前日の各種アプリケーション・AWSリソースのアラートやメトリクスも確認します。運用しているシステムの状況を知る時間を作りシステムの傾向を把握するためです。詳しくは次のブログでも紹介しています。
チームでサービスの運用をうまく支えていくための取り組みについて ~SREを添えて~
この取り組みのおかげで、実際に問題を検知して改善に繋げたケースもあります。次のブログでその取組みの一部を紹介しています。
大容量のストレージを持つサーバーの奇妙なメモリ使用量の増加原因を究明した話
Scrum Ceremony(2.5hour)
1スプリントを1週間で設定しているので、毎週、Gitチーム全員 + スクラムマスター(他チームの@jue_no58に依頼)で行います。主に次のスクラムイベントを実施しています。
- Sprint Review
- Retrospective
- Sprint Planning
Gitチームはスクラムの知識が豊富なわけではありません。スクラムに慣れた同僚にミーティングの進行やスクラム的な作法のチェックなどサポートしてもらうことで、チームが本質的な議論に集中できるように工夫しています。
Sprint Review
そのスプリントで計画していた機能(ユーザーストーリー)のデモを行いPdM(@Shiroaki0)のレビューを受けます。デモの準備を怠らないように心掛けています。準備を怠るとグダりやすく、無駄に時間がかかってしまってPdMもレビューしにくくなってしまうので、デモ担当者を決めてSprint Reviewの前に簡単なリハーサルを行います。
Retrospective
次回のスプリントが今回のスプリントよりうまくいくためにできることを考えます。
- なにがうまくいったか
- どのような問題が発生したか
- その問題がどのように解決されたか(されなかったか)
といった観点で議論して、次回のスプリントでやること(Action Item)を決めます。KPTやStarfishといった手法を使っていた時期もありましたが、現在はこのシンプルな手法に落ち着いています。
Sprint Planning
次のスプリントで行う取り組むタスクについて計画します。以下は計画の基本的な流れです。
- チームが次のスプリントでどれだけ稼働できるのか把握する
- 次のスプリントでやるべき機能開発以外のタスクを確認する(システムの運用作業、他チームからの調査依頼等)
- ユーザーストーリ一の一覧から優先順位に沿って選択する
- ユーザーストーリ一をスプリントバックログに細分化する
- 直近2スプリントのベロシティをもとに現実性のある計画に調整する
4. でユーザーストーリーをスプリントバックログに細分化する時は、具体的にどのリポジトリの、どの辺りのコードを、どのように改修するのか、といったところまで掘り下げて会話します。やはり時間はかかりますが、やることが明確になるので見積もりの精度も高くなります。
その他
技術発信MTG(30min)
隔週、Gitチーム全員で行います。普段の業務で得た技術や知見をどのように社外発信できるか話し合う場です。アウトプットのネタを社外発信管理シートに記録しています。いざブログを書こうという時に、まとまったネタ帳があると筆の初速が速くなります。
