John Debs watched the system administrator, perplexed.
As a development intern at a medium-sized company, he had noticed the technician moving slowly from computer to computer. Soon it dawned on him. The systems administrator was installing a security patch on each machine, individually. All 250 of them.
“Why don’t you just script it?” John asked. The sysadmin mumbled something unconvincing and persisted with his painstaking task.
Years later, the memory has still left a deep impression on John, who went on to become a DevOps engineer for Lua Technologies and now works freelance: “He didn’t care about improving the process for himself or other people.”
That’s where DevOps comes in.
What is DevOps?
DevOps is a work philosophy that prioritizes collaboration between the people responsible for creating software (developers) and the people responsible for maintaining it (operations engineers). That’s where the term comes from: Development + Operations = DevOps. At some companies, these two roles are even collapsed into one: Full cycle engineers, like the ones at Netflix, operate the same software that they build.
But collaboration is just one piece of the puzzle. At its core, DevOps is about streamlining engineering processes in order to improve business outcomes.
Teams using DevOps standardize and often automate repetitive procedures, such as pushing software changes or setting up new virtual servers. They use principles borrowed from lean manufacturing—pioneered by Toyota factories in the 1950s—and agile development to efficiently manage the flow of work from inception to operation.
DevOps also emphasizes experimentation and creativity, using short software development cycles to deploy many small, frequent updates instead of a few large ones. This allows teams to quickly create value for their end users. Using DevOps practices, releasing a great new feature or fixing a pesky bug takes hours or days, rather than weeks or months.
What DevOps Isn’t
DevOps isn’t a role.
DevOps is a team responsibility. While some companies do have roles dedicated to leading the transition from a traditional project management framework to a DevOps one, or ones that advocate for DevOps on an ongoing basis, as John Debs puts it, “DevOps is about getting the whole engineering team involved in the process.”
DevOps isn’t a product you can buy.
While there are plenty of tools that you can use to support DevOps processes, DevOps isn’t software—it’s a mindset. Daphne Reed, Director of Information Security at Vidyard, puts it this way, “Tools are the building blocks which allow the DevOps mentality to thrive.”
DevOps isn’t systems administration.
“When higher-ups look at DevOps, they sometimes confuse it with systems administration,” says Gaurav Murghai, CEO at Softobiz. DevOps is so much more. It’s a cultural change which not only integrates development and operations teams but also helps operations teams automate traditionally manual administrative tasks. Managing the development pipeline, creating scripts, and standardizing procedures are all outside the scope of traditional systems administration work.
DevOps isn’t always easy. (But it’s worth it!)
It takes time to evaluate your existing workflows, devise ways to improve your processes, and shift peoples’ mindsets. Developers and operations engineers can’t learn new skills or take on new responsibilities overnight. They need time to learn and gain experience. Even though it might take some time, in the long run, the benefits of DevOps—better teamwork, more efficient development cycles, fewer outages, and shorter time to value—are worth it.
Before DevOps: The Traditional Software Development Life Cycle
Historically, most companies divided development and operations into two teams: Development would design, write, and test code, then “throw it over the wall” to operations, who would then allocate server space, deploy the code, and take care of ongoing maintenance, such as patches and updates.
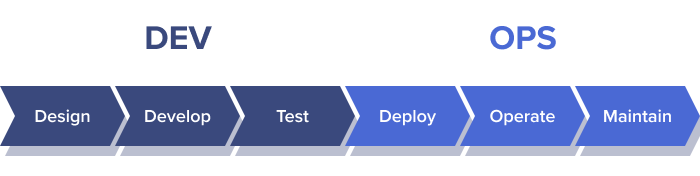
At large companies, this divide could be so profound that every stage in the process was the responsibility of a separate role. Before implementing DevOps, Netflix’s development cycle looked like this:
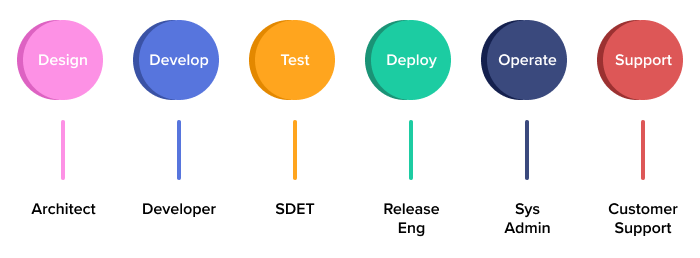
Problems with the Traditional Software Development Life Cycle
Separating the people who create software from the people who operate and maintain it can cause huge problems for engineering teams. Miscommunications can easily occur, delaying or completely derailing scheduled deployments. For instance, a development team might not adequately scope the infrastructure requirements of a new release, causing operations to scramble to set up new servers at the last second. Or operations might search fruitlessly for the cause of an error, never thinking to talk to the developer who wrote the code in the first place.
The result is a finger-pointing blame game which fosters competition and even hostility between the two teams. Dialogue starts to sound like this:
—Your code is broken, not my machines!
—My code is fine, your servers are the problem!
Not very conducive to collaboration. But in the late 2000s and early 2010s, dialogues like this one were playing out across a wide range of companies. Any business who depended on software to sell its products struggled as a result of the disconnect. Soon enough, developers and operations engineers alike began to grow weary of the gap.
The Birth of DevOps
As frustrations simmered, engineers began to look for a better way. At the 2008 Agile Conference in Toronto, Patrick Debois and Andrew Schafer were already beginning to discuss how they could apply agile development principles to systems administration. But the real turning point happened the following year, at the 2009 O’Reilly Velocity Conference when two Flickr employees, John Allspaw and Paul Hanmmond gave a presentation: “10+ Deploys Per Day: Dev and Ops Cooperation at Flickr.” The DevOps movement was born.
In parallel to these new approaches, advances in technology created an environment in which collaboration, systematization, and automation could thrive. In particular, cloud computing allowed companies to efficiently manage their servers through virtual, rather than physical, networks.
The Impact of Virtualization
The shift to the cloud enabled companies to stop treating their servers like “pets” and start treating them like “cattle” (a metaphor dreamt up by Bill Baker while he was an Engineer at Microsoft).
Here’s how it goes: In a “pets” model, your servers all are configured manually. They have names, require individualized care and attention, and when they “get ill” (stop responding) you nurse them back to health. Caring for “pet” servers is a big part of the work done by traditional sysadmins. But in a “cattle” model, virtual servers are configured en masse by automated tools. They are numbered, maintained as a collective, and when they stop performing optimally, replaced with new ones—all with little to no human intervention. Any individual machine can fail without taking down the whole herd.
Because of this fundamental shift, the need for traditional sysadmins began to disappear, prompting many people from operations backgrounds to take on development responsibilities and more developers to play a more active role in operations.
The DevOps Software Development Life Cycle
Rather than divided roles and responsibilities, the DevOps software development life cycle emphasizes ongoing collaboration across all stages. The DevOps model removes the artificial barrier between people building software and people operating it, fostering inter-team cooperation. While members of integrated teams often still specialize, they all should understand how the system functions as a whole. “It’s like majors and minors in school,” says John Debs. While your “major” might be software development, you would also have a “minor” in operations or vice versa.
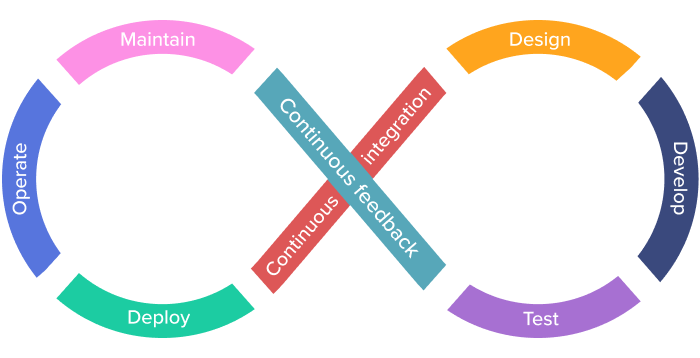
Why DevOps?
Collaborating across all phases of the software development cycle empowers teams to work together to resolve issues, instead of waiting on each other to fix them. As Netflix notes in a blog post, “Teams that feel operational pain are empowered to remediate the pain by changing their system design or code; they are responsible and accountable for both functions.”
Exposure to the entire development cycle also helps teams anticipate problems before they happen, instead of reacting to them as they occur. Being proactive allows teams to be more innovative—as Daphne Reed explains, “When you’re stressed, you’re not being creative. When you’re proactive and have time to think about what you’re doing, processes get slicker.”