Win Session(30min)
Backlogに関わる全社員(任意)で行います。各チームで1週間の成果を共有し承認・賞賛する場です。
Developer MTG(1hour以下)
毎週、Backlogのエンジニア全員(任意)で行います。エンジニアへの情報共有、開発状況を確認する場です。
Product Sharing MTG(1hour以下)
毎月、Backlogの各チームの代表とPdMで行います。各チームの進捗状況をPdMと共有する場です。
Promotion MTG(1hour以下)
隔週、Backlogの開発チームの代表とマーケティングチームで行います。プロモーションに関連する情報を共有する場です。
開発・運用しているシステム
Gitホスティング機能のシステムの概観
以下の図はBacklogのシステム全体からGitホスティング機能を中心に切り出したアーキテクチャの外観です。複数のアプリケーションが連携してユーザーのリクエストを処理する構成になっています。
※ここでは図を簡素化するために、アベイラビリティゾーン、VPC、サブネット、ロードバランサーなどは省略しています。実際は各コンポーネントを複数のアベイラビリティゾーンに配備しています。
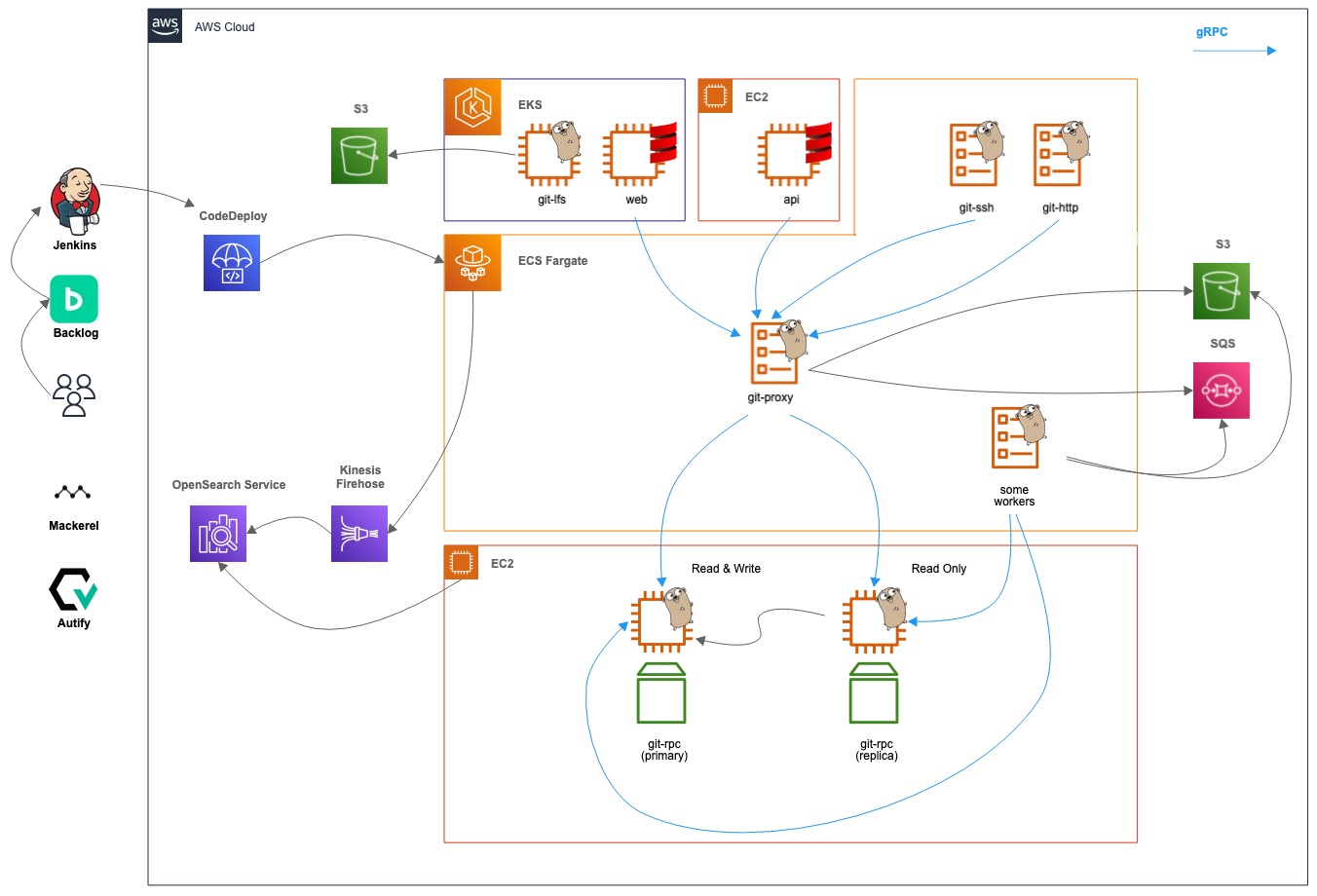
詳しくは次のブログで解説しているので、興味を持たれた方は是非ご一読ください。
よく使用する技術要素
次の表はGitチームが良く使用する技術要素です。

前述のシステム構成にある通り、バックエンドのアプリケーションは主にScalaとGoで開発されています。各アプリケーションの内部的な通信にはgRPCを使用しています。
フロントエンドは静的型付けのHaxeを使ってJavaScriptをトランスパイルしています。フレームワークはMVVMパターンのKnockout.jsを使っています。補足ですが、現在Backlog全体のフロントエンド技術のコアとしてReact + Typescriptが選択されており、主にBacklogのIssue機能から徐々に刷新されています。
インフラは前述のシステム構成にある通りAWSです。その中でもGitホスティングで良く使用するものとして、EC2、ECS Fargate、EBS、SQS、S3、CodeDeploy、OpenSearch Service等が挙げられます。
その他ツールに関しては、自社で開発しているサービスをドッグフーディングするため、プロジェクト・ソースコード管理はBacklog、ダイアグラムの作成はCacoo、チャットはTypetalkを使用しています。その他、E2Eテストの自動化のためにAutifyを導入しました。詳しくは次のブログで紹介しています。
スモールチームにおけるAutifyを用いた効率的なE2Eテストの自動化
最後に
Gitチームの業務内容、流儀、仕事のプロセス、開発運用しているシステム、使用している技術の一部を紹介しました。Backlogに携わるチームについて少しでも知っていただければ幸いです。他にもBacklogのエンジニアの話を聞いてみたいと思った方は、是非「ヌーラバーの話を聞いてみたい」から登録お願いします。