By achieving smooth collaboration and continuously improving engineering processes, teams can optimize time to value. Using DevOps principles, teams work on minimizing the amount of time it takes to get from a great idea to a finished product—meaning their users see benefits, faster. A better user experience means happier customers, who will continue to use your products and recommend you to their friends. That’s a big win for your business.
And a bonus—DevOps creates a fantastic environment for professional growth. Ongoing learning and skill development are not only encouraged by managers but essential to team success. As a result, engineers are constantly expanding their knowledge and abilities.
The Development Pipeline
Fundamentally, DevOps is about managing the flow of engineering work, from the earliest phases of software design to implementation and maintenance—this is known as the development pipeline. Like the sales pipeline, the development pipeline acts to ensure a consistent flow of work, minimizing inefficiencies and preventing bottlenecks, which cause spikes of high stress interspersed by periods of boredom. No one wants to work like that.
If talking about the “flow of work” evokes images of a factory floor, you’re not far off: “DevOps is like an assembly line for software development,” says Gaurav Murghai. In fact, DevOps uses principles taken directly from lean manufacturing—combined with practices from agile development—to efficiently assemble software the same way that car manufacturers assemble vehicles. We’ll cover how this works in the next few sections.
The Three Ways
A good basis for understanding DevOps is “The Three Ways” outlined in The Phoenix Project, a 2013 novel co-written by three expert DevOps practitioners. These principles draw extensively from lean manufacturing and agile development practices. While additional models for understanding DevOps exist, such as CALMS—Culture Automation Lean Measurement Sharing—The Three Ways remains one of the most influential. Since the essence of the CALMS model is captured within The Three Ways, this explanation will focus on the latter.
Imagine a factory floor: On one side, there are raw materials and at the other, finished products. Between these two sides, the materials move from station to station, gradually transforming into finished products.
It may be strange to think of software creation as part of an assembly line—we’re dealing with virtual products, not physical ones—but like factory workers, engineering teams receive “orders” and have to deliver “finished goods.” These are things like:
- A new feature that the product team wants to implement
- A bug users have complained about that needs to be fixed
- An integration with another tool or partner company’s product
To manage these “orders” efficiently, from initial request to project completion, engineering teams can use some of the following strategies:
1. The First Way: Systems Thinking
One of the core principles of lean manufacturing is that a build-up of orders and excess inventory—in development terms, a backlog of work—slows down productivity. The same is true for virtual products. Letting work build up decreases worker productivity. Workers tend to prioritize what’s most urgent, which means that crucially important but non-urgent work is neglected, causing problems to compound. This is what’s known as “technical debt.”
To take control of their backlogs, engineering managers have to understand how work flows through their organization. One of the easiest ways to do this is through visualization. In The Phoenix Project, the team creates a “Kanban board” using index cards which organizes all of their ongoing projects—from request to completion. Today, most companies use virtual dashboards to manage requests, prioritize tasks, and track their projects.
Visualizing work this way not only removes confusion—everyone knows what their top priorities are—but it can also help managers identify bottlenecks, minimize them, and ensure work flows smoothly from planning to completion.
2. The Second Way: Amplify Feedback Loops
Having a system in place to ensure the smooth flow of work is just the start. What happens when things inevitably go wrong? The second way is all about detecting problems, resolving them quickly, and learning from them. The purpose of these processes is to create a feedback loop that reinforces quality from the earliest phases of software creation.
Here’s how it works: When a problem is detected—whether through automated error reporting or manual flagging—the top priority is to resolve it. If this can’t be done relatively quickly by a single person, the entire team stops whatever they’re doing, “swarming” the issue until it’s fixed.
At first glance, this might seem horribly inefficient. Stop everything for one little problem? But containing problems while they’re small and manageable stops them from spiraling out of control. Think back to the factory production line. One part of the system affects every other part. If a piece of manufacturing equipment stops working and needs to be fixed, allowing other parts of the production line to continue only increases the backlog of unfinished work, causing future bottlenecks.
Swarming problems as they happen allows teams to learn from them and put better systems in place. While this may temporarily slow down production, in the long term, it continually increases work speed and quality in a positive feedback loop.
3. The Third Way: Create a Culture of Continual Experimentation and Learning
Culture plays an important role in creating an environment of ongoing learning and improvement. In order to be able to amplify feedback loops, engineers need to feel comfortable flagging issues and interrupting their coworkers when a problem requires all hands on deck.
One way teams create a culture of experimentation and learning is by applying agile development principles. Agile is ideal for DevOps because of its focus on short-cycle timelines and consistent feedback. “In DevOps, you work in small batch sizes,” says Greg Jacoby, Bright Development Owner and Lead Developer. “You’re never doing a massive crazy update, you’re focusing on producing value for the end user.” This style of work results in better code quality, because frequent deploys allow developers to get more immediate feedback from users and improve their code accordingly. In order to execute agile effectively, teams use continuous integration, continuous delivery (CI/CD).
Continuous Integration, Continuous Delivery (CI/CD)
Since multiple programmers work together across different operating systems (and versions of those operating systems) to build software, they need to automate the process of integrating and validating code changes to support these multiple environments—this is what CI/CD does. It’s a DevOps best practice which creates consistent, automated processes to build, package, and test new code. (And helps prevent programmers from uttering the dreaded phrase: “But it works on my machine!”)
In order to cultivate a culture of experimentation and learning, it’s useful to introduce problems into the system, on purpose. Netflix has even created a tool—the aptly named “Chaos Monkey”—which “is responsible for randomly terminating instances in production to ensure that engineers implement their services to be resilient to instance failures.” (If you want a little Chaos Monkey of your own, it’s open source and available on Netflix’s GitHub.) These not only function as drills to prepare engineering teams for system failures, but they also function as a form of resilience engineering, ensuring safeguards are put into place to protect software from catastrophic failure.
DevOps and Security
With DevOps’ intense focus on increasing cycle speed, it might seem like DevOps practices are at odds with security. In fact, nothing could be further from the truth. Security is a critical component of DevOps because the philosophy places such a high value on user experience. It’s impossible to create a positive user experience if customers are afraid to trust you with their data. Some companies even refer to their DevOps philosophies as “DevSecOps.”
Teams practicing DevOps think about security considerations from the earliest phases of product design. It’s not something that’s tacked on as an afterthought—as Red Hat writes in their blog, “DevSecOps is about built-in security, not security that functions as a perimeter around apps and data.” Security checks are put into place at every phase of the development cycle. These checks ultimately save time, because they catch security vulnerabilities early in the process and don’t leave teams scrambling before a scheduled deployment.
DevOps Team Structures
We’ve covered some of the DevOps strategies used by teams to ensure smooth collaboration between development and operations, along with other
stakeholders, such as security. But what should this team configuration look like? According to Matthew Skelton and Matthew Païs who—quite literally—wrote the book on DevOps teams (their book is called Team Topologies), there isn’t one right answer. How you configure your team depends on several factors, including the size of your engineering department, your product offering, and your organizational maturity.
Here are the most successful DevOps team “types” according to the authors:
1. Dev and Ops Collaboration
In this model, Dev and Ops teams collaborate smoothly while maintaining their individual specialties. The two teams share a clearly defined common objective and engineers are comfortable seeking out members of the other team to share ideas and ask for advice. Achieving and maintaining this kind of harmony requires strong technical leadership and may necessitate a cultural change in the company.
Best for: Organizations with multiple product streams and/or development sub-teams
Example: Parts Unlimited, the fictional company featured in the DevOps-inspired novel The Phoenix Project
2. Fully Shared Ops Responsibilities
This is the “operate what you build” or full-cycle model. In this team structure, development and operations are merged into a single team with a shared mission. The operations team ceases to exist as a distinct entity because developers also take care of all operations responsibilities.
Best for: Organizations with a single primary product offering, usually web-based
Examples: Netflix and Facebook
3. DevOps Team with an Expiry Date
This team type functions as a transitional model to type #1 or #2. It’s a temporary solution used to create the culture shift needed to merge or foster collaboration between distinct development and operations teams. The temporary DevOps team eases the transition, acting as an advocate for DevOps practices, with the goal of making itself obsolete once DevOps processes become ingrained—ideally within 12-18 months.
Best for: Teams at the beginning of their DevOps journeys
4. SRE Team
This final model might not technically be a DevOps model, since product development remains separate from operations. Rather, this structure, which originated at Google, introduces a new team—the Site Reliability Engineering (SRE) team—made up of developers with ops expertise. After writing and testing their code, development hands it off to SRE, not operations, to put it into production. Crucially, SRE can reject code if it doesn’t meet their requirements, ensuring that only high-quality code is deployed.
Best for: Mature organizations with advanced engineering teams
Example: Google
How to Achieve DevOps Success
It can be tempting to rush to implement a DevOps framework, especially if your current software development process isn’t functioning as well as you’d like. Resist this impulse—as Greg Jacoby says, “Because DevOps is a conceptual framework, if you don’t set it up properly, it’s useless.” If you want DevOps to work in the long run, you have to ensure the changes you make are sustainable. Here’s how.
First Things First
Before jumping in, it’s important to evaluate whether DevOps is the right solution for your organization. “Sometimes your use case doesn’t match with what DevOps has to offer,” says Gaurav Murghai. “DevOps is great for projects where you’re consistently rolling out changes and updates, but it’s not as suited for maintaining a piece of software that you’re not changing in any meaningful way.”
If you determine that DevOps is the right approach, start asking some questions about your system and identifying your pain points. You might think about:
- What are you trying to accomplish?
- What are the stages in your current software development life cycle? Who is responsible for each stage?
- In what ways does your production process help you achieve your goals? In what ways does it prevent you from accomplishing them?
- What barriers to productivity are you facing?
- In an ideal world, what would your software development life cycle look like?
Understanding what is and isn’t working in your current system will help you define your DevOps goals and guide your implementation process.
Pick One Project
The easiest way to begin implementing DevOps is to start small—pick one project or one development sub-team to start experimenting with DevOps processes. “Starting with just one project allows you to get a feel for DevOps and gradually scale it up,” says Greg Jacoby.
And don’t rush to buy a bunch of shiny new tools—at least not yet. Give yourself a chance to experiment using the tools you have. This will allow you to identify any gaps and prioritize purchasing software that you’ll use. You can also try out open-source or freemium software to test what works well for your team before committing to any purchases.
DevOps is, most importantly, a mindset change, so the most important thing is to start thinking as one team. Define common goals and encourage everyone to be open to new responsibilities and ongoing learning as you begin your experiment.
Visualize Your Team’s Work
To improve your workflow, you first need to understand it. You can do this by visualizing your projects—identifying the stages in your software development life cycle and observing work as it flows through them.
Here’s where you should consider investing in a project management tool if you’re not using one already. If your project is small, you might be able to get away with sticky notes or colored index cards on a wall, but this only works well if your team all work from the same location. At best, it’s a temporary solution that won’t be able to scale. Project management tools like Backlog enable you to track project progress, log issues, and perhaps most importantly, visualize your team’s work through Kanban boards, Gantt charts, and burn-down charts. (And did we mention that you can get started with Backlog for free?)
Remove Constraints and Bottlenecks
Once you’ve logged and visualized your projects, take some time to observe your progress. After you’ve collected a few weeks’ worth of data, you can begin to think critically about your process: Where is work being held up? What is causing these bottlenecks? What actions might you be able to take to minimize them?
One frequent cause of bottlenecks? A lack of slack time. People might think they’re working at their most productive when they’re constantly preoccupied with projects because they feel busy, but that’s not true. Staff who are too busy cause slowdowns because they aren’t ready to start completing new work when it’s handed off to them. If your team faces frequent bottlenecks, identify where these constraints are happening and think about how you can build in more time between handoffs.
Standardize and Automate
Another way to improve flow, increase cycle speed, and reduce error is to standardize and automate recurring tasks. This is particularly important because, as Netflix notes, “Ownership of the full development life cycle adds significantly to what software developers are expected to do. Tooling that simplifies and automates common development needs helps to balance this out.”
Remember the “pets” vs. “cattle” server models? One big advantage of treating your servers like cattle is that the process of configuring new ones is easy and repeatable. People who played no role in setting the initial server up can look at the code to understand what the infrastructure does. If errors occur, they are consistent across all devices, instead of unique to a particular machine—making them easier to fix.
Think about other recurring tasks that you can automate. You should try to script repetitive tasks wherever possible to free up your engineers to solve more complex problems.
Keep Learning
DevOps is iterative. The goal is to work in short cycles so you can get feedback quickly and continuously improve not only your product but also your process. The longer you do DevOps, the smoother your process becomes.
Push yourself to keep learning new skills. Never used a scripting language before? Now is a great time to learn. “Even if you don’t need it to do your job, knowing a scripting language can help you with so many small tasks,” says John Debs. And that doesn’t just apply to scripting—stay open-minded and make ongoing learning an integral part of your DevOps practice.
Possible DevOps Pitfalls
Even though the results are worth it, the path to DevOps isn’t always smooth. Here are some of the most common challenges that teams implementing DevOps face and some thoughts on how to fix them.
1. Reluctance to Change
Developers can sometimes be a little territorial—having to share responsibilities that were previously their domain alone can take some getting used to.
The Fix: Emphasize knowledge sharing. The more everyone learns together, the easier collaboration becomes.
2. The Wrong Tools
“Having the right toolset is important,” says Gaurav Murghai. “It drives the team’s enthusiasm and willingness.” The tools you think will work at the beginning of your DevOps journey might not be the best fit for your team—and that’s okay. It’s all part of the process of learning and improving.
The Fix: Take note of your pain points. What is your team finding frustrating about your current tools? Look for software that fills those gaps and take time to evaluate which solution(s) fit your needs best—not which one is cheapest or flashiest.
3. Technical Debt
It can be so tempting to make a quick, easy fix and tell yourself you’ll go back to it later. But this is contrary to the ethos of DevOps—all it ends up doing is piling up more work for yourself and slowing down processes in the future.
The Fix: As good as your intentions might be, you have to be realistic. “You’re never going to have time to go back and fix it later,” says Daphne Reed. “Do it right the first time.”
4. Cost
DevOps makes it extremely easy to harness more computing power in seconds. But this might mean that you spend more on server space than you intend—or have budget for. Even though these are virtual machines, they still cost real money.
The Fix: Keep a careful eye on your server costs to avoid unexpectedly high bills for your provider.
Conclusion
“People don’t want to give up what makes them valuable,” says John Debs. Remember the systems administrator from the introduction? He wasn’t patching machines individually because he wanted to—he was reluctant to give up the very quality that made him valuable to the company.
DevOps may provide the solution: While the role of the traditional systems administrator has all but faded away, many former sysadmins have moved into development roles, adopting new skills while sharing their operations expertise. DevOps practices promote knowledge sharing, so the whole engineering team becomes more valuable over time. That’s a win for everyone.
Ready to start implementing DevOps?
Get started with Backlog, the all-in-one project management app for task management, bug tracking, and version control. Effortlessly collaborate with Documents to capture your project details, custom fields to personalize your workflow, and file sharing. Backlog’s built-in Gantt charts, burndown charts, and Kanban-style boards make it easy to visualize your project progress, allowing you to quickly identify constraints and optimize your workflow. Deploying small, frequent changes is simple, too—Backlog is fully integrated with Git and SVN so you can manage source code right next to your projects. With mobile apps for iOS and Android, you’ll never be out of the loop, even when you’re on the go. Try it for free.
Further Reading & Recommended Resources:
- The Phoenix Project by Kevin Behr, George Spafford, and Gene KimA novel about DevOps—a fun and engaging read which breaks down complex ideas into processes that non-developers can easily understand. A great one to share with managers and executives to help them understand what DevOps does for the business.
- The DevOps Handbook by John Willis, Patrick Debois, Jez Humble, and Gene KimA step-by-step guide to using DevOps practices to improve business outcomes.
- Full Cycle Developers at Netflix—Operate What You Build Netflix describes their journey from a waterfall development model to DevOps.
- Site Reliability Engineering by GoogleGoogle created the role of Site Reliability Engineer, so there’s no one better to explain it. In this guide, Google SREs discuss how they build, deploy, monitor, and maintain some of the world’s largest software systems by engaging with the entire software development life cycle.
- The 2019 Accelerate State of DevOps: Elite performance, productivity, and scaling by Nicole Forsgren, Research and Strategy, Google Cloud
A comprehensive overview of today’s DevOps landscape, with actionable advice for companies across a wide range of industries.
Thanks to interviewees John Debs, Daphne Reed, Greg Jacoby, and Gaurav Murghai who graciously shared their DevOps expertise for this project.

